







<训练中文LLama2(一)>训练一个中文LLama2的步骤_llama2训练自己的模型
<训练中文LLama2(二)>扩充LLama2词表构建中文tokenization_llama2 tokenizer
<训练中文LLama2(三)>对LLama2进行中文预料预训练_llama 预训练
<训练中文LLama2(四)方式一>对LLama2进行SFT微调_llama2扩展词表,sft
<训练中文LLama2(四)方式二>对LLama2进行SFT微调_llama sft 代码
<训练中文LLama2(五)>对SFT后的LLama2进行DPO训练_dpo微调和ppo
使用SentencePiece的除了从0开始训练大模型的土豪和大公司外,大部分应该都是使用其为当前开源的大模型扩充词表,比如为LLama扩充通用中文词表(通用中文词表,或者 垂直领域词表)。
- LLaMA 原生tokenizer词表中仅包含少量中文字符,在对中文字进行tokenzation时,一个中文汉字往往被切分成多个token(2-3个Token才能组合成一个汉字),显著降低编解码的效率。
- 预训练中没有出现过或者出现得很少的语言学习得不充分。
为了解决这些问题,我们可能就需要进行中文词表扩展。比如:在中文语料库上训练一个中文tokenizer模型,然后将中文 tokenizer 与 LLaMA 原生的 tokenizer 进行合并,通过组合它们的词汇表,最终获得一个合并后的 tokenizer 模型。
那这部分工作有没有意义呢?
1.提高模型的编解码的效率,在LLaMa原来的词表上,一个汉字平均1.45个token,扩充后的Chinese-LLaMa为0.65个token;那在垂直领域内呢?比如在LLaMa在继续扩充领域内词表,金融或者医疗等等,把“负债表”,“糖尿病”等领域词汇也加入词表里,那更加能提高其编解码的效率。
2.提高模型的上下文窗口长度,原LLaMa上下文长度是4096个token,不扩充词表前,按1.45来算就是最多只能输入2824个汉字,扩充后以0.65来算的话就是6301,垂直领域会更大。这点带来的好处是实打实的。
3.提高模型的效果?提高LLaMa在中文的表现?提高开源模型在垂直领域的表现?这一点上难以下结论,目前好像也没有确定的结论,自我感觉会有,但是不多,而且可能在垂直领域扩充词表后,垂直领域词太多过拟合影响通用领域效果,还有就是扩充完词表后还要经过一系列的后续处理和训练,可以控制变量的研究一下,但需要很多的资源哈哈。但是前两点的好处是实打实的,所以在有资源的情况下,扩充词表还是可以尝试的。
目前,大语言模型呈爆发式的增长,其中,基于llama家族的模型占据了半壁江山。而原始的llama模型对中文的支持不太友好,接下来本文将讲解如何去扩充vocab里面的词以对中文进行token化。
第一阶段的主要工作是通过扩展词表和 embedding 来提升 llama2 的中文能力。今天的工作是获得一个中文的bpe分词模型。
BPE模型对后期的 token 长度、token效果影响较大,而且我们希望训练的 llama2 模型具有通用价值,所以训练的数据应该尽可能多样。
- liwu/MNBVC · Datasets at Hugging Face 是一个不错的数据集,多样性丰富。
- https://github.com/aceimnorstuvwxz/toutiao-text-classfication-dataset 今日头条短文本
- GitHub - shjwudp/shu: 中文书籍收录整理, Collection of Chinese Books 一些中文书籍
- 维基百科
可以加入更多的数据
数据预处理
对斗破苍穹语料进行预处理,每一行为一句或多句话。
with open("data/《斗破苍穹》.txt", "r", encoding="utf-8") as fp:
data = fp.read().strip().split("\n")
sentences = []
for d in data:
d = d.strip()
if "===" in d or len(d) == 0 or d == "《斗破苍穹》来自:":
continue
sentences.append(d)
with open("data/corpus.txt", "w", encoding="utf-8") as fp:
fp.write("\n".join(sentences))
最终得到corpus.txt。
训练一个sentencepiece模型
SentencePiece 简介
SentencePiece 是一种无监督的文本 tokenizer 和 detokenizer,主要用于基于神经网络的文本生成系统,其中,词汇量在神经网络模型训练之前就已经预先确定了。 SentencePiece 实现了subword单元(例如,字节对编码 (BPE))和 unigram 语言模型),并可以直接从原始句子训练字词模型(subword model)。 这使得我们可以制作一个不依赖于特定语言的预处理和后处理的纯粹的端到端系统。
