







注:此文为阅读笔记,参考了很多论文,博客,如有侵权请联系,我附上原出处。
准备知识:
Backbone可以被称作主干特征提取网络,比如 Darknet53、CSPDarknet,输入的图片首先会在Backbone里面进行特征提取,提取到的特征可以被称作特征层,是输入图片的特征集合。在主干部分,可以获得一个或多个特征层进行下一步网络的构建,这些特征层我称它为有效特征层。
Neck可以被称作加强特征提取网络,比如 FPN,在主干部分获得的有效特征层会在这一部分进行特征融合,特征融合的目的是结合不同尺度的特征信息。。
Head是YOLO的分类器与回归器,通过Backbone和Neck,我们已经可以获得一个或多个加强过的有效特征层。每一个特征层都有宽、高和通道数,此时我们可以将特征图看作一个又一个特征点的集合,每一个特征点都有通道数个特征。YOLO Head实际上所做的工作就是对特征点进行判断,判断特征点是否有物体与其对应。一般来说,YOLO所用的解耦头是一起的,也就是分类和回归在一个1X1卷积里实现。
因此,整个YOLO网络所作的工作就是 特征提取-特征加强-预测特征点对应的物体情况。
YOLO V1
You Only Look Once:Unified, Real-Time Object Detection
![]()
这篇文章发表在CVPR 2016,来自华盛顿大学、艾伦人工智能研究院和FAIR,作者有Ross Girshick大神。此篇文章算是一阶段目标检测方法的开山之作,后续也产生了一系列工作。
下图来自:44 物体检测算法:R-CNN,SSD,YOLO【动手学深度学习v2】

创新点
目标检测问题
许多目标检测算法通常将此问题变成分类问题,之前的一些方法使用sliding window或者region proposal,这些方法通常在整个图像中选取一些子区域,对于这些子区域进行分类,上述方法比较慢、也比较难地去优化。
YOLO将目标检测问题转换为简单的回归问题,直接从像素回归得到bounding box坐标和分类概率。由于使用单个神经网络就能够实现,所以可以端到端地优化。
在整图上进行训练并且直接优化,具有以下好处:
1.非常快。把检测问题建模成一个回归问题就无需复杂的pipeline。每秒45帧(更快的版本每秒150帧)。
2.YOLO在预测时可以推理整张图片。也就是说,它能够在训练和预测阶段看到整幅图的信息,即包含类别及其外观的语义信息。这是和滑动窗方法不一样的地方。Fast RCNN会把背景误判为目标因为他不能看到大的场景信息。YOLO的background error比Fast RCNN少了一半。
3.YOLO能够学习到目标更加泛化的特征。当它被应用到新的场景或者输入不寻常的图像时,性能不会下降得很厉害。
grid cell

1.将图像resize到448 * 448作为神经网络的输入。
2.运行神经网络,得到一些bounding box坐标、box中包含物体的置信度和class probabilities。
3.进行非极大值抑制,筛选Boxes。

将一幅图像分成SxS个网格(grid cell),
如果某个object的中心 落在这个网格中,则这个网格就负责预测这个object。
每个网格预测出B个bounding boxes和分数(置信度)。
bounding boxes只预测框中有没有物体(confidence信息)
cell单元预测物体的类别( class信息)
置信度
定义置信度为:
![]()
当b-box包含目标时,Pr(Object)为1;不包含目标时,Pr(Object)为0.
如果包含目标,则置信度为预测的box和ground truth之间的IOU;若不包含这个目标,则置信度为0。
每个bounding box包含5个预测:x,y,w,h,confidence。
(x,y)是box的中心相对于网格的坐标。注意,(x,y)是相对于每个单元格左上角坐标点的偏移值,单位是相对于单元格的大小。而边界框的宽高也是相对于整张图片的宽高的比例。
这四个值的大小应该都在0-1之间,归一化更容易收敛。
每个网格cell也预测了C个条件类别概率,Pr(Classi|Object) .一个网格cell不论有多少个Bbox,都只预测一组(C个)条件类别概率。
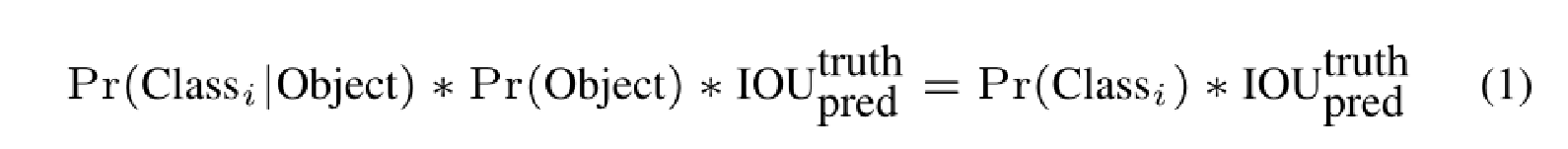
例子

