







很多算法工程师戏谑自己是调参工程师,因为他们需要在繁杂的算法参数中找到最优的组合,往往在调参的过程中痛苦而漫长的度过一天。如果有一种方式可以帮助工程师找到最优的参数组合,那一定大有裨益,贝叶斯超参优化就是其中的一种。如果是单单罗列公式,可能会显得乏味,就用一些思考带上公式为大家分享。
目前在研究Automated Machine Learning, 其中有一个子领域是实现网络超参数自动化搜索,而常见的搜索方法有Grid Search、Random Search以及贝叶斯优化搜索。前两者很好理解,这里不会详细介绍。
我们希望找到最佳的超参数配置,帮助我们在验证/测试集的关键度量上得到最佳分数。
在计算力、金钱和时间资源有限的情况下,每个科学家和研究员都希望获得最佳模型。但是我们缺少有效的超参数搜索来实现这一目标。
一 参数和超参数有什么区别?
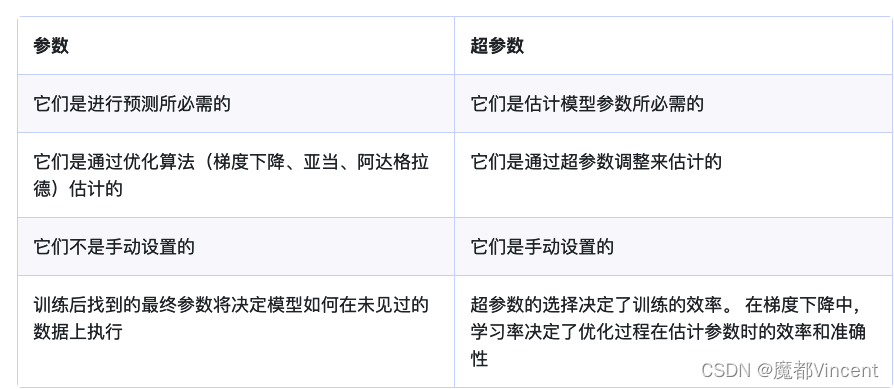
模型参数 :这些是模型根据给定数据估计的参数。 例如深度神经网络的权重。
模型超参数 :这些是模型无法根据给定数据估计的参数。 这些参数用于估计模型参数。 例如,深度神经网络中的学习率
二 什么是超参数调优,为什么它很重要?
调整 (或超参数优化)是确定使模型性能最大化的超参数的正确组合的过程。 它通过在单个训练过程中运行多个试验来工作。 每个试验都是您的训练应用程序的完整执行,其中您选择的超参数的值设置在您指定的限制内。 此过程完成后将为您提供一组最适合模型以提供最佳结果的超参数值。
不用说,这是任何机器学习项目中的重要一步,因为它可以为模型带来最佳结果。 如果您希望看到它的实际效果, 这里有一篇研究论文 ,通过对数据集进行实验来讨论超参数优化的重要性。
三 如何进行超参数调优? 如何找到最佳超参数?