首先,我们需要去构建中文的词库。一般的,目前比较主流的是使用sentencepiece训练中文词库。安装指令也很简单:pip install sentencepiece。
安装完成后,我们开始使用,第一步是训练词表,用起来很简单,源码安装的方式直接命令行执行
spm_train --input=<input> --model_prefix=<model_name> --vocab_size=8000 --character_coverage=1.0 --model_type=<type>python的方式则是:
import sentencepiece as spm
spm.SentencePieceTrainer.train(input=<input>, model_prefix=<model_name>, vocab_size=8000, character_coverage=1.0, model_type=<type>)不过上述方式都建议写一个sh脚本,通过nohup或者screen放在后台执行,使用起来是很简单,但是这个训练的参数有接近40个,本着使用一个工具就尽量研究明白的态度,把主要的参数都进行了解释和一些不确定的参数用途的进行了实验。
1. input
指定训练语料文件,支持两种格式.txt和.tsv(以制表符(Tab)作为分隔符的文件,类似于.csv文件),也可以传递以逗号分隔的文件列表。.txt文件内格式为每一行作为一个句子(sentences)。默认为""
--input "/path/data1.txt"
--input ["/path/data1.txt", "path/data2.txt"]一般大规模训练时,我们会有几十个文件,在一个文件夹下,这时候我们可以通过sh脚本:
files="/path/train_vocab/*" # 你的训练文件夹地址
file_list=$(echo $files | tr ' ' ',')
nohup spm_train --input $file_list
#...其他参数2.input_format
指定输入文件的格式,支持的格式有两种:text对应.txt;tsv对应.tsv。默认为""
3.model_prefix
指定模型的输出前缀名,模型训练完成后,将使用这个前缀名来保存模型和词表文件。默认为""
4.model_type
指定模型的分词算法,支持的选项有 unigram、bpe、word和char。之前的文章已经介绍过这些分词算法,强烈建议看一下!默认为"unigram"
5.vocab_size
指定词表大小,默认为8000
6.accept_language
指定模型所支持的语言列表,多个语言可以用逗号分隔,语言代码是 ISO 639 标准定义的缩写,这个参数就是帮助模型识别语言,不设置也是可以的,默认为""
--accept_language "en,zh"7.character_coverage
指定模型的字符覆盖率,较高的覆盖率可以使模型包含更多字符。对于字符集丰富的语言(如日语或中文)推荐的默认值为 0.9995,对于其他字符集较小的语言推荐默认值为 1.0。默认值为0.9995,如果词表比较大,或者说扩充的词表比较大,可以适当调大该参数。
8.max_sentence_length
指定输入句子的最大长度,是以字节为单位的,默认为4192,UTF-8中一个汉字3个字节,大概就是.txt一行最多1397个汉字。
9.split_digits
指定是否将所有数字字符拆分为单独的单元,就是将”2023“拆成”2“,”0“,”2“,”3“这种独立的子词单元,好处是减少词表的数字量,所有数字都能表示,坏处是token数量会变多,一个”2023“就是4个token,默认是False,LLaMa是True
10.byte_fallback
这个参数是比较重要的,用于指定在遇到未知或很少的字符时将其分解为 UTF-8 字节来表示,这个参数打开了BPE实现的效果就和BBPE是一样的了(还是建议看一下上一篇文章),比如”魑魅魍魉“,假如在我们训练语料中出现的次数太少,我们最后的词表里没有这个词,如果不开启这个参数就会OOV,如果开启了,这个词就会被用UTF-8的编码来分词即:”0xE9 0xAD 0x91 0xE9 0xAD 0x85 0xE9 0xAD 0x8D 0xE9 0xAD 0x89“,就可以被分词,分成12个token。默认为False。
然后,我们准备好语料,这里我们使用的语料是斗破苍穹小说。直接看代码:
import sentencepiece as spm
spm.SentencePieceTrainer.train(
input='data/corpus.txt',
model_prefix='tokenizer',
vocab_size=30000,
user_defined_symbols=['foo', 'bar'],
character_coverage=1.0,
model_type="bpe",
)
这里讲下每个参数的作用:
- input:指定输入文本文件的路径或者是一个目录,可以指定多个输入文件或目录。其中每一行可以是一句话或者多句话。