![]()
S ×S grid and for each grid cell
predicts B bounding boxes,
confidence for those boxes,
x, y, w, h, and confidence
and C class probabilities
7×7大小的网格 、一个网格预测2个 bounding box、一共有20种类别
YOLO中,VOC数据集上使用S=7,B=2,C=20最后的预测是一个7×7×(2*5+20)的张量。
网络架构
YOLO V1的网络架构
Backbone
网络架构受到GoogLeNet图像分类模型的启发。 在ImageNet分类任务上 以一半的分辨率(224x224的输入图像)预训练卷积层,然后将分辨率加倍来进行检测。检测任务需要精细粒度的视觉信息,因此在检测的时候把网络的输入分辨率从224×224变成448×448。

网络的初始卷积层从图像中提取特征,而全连接层预测输出概率和坐标。
由图可见,其进行了二十多次卷积还有四次最大池化,其中3x3卷积用于提取特征,1x1卷积用于压缩特征,最后将图像压缩到7x7xfilter的大小,相当于将整个图像划分为7x7的网格,每个网格负责自己这一块区域的目标检测。
Neck
无
Head
FC-——》7x7x30
整个网络最后利用全连接层使其结果的size为(7x7x30),其中7x7代表的是7x7的网格,30前20个代表的是预测的种类,后10代表两个预测框及 其xywh与置信度(5x2)。
为了防止过拟合,在第一个全连接层后面接了一个 ratio=0.5 的 Dropout 层。
最后一层预测类别概率和bound ing box的坐标。
在最后一层使用一个线性激活函数,其他层都使用leaky ReLU线性激活函数:
![]()
关于激活函数的详细介绍可参考一文搞懂激活函数(Sigmoid/ReLU/LeakyReLU/PReLU/ELU)
损失函数
YOLO V1的损失函数

优缺点
YOLO V1的优点:
1.非常快。把目标检测问题转换成一个回归问题。使用单个神经网络,处理速度为每秒45帧(更快的版本每秒150帧)。
2.YOLO能够在训练和预测阶段看到整幅图的信息,即包含类别及其外观的语义信息。这与RCNN中的滑动窗口不同,例如因为不能看到大的场景信息,而把背景当作目标对象。YOLO的background error比Fast RCNN少了一半。
3.YOLO能够学习到目标更加泛化的特征。当它被应用到新的场景或者输入不寻常的图像时,性能不会下降得很厉害。
YOLO V1的缺点:
1、YOLO的物体检测精度低于FastRCNN系列的算法。
2、YOLO容易产生物体的定位错误,例如相互靠的很近的物体。
3、YOLO对小物体的检测效果不好(尤其是密集的小物体,因为一个cell只能预测2个物体)。
4、YOLO 方法模型训练依赖于物体识别标注数据,因此,对于非常规的物体形状或比例,YOLO 的检测效果并不理想。同一类物体出现的新的不常见的长宽比和其他情况时,泛化能力偏弱。
5、YOLO 采用了多个下采样层,网络学到的物体特征并不精细,因此也会影响检测效果。
6、YOLO 的损失函数中,大物体 IOU 误差和小物体 IOU 误差对网络训练中 loss 贡献值接近(虽然采用求平方根方式,但没有根本解决问题)。因此,对于小物体,小的 IOU 误差也会对网络优化过程造成很大的影响,从而降低了物体检测的定位准确性。