选择正确的超参数组合需要了解超参数和业务用例。 但是,从技术上讲,有两种方法可以设置它们。
A 手动超参数调优
手动超参数调整涉及手动试验不同的超参数集,即每个超参数集的试验将由您执行。 这项技术将需要一个强大的实验跟踪器,它可以跟踪从图像、日志到系统指标的各种变量。
有一些实验跟踪器可以勾选所有框。 海王星就是其中之一。 它提供了一个直观的 UI 和一个开源包 neptune-client,以方便您登录您的代码。 您可以轻松记录超参数并查看所有类型的数据结果,例如图像、指标等。前往文档了解如何将 不同的元数据记录到 Neptune 。
替代解决方案包括 W&B、Comet 或 MLflow。 查看更多 用于实验跟踪和管理的工具 。
手动超参数优化的优点 :
- 手动调整超参数意味着对过程的更多控制。
- 如果您正在研究或研究调整以及它如何影响网络权重,那么手动进行调整是有意义的。
手动超参数 优化 :
- 手动调整是一个乏味的过程,因为可能会进行许多试验,并且跟踪可能会被证明是昂贵且耗时的。
- 当需要考虑很多超参数时,这不是一个非常实用的方法。
阅读有关 如何手动优化机器学习模型超参数的信息 。
B. 自动超参数调优
自动超参数调整利用现有算法来自动化该过程。 您遵循的步骤是:
- 首先,指定一组超参数和对这些超参数值的限制(注意:每个算法都要求该组是一个特定的数据结构,例如字典在使用算法时很常见)。
- 然后算法为您完成繁重的工作。 它会运行这些试验并为您获取能够提供最佳结果的最佳超参数集。
在博客中,我们将讨论一些可用于实现自动调优的算法和工具。 让我们开始吧。
四 超参数调优方法
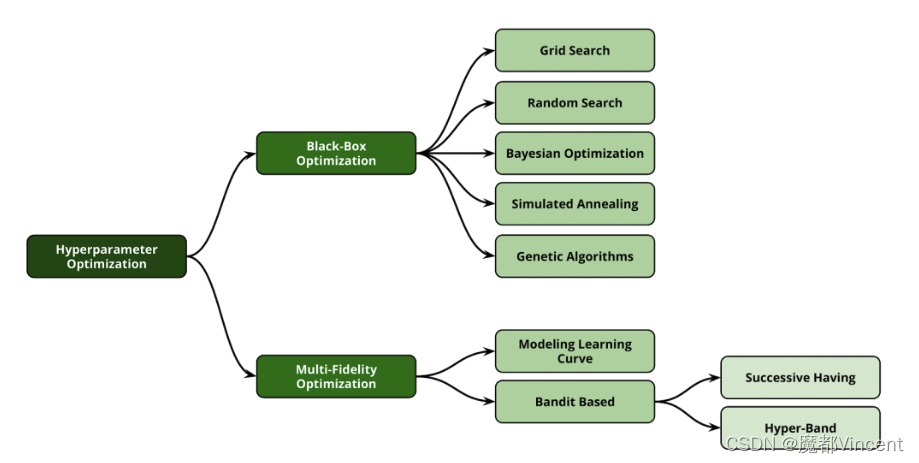
Grid Search & Random Search
我们都知道神经网络训练是由许多超参数决定的,例如网络深度,学习率,卷积核大小等等。所以为了找到一个最好的超参数组合,最直观的的想法就是Grid Search,其实也就是穷举搜索,示意图如下。
在 随机搜索方法 中,我们为超参数创建了一个可能值的网格。 每次迭代都会尝试来自该网格的超参数的随机组合,记录性能,最后返回提供最佳性能的超参数组合。
在 网格搜索方法 中,我们为超参数创建一个可能值的网格。 每次迭代都以特定顺序尝试超参数的组合。 它在每个可能的超参数组合上拟合模型并记录模型性能。 最后,它返回具有最佳超参数的最佳模型。
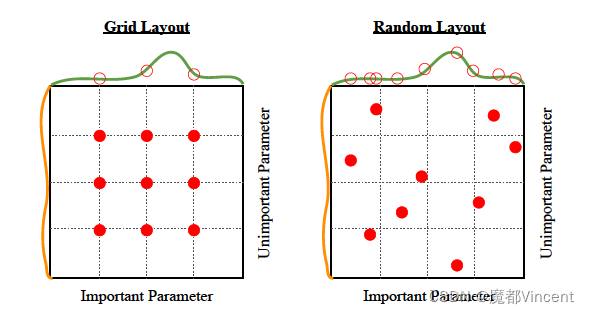
但是我们都知道机器学习训练模型是一个非常耗时的过程,而且现如今随着网络越来越复杂,超参数也越来越多,以如今计算力而言要想将每种可能的超参数组合都实验一遍(即Grid Search)明显不现实,所以一般就是事先限定若干种可能,但是这样搜索仍然不高效。
所以为了提高搜索效率,人们提出随机搜索,示意图如下。虽然随机搜索得到的结果互相之间差异较大,但是实验证明随机搜索的确比网格搜索效果要好。
五 贝叶斯优化
为什么贝叶斯优化有效?
