







谱聚类(Spectral Clustering)是一种基于图论的聚类方法,通过对数据点的相似度矩阵进行特征值分解,从而识别出数据中的簇结构。相比于传统的聚类方法,如K-means,谱聚类在处理非线性、复杂结构的数据集时表现尤为出色。
在本文中,我们将详细介绍如何使用Python实现谱聚类,包括以下几个步骤:
-
构建相似度矩阵: 我们首先需要计算数据点之间的相似度,可以使用高斯核函数或其他合适的相似度度量方法来构建相似度矩阵。
-
构造图拉普拉斯矩阵: 根据相似度矩阵,构造标准图拉普拉斯矩阵或归一化图拉普拉斯矩阵。图拉普拉斯矩阵是谱聚类的核心,反映了数据点之间的连接关系。
-
特征值分解: 对图拉普拉斯矩阵进行特征值分解,提取前k个最小的特征值对应的特征向量。这些特征向量构成了新的特征空间,其中数据点可以更清晰地分离。
-
应用聚类算法: 在特征向量构成的新特征空间中,应用K-means或其他聚类算法对数据点进行聚类。由于特征向量保留了数据点的簇结构,聚类效果会显著提升。
-
结果可视化: 最后,将聚类结果进行可视化展示,以便直观地理解和验证聚类效果。
结合本专栏的Kmeans一起使用。
# 文件功能:实现Spectral谱聚类算法
import numpy as np
import scipy
import pylab
import random,math
import matplotlib.pyplot as plt
from matplotlib.patches import Ellipse
from sklearn.neighbors import kneighbors_graph
import KMeans
class Spectral(object):
def __init__(self,n_clusters,n_neighbors = 10):
self.n_clusters_ = n_clusters # 数量
self.n_neighbors_ = n_neighbors # 近邻数
self.weight_ = None # 相似度矩阵
self.degree_ = None # 度矩阵
self.laplacians_ = None # 拉普拉斯矩阵
self.eigen_vector_ = None # 拉普拉斯矩阵的特征向量
def fit(self,data):
# step1 构造每个点的权矩阵
weight = kneighbors_graph(data,n_neighbors=self.n_neighbors_)
weight = 0.5 * (weight + weight.T)
self.weight_ = weight.toarray()
self.degree_ = np.diag(np.sum(self.weight_,axis=0).ravel())