- tokenizer:保存的模型的名称前缀。
- vocab_size:设置的词表大小。
- user_defined_symbols:用于指定用户自定义的符号。这些符号将会被视为单独的 Token,不会被拆分成子词。这个参数的作用是将一些用户定义的特殊符号作为一个整体加入到生成的词表中,以便于后续的模型使用。这里我们简单进行了测试。
- model_type: 指定模型的类型,有三种可选参数:unigram, bpe, char. word。
- character_coverage指定覆盖字符的数量,可以理解为限制字符集的大小。默认值为 1.0,即覆盖全部字符。
- unk_id: 指定未登录词的 ID 号,即在词表中为未登录词分配一个整数 ID。默认值为 0。
- bos_id: 指定句子开头符号的 ID 号,即在词表中为句子开头符号分配一个整数 ID。默认值为 1。
- eos_id: 指定句子结束符号的 ID 号,即在词表中为句子结束符号分配一个整数 ID。默认值为 2。
- pad_id: 指定填充符号的 ID 号,即在词表中为填充符号分配一个整数 ID。默认值为 -1,即不使用填充符号。
运行后会得到tokenizer.model和tokenizer.vocab两个文件。

我们来看看tokenizer.vocab里面是什么:
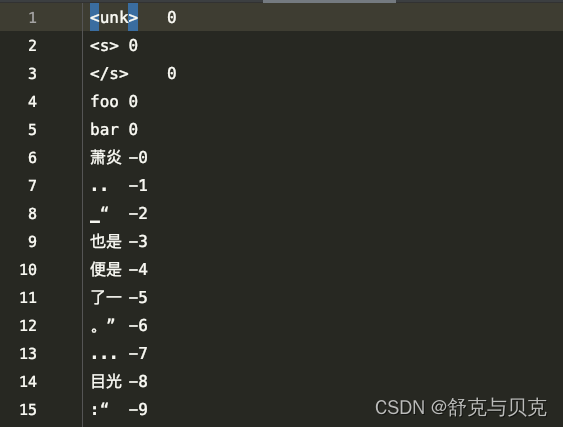
除了一些特殊符号外,还有我们自定义的foo和bar,其余的一些词是BPE训练得到,具体什么是BPE算法这里不作展开了。
合并LLama2词表和中文词表
import os
os.environ["PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION"] = "python"
from transformers import LlamaTokenizer
from sentencepiece import sentencepiece_model_pb2 as sp_pb2_model
import sentencepiece as spm
llama2_tokenizer_dir = "llama2_tokenizer/tokenizer.model"
llama2_tokenizer = LlamaTokenizer.from_pretrained(llama2_tokenizer_dir)
chinese_sp_model = spm.SentencePieceProcessor()
chinese_sp_model_file = "tokenizer.model"
chinese_sp_model.Load(chinese_sp_model_file)
llama2_spm = sp_pb2_model.ModelProto()
llama2_spm.ParseFromString(llama2_tokenizer.sp_model.serialized_model_proto())
chinese_spm = sp_pb2_model.ModelProto()
chinese_spm.ParseFromString(chinese_sp_model.serialized_model_proto())
# print number of tokens
print(len(llama2_tokenizer), len(chinese_sp_model))
print(llama2_tokenizer.all_special_tokens)
print(llama2_tokenizer.all_special_ids)
print(llama2_tokenizer.special_tokens_map)
## Add Chinese tokens to LLaMA2 tokenizer
llama_spm_tokens_set = set(p.piece for p in llama2_spm.pieces)
print(len(llama_spm_tokens_set))
print(f"Before:{len(llama_spm_tokens_set)}")
for p in chinese_spm.pieces:
piece = p.piece
if piece not in llama_spm_tokens_set:
new_p = sp_pb2_model.ModelProto().SentencePiece()
new_p.piece = piece
new_p.score = 0
llama2_spm.pieces.append(new_p)
print(f"New model pieces: {len(llama2_spm.pieces)}")
## Save
output_sp_dir = 'llama2_chinese'
os.makedirs(output_sp_dir, exist_ok=True)
with open(output_sp_dir + '/chinese_llama2.model', 'wb') as f:
f.write(llama2_spm.SerializeToString())
tokenizer = LlamaTokenizer(vocab_file=output_sp_dir + '/chinese_llama2.model')
output_hf_dir = 'llama2_chinese' #
os.makedirs(output_hf_dir, exist_ok=True)
tokenizer.save_pretrained(output_hf_dir)
print(f"Chinese-LLaMA tokenizer has been saved to {output_hf_dir}")
# Test
llama_tokenizer = LlamaTokenizer.from_pretrained(llama2_tokenizer_dir)
chinese_llama_tokenizer = LlamaTokenizer.from_pretrained(output_hf_dir)
print(tokenizer.all_special_tokens)
print(tokenizer.all_special_ids)
print(tokenizer.special_tokens_map)
text = '''白日依山尽,黄河入海流。欲穷千里目,更上一层楼。
The primary use of LLaMA is research on large language models, including'''
print("Test text:\n", text)
print(f"Tokenized by LLaMA tokenizer:{llama_tokenizer.tokenize(text)}")
print(f"Tokenized by ChatGLM tokenizer:{chinese_llama_tokenizer.tokenize(text)}")
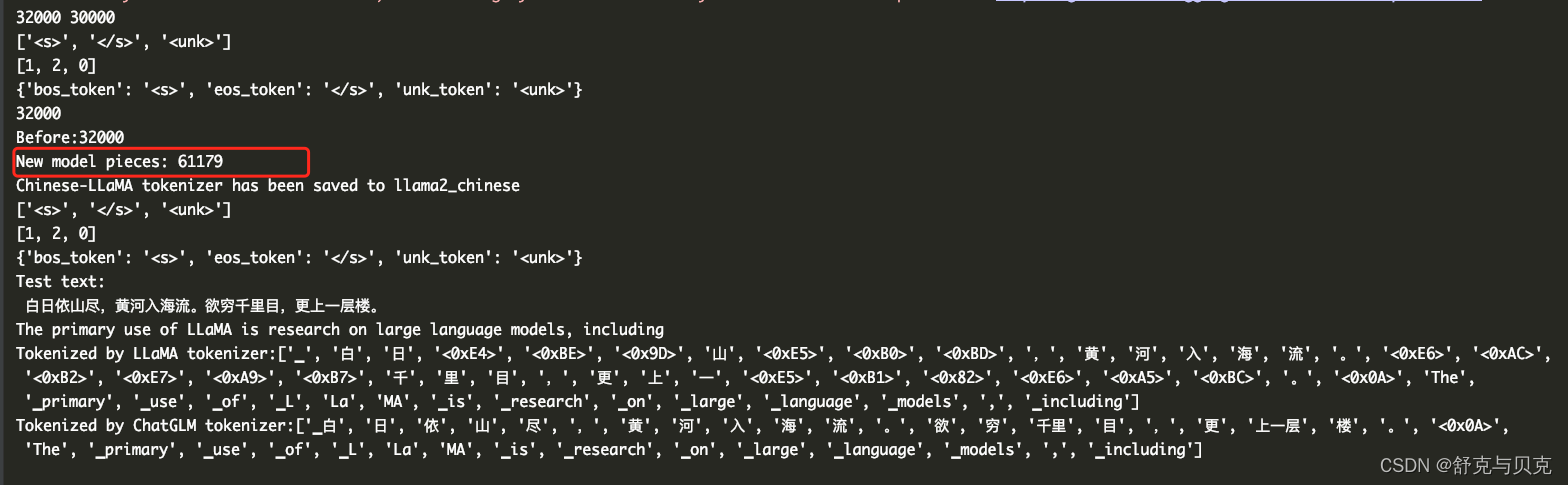
加入了我们定义的词表后确实能够正确的对中文进行分词了
核心部分是这一块:
for p in chinese_spm.pieces:
piece = p.piece
if piece not in llama_spm_tokens_set:
new_p = sp_pb2_model.ModelProto().SentencePiece()
new_p.piece = piece
new_p.score = 0
llama_spm.pieces.append(new_p)
也就是将原始词表中没有的新加入进去。
怎么使用修改后的词表
如果我们重新从头开始训练,那么其实使用起来很简单:
config = AutoConfig.from_pretrained(...)
tokenizer = LlamaTokenizer.from_pretrained(...)
model = LlamaForCausalLM.from_pretrained(..., config=config)
model_vocab_size = model.get_output_embeddings().weight.size(0)
model.resize_token_embeddings(len(tokenizer))
但是如果我们想要保留原始模型embedding的参数,那么我们可以这么做:
- 1、找到新词表和旧词表id之间的映射关系。
- 2、将模型里面新词表里面包含的旧词表用原始模型的embedding替换。
- 3、如果新词在旧词表里面没有出现就进行相应的初始化再进行赋值。比如transformers库中的llama是这么进行初始化的:
def _init_weights(self, module):
std = self.config.initializer_range
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=std)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=std)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
具体怎么做可以参考一下这个:https://github.com/yangjianxin1/LLMPruner
参考
https://github.com/ymcui/Chinese-LLaMA-Alpaca
https://github.com/yangjianxin1/LLMPruner
https://github.com/huggingface/transformers
LLM大模型之基于SentencePiece扩充LLaMa中文词表实践 - 知乎 (zhihu.com)















 66
66











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