随机搜索最终会收敛到最优答案,但这种方法就是这样的盲目搜索! 有没有更智能的搜索方式? 是的——贝叶斯优化,由 J.Močkus 。 找到有关 BO 的更多信息 贝叶斯优化入门 和 机器学习算法的实用贝叶斯优化中 。
本质上,贝叶斯优化是一种概率模型,它希望通过基于先前观察的学习来学习昂贵的目标函数。 它有两个强大的功能:代理模型和采集功能。
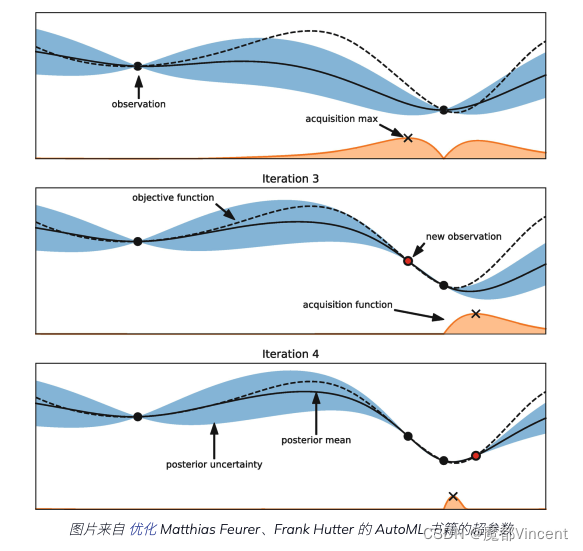
在上图中,您可以看到基于 自动机器学习 。 在这个图中,我们想要找到真实的目标函数,如虚线所示。 假设我们有一个连续的超参数,在第二次迭代中我们观察到两个黑点,然后我们拟合了一个代理模型(回归模型),即黑线。 黑线周围的蓝管是我们的不确定性。
我们还有一个采集功能,这是我们探索搜索空间以找到新的观察最优值的方式。 换句话说,获取函数帮助我们改进我们的代理模型并选择下一个值。 在上图中,采集函数显示为橙色曲线。 采集最大值意味着不确定性最大且预测值低。
1. 高斯过程
首先要知道什么是高斯过程,高斯过程也是正态分布,我们可以理解为一般世界的很多随机事件都是遵循这样的一个原则。比如买了1000次彩票,中奖的概率是多少,这就是一个典型的随机过程。比如在20楼向下扔皮球,砸中美女的概率也是一个随机过程。
在贝叶斯调参过程中,假设一组超参数组合是X=x1,x2,...,xn(xn表示某一个超参数的值),而这组超参数与最后我们需要优化的损失函数存在一个函数关系,最终的评估结果为Y,通过什么样的X可以取得最优的Y,我们假设是f(X), Y=F(X)
而目前机器学习其实是一个黑盒子(black box),即我们只知道input和output,所以上面的函数f(x)很难确定。所以我们需要将注意力转移到一个我们可以解决的函数上去.
于是可以假设这个寻找最优化参数的过程是一个高斯过程。高斯过程有个特点,就是当随机遍历一定的数据点并拿到结果之后,可以大致绘制出整个数据的分布曲线。
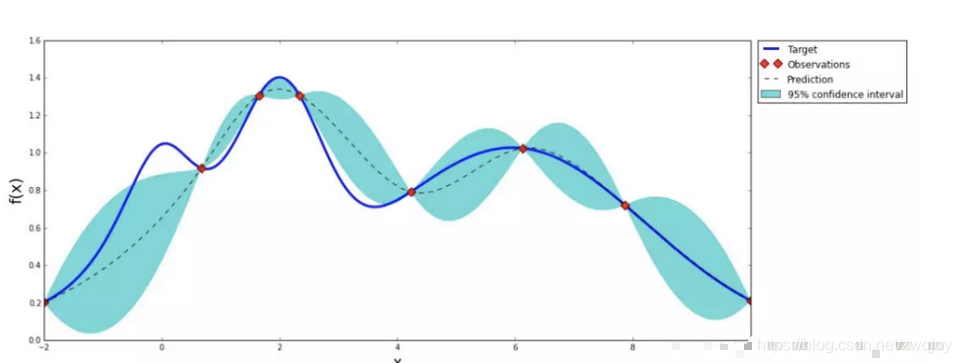
上图是一个高斯过程的图,就像人生的曲线,起起伏伏,命运造化弄人,需要不断地尝试才能知道最终的结果。所以如果要找到完整的人生的曲线,需要不停地在每一个单点尝试,直到真个曲线清晰。就知道做什么样的事情,可以到达高谷,好比在超参优化中就是什么样的参数可以得到好的结果。
贝叶斯优化的重要基础理论就是不断通过先验点去预测后验知识。
2. 贝叶斯优化理论
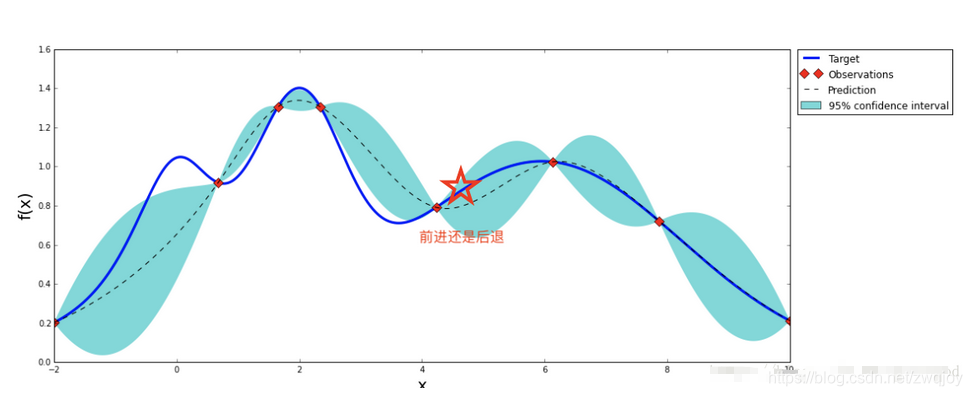