# step2 对所有点构造拉普拉斯矩阵,并归一化
self.laplacians_ = self.degree_ - self.weight_
degree_nor=np.sqrt(np.linalg.inv(self.degree_))
self.laplacians_ = np.dot(degree_nor,self.laplacians_)
self.laplacians_ = np.dot(self.laplacians_,degree_nor) # 归一化
# step3 计算对应于特征向量最小k个特征值并归一化
eigen_values,eigen_vector = np.linalg.eigh(self.laplacians_)
sort_index = eigen_values.argsort()
eigen_vector = eigen_vector[:,sort_index]
self.eigen_vector_ = np.asarray([eigen_vector[:,i] for i in range(self.n_clusters_)]).T
self.eigen_vector_ /= np.linalg.norm(self.eigen_vector_,axis=1).reshape(data.shape[0],1)
# step4 kmeans和特征向量
spectral_kmeans = KMeans.K_Means(n_clusters=self.n_clusters_)
spectral_kmeans.fit(self.eigen_vector_)
spectral_label = spectral_kmeans.predict(self.eigen_vector_)
self.label_ = spectral_label
self.fitted = True
def predict(self, data):
result = []
if not self.fitted:
print('Unfitter. ')
return result
return np.copy(self.label_)
# 生成仿真数据
def generate_X(true_Mu,true_Var):
# 第一簇的数据
num1,mu1,var1 = 400,true_Mu[0],true_Var[0]
x1 = np.random.multivariate_normal(mu1,np.diag(var1),num1)
# 第二簇的数据
num2, mu2, var2 = 400, true_Mu[1], true_Var[1]
x2 = np.random.multivariate_normal(mu2, np.diag(var2), num2)
# 第三簇的数据
num3, mu3, var3 = 400, true_Mu[2], true_Var[2]
x3 = np.random.multivariate_normal(mu3, np.diag(var3), num3)
