






m6A-NeuralTool: Convolution Neural Tool for RNA N6-Methyladenosine Site Identificationin Different Species
作者:
MOBEEN UR REHMAN, KIM JEE HONG, HILAL TAYARA,
AND KIL TO CHONG
目的:
对于N6-甲基腺苷(m6A)在RNA中甲基化修饰的一个预测。
结果:
作者提出了一个m6A-NeuralTool的计算工具,该工具使用了多个子架构,并有效的识别了RNA-m6A修饰。该模型使用10倍交叉验证对四种不同的物种进行评估,与现有最先进模型相比,其模型对所有物种数据集都有很大的进步。最后作者提供了相应网站便于大家访问,该网站提供数据集的下载及预测:http://nsclbio.jbnu.ac.kr/tools/m6A-NeuralTool/.
数据集介绍
模型框架
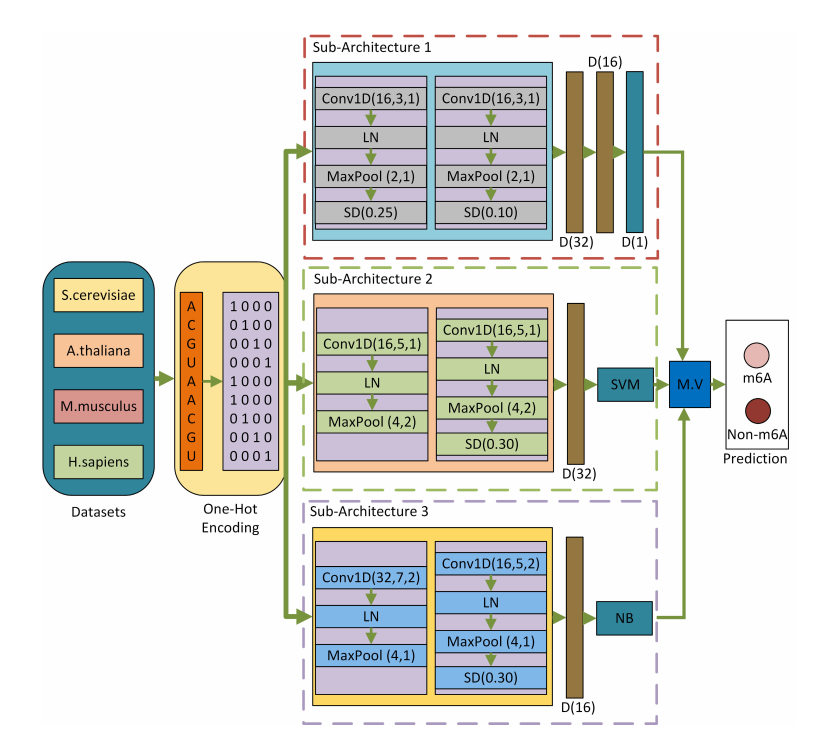
== Convolution 1 Dimension (Conv1D), Layer Normalization (LN), MaxPool (Max Pooling), Spatial
Dropout (SD), Dense (D), Conv1d (number of filters, size of filters, stride length), MaxPool (pool size, stride length), SD (ratio of features discarded),
Support Vector Machine (SVM), Naive Bayes (NB), Majority Voting (M.V). ==
* 由三个子结构构成,并且是训练时是分别单独训练的,也就是三个子模型的输出并不是作为特征提取的作用,而是为最终投票而计算应用得其结果 *
其中三个子结构前部分结构一致,只是卷积核大小不同。
实验结果:
该实验结果为十倍交叉验证结果
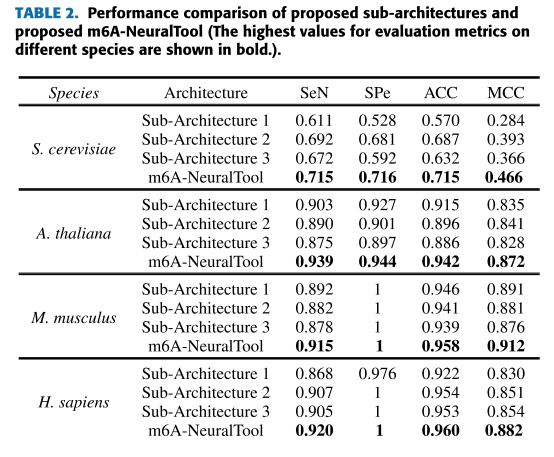
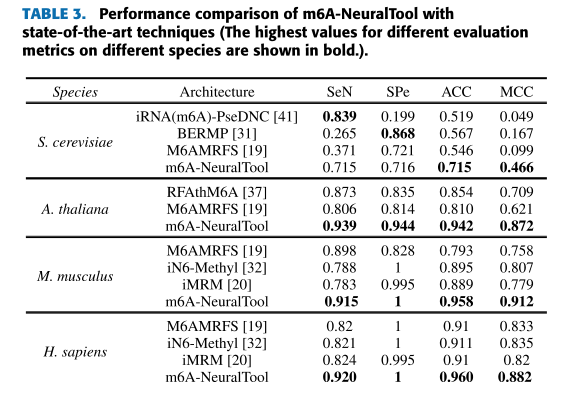
== 验证模型的泛化能 ==
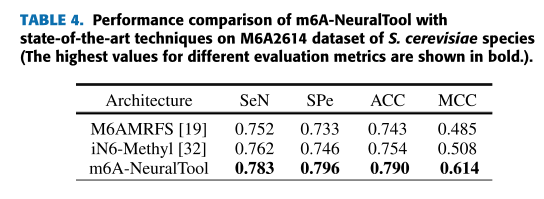
研究人员找到酿酒酵母的另一个数据集,命名为 M6A2614,作为独立数据集用来研究所提出的模型。该数据集中 1307个正样本,1307个负样本。我们使用M6A6540dataset of S. cerevisiae (benchmark dataset)作为模型训练,然后测试泛化能力,实验结果如下:















 406
406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