还是这张图,把横轴看作是参数组合X,纵轴看作是这个参数的结果Y。可以通过已经构建的曲线,找到曲线上升的方向,从而在这个方向上继续探索,这样就可以大概率拿到更好的结果。在生活的轨迹上,如果找到一条明确通往幸福的路,可以继续向前探索,因为大概率可以成功,但也许也有会错过更好的机会,陷入局部最优解。请看上图中的五角星,如果我们处于它的位置,继续向上走会迎来一个高峰,但是如果后退,在下降一段时间之后可能会迎来更高的波峰,你该如何选择。
于是,在参数的探索中要掌握一个平衡:
开发:在明确的曲线上扬方向继续走,大概率获得更好的结果,但是容易陷入局部最优。
探索:除了在曲线上扬的方向,在其它的区域也不忘寻找
总结一下,贝叶斯超参优化跟生活很像,面对顺境选择继续向前,还是勇敢的跳出现状寻找更大的突破,这需要一个策略,在调参中这个策略可以自己定义一些方法去实现。把参数组合对结果的影响看作是一个高斯过程,把开发和探索的策略作为一个自定义函数去权衡,这就是贝叶斯超参带给我们的启迪。
树结构 Parzen 估计器 (TPE)
为您的模型调整和找到正确的超参数是一个优化问题。 我们希望通过改变模型参数来最小化模型的损失函数。 贝叶斯优化帮助我们找到最小步数中的最小点。 贝叶斯优化 还使用了一种采集函数,该函数将采样引导到可能对当前最佳观察结果有所改进的区域。
TPE的思想 基于树的 Parzen 优化 类似于贝叶斯优化。 TPE 模型 P(x|y) 和 P(y) 不是找到 p(y|x) 的值,其中 y 是要最小化的函数(例如,验证损失),x 是超参数的值。 树结构 Parzen 估计器的一大缺点是它们不模拟超参数之间的交互。 也就是说,TPE 在实践中运行得非常好,并且在大多数领域都经过了实战考验。
Tools for hyperparameter optimization
- Scikit-learn
- Scikit-Optimize
- Optuna
- Hyperopt
- Ray.tune
- Talos
- BayesianOptimization
- Metric Optimization Engine (MOE)
- Spearmint
- GPyOpt
- SigOpt
- Fabolas
 https://neptune.ai/blog/hyperparameter-tuning-in-python-complete-guide
https://neptune.ai/blog/hyperparameter-tuning-in-python-complete-guide参考:

















 1383
1383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