# 合并在一起
x = np.vstack((x1,x2,x3))
# 显示数据
plt.figure(figsize=(10,8))
plt.axis([-10,15,-5,15])
plt.title(u"scatter cluster before spectral")
plt.scatter(x1[:,0],x1[:,1],s=5,c='r')
plt.scatter(x2[:, 0], x2[:, 1], s=5, c='g')
plt.scatter(x3[:, 0], x3[:, 1], s=5, c='y')
plt.show()
return x
if __name__ == '__main__':
# 生成数据
true_Mu = [[0.5,0.5],[5.5,2.5],[1,7]] #生成均值
true_Var = [[1,3],[2,2],[6,2]]
X = generate_X(true_Mu,true_Var)
# 进行谱聚类
spectral = Spectral(n_clusters=3)
K = 3
spectral.fit(X)
cat = spectral.predict(X)
print(cat)
cluster = [[] for i in range(K)]
for i in range(len(X)):
if cat[i] == 0:
cluster[0].append(X[i])
elif cat[i] == 1:
cluster[1].append(X[i])
elif cat[i] == 2:
cluster[2].append(X[i])
clusters1 = np.asarray(cluster[0])
clusters2 = np.asarray(cluster[1])
clusters3 = np.asarray(cluster[2])
plt.figure(figsize=(10,8))
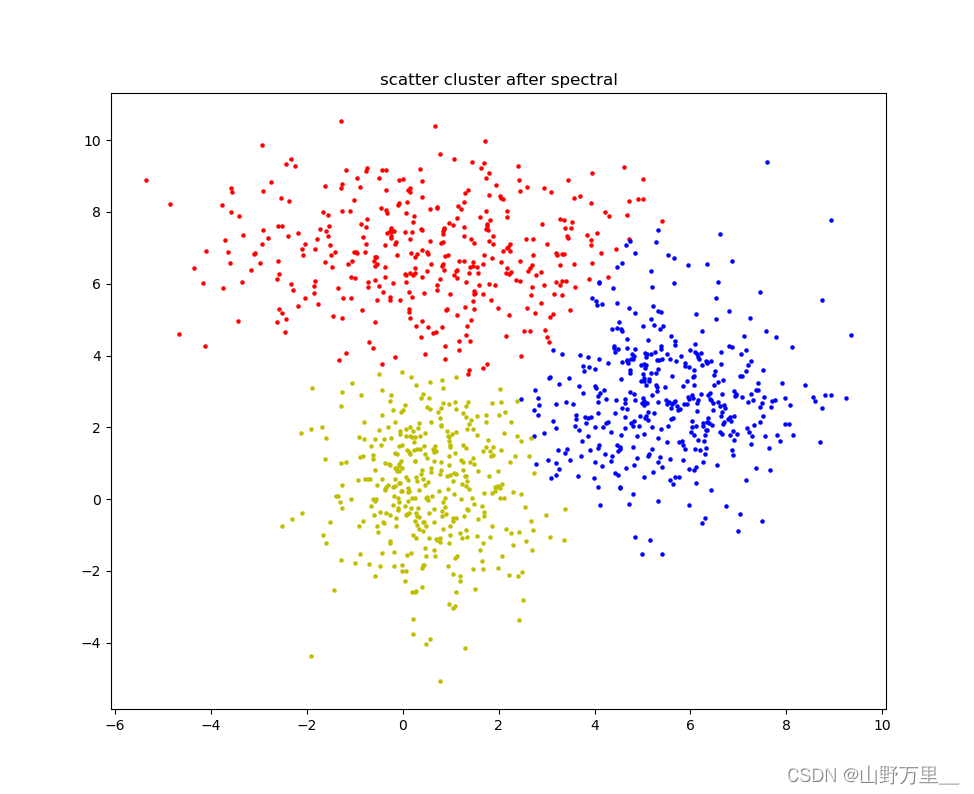
plt.title(u"scatter cluster after spectral")
plt.scatter(clusters1[:,0],clusters1[:,1],s=5,c="r")
plt.scatter(clusters2[:,0],clusters2[:,1],s=5,c="b")
plt.scatter(clusters3[:,0],clusters3[:,1],s=5,c="y")
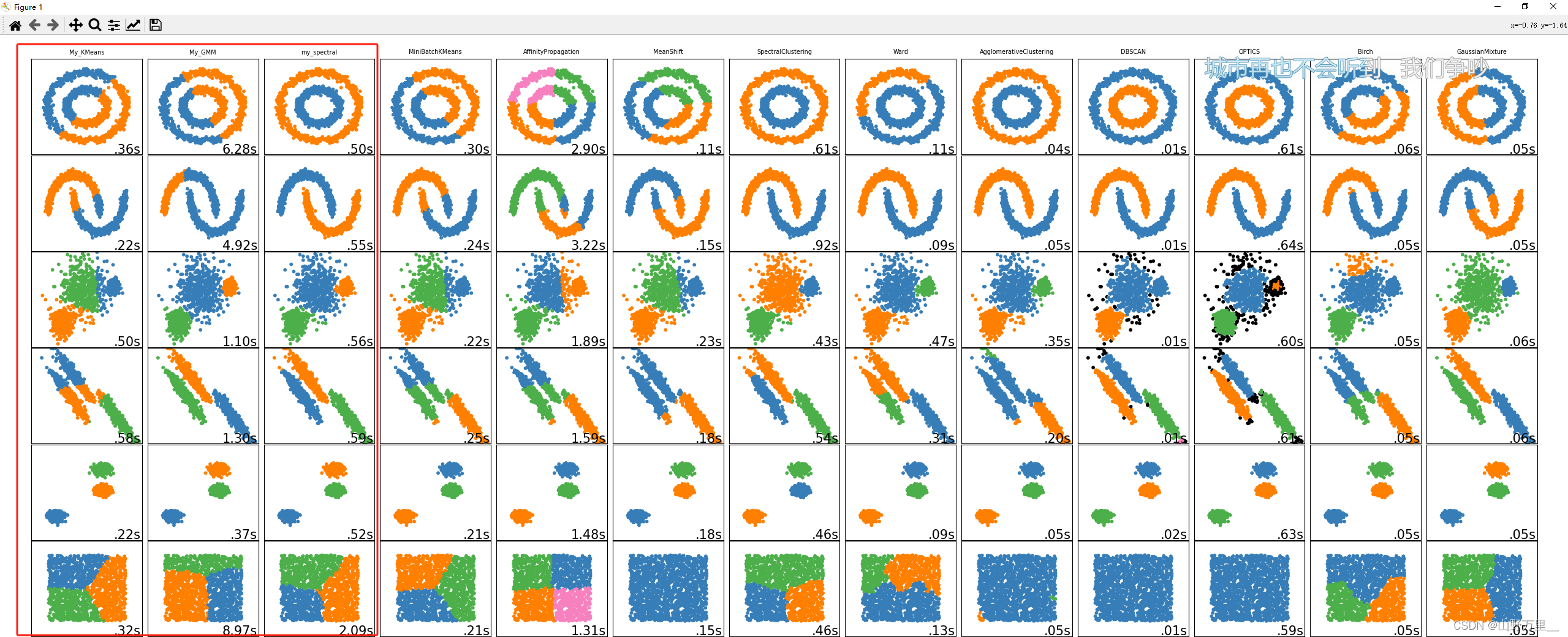
plt.show()对比一下,三个聚类的方法:















 2600
2600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