YOLO V2
YOLO9000:Better, Faster, Stronger
![]()
创新点
优化目标:改善recall,提升定位的准确度,同时保持分类的准确度。
1.Better:从精度方面进行改进,让效果从YOLOv1的63.4%mAP上升到YOLOv2的78.6%mAP,基本和FasterR-CNN以及SSD持平。
2.Faster:网络结构方面做了更改,让模型速度更快;
3.Stronger:对损失函数做一个变化;
YOLO V2 的改进:
Batch Normalization 批量标准化
可以参考:https://www.cnblogs.com/shine-lee/p/11989612.html
去掉了Dropout,在每个卷积层后面加了BN层,模型收敛速度有了很大提升,且不会过拟合。
BN的优点:
BN层让损失函数更平滑;
BN更有利于梯度下降
效果:mAP提升了2%
High Resolution Classifier 高分辨率分类器
在YOLO V2中自定义了darknet分类网络,将图像的输入分辨率更改为448*448,然后在ImageNet上训练10轮,训练后的网络可以适应高分辨率的输入;应用到检测的时候,对检测部分网络进行微调.
预训练尺寸从224×224提高到448×448
效果:mAP提升了4%.
Convolutional With Anchor Boxes 引入Anchor Boxes
YOLO V1是利用全连接层直接预测bounding box的坐标。
YOLO V2则借鉴了Faster R-CNN的思想,引入anchor。
YOLO V2移除了全连接层并且使用anchor box来预测边界框。
1.首先,去掉了一个池化层来使得网络卷积层的输出具有更高的分辨率。
2.其次,因为YOLOv2模型下采样的总步长为32,调整网络输入为416×416,(416/32=13)最终得到的特征图大小为13×13,维度是奇数,这样特征图恰好只有一个中心位置。对于一些大物体,它们中心点往往落入图片中心位置,此时使用特征图的一个中心点去预测这些物体的边界框相对容易些。
3.另外,使用anchor box之后,由anchor box同时预测 类别和坐标。

DimensionCluster 维度聚类
anchor boxes的维度(个数,宽,高)通常需要通过手动给定,然后通过网络学习转换系数,最终得到准确的b-box建议框;如果可以通过维度聚类一开始就给定更具有代表性的boxes维度,那么网络就会更容易预测位置。
使用统计学习中的K-means聚类方法,通过对数据集中的ground truth box做聚类,找到ground truth box的统计规律。以聚类个数k为anchor boxs个数,以k个聚类中心box的宽高维度为anchor box的维度。
为了避免欧式距离对于大、小框的敏感程度,采用IoU作为K-means聚类的距离公式。
公式:
d(box,centroid)=1−IOU(box,centroid)

如图,平衡复杂度和IOU之后,最终得到k值为5,意味着作者选择了5种大小的box维度来进行定位预测,这与手动精选的box维度不同。
COCO: (0.57273, 0.677385), (1.87446, 2.06253), (3.33843, 5.47434), (7.88282, 3.52778), (9.77052, 9.16828)
VOC: (1.3221, 1.73145), (3.19275, 4.00944), (5.05587, 8.09892), (9.47112, 4.84053), (11.2364, 10.0071)
注意,这个宽高是在Grid的尺度下的,不是在原图尺度上,在原图尺度上的话还要乘以步长32。
效果:

Direct Location Prediction 直接位置预测
引入anchor box的,导致模型不稳定,尤其是在训练刚开始的时候。作者认为这种不稳定主要来自预测box的中心坐标(x,y)值。
在基于region proposal的目标检测算法中,是通过预测tx和ty来得到(x,y)值,也就是预测的是offsets。
这个公式是无约束的,预测的边界框很容易向任何方向偏移。因此,每个位置预测的边界框可以落在图片任何位置,范围太大,反向传播的就会很慢,这样就会导致模型收敛比较慢,在训练时需要很长时间来预测出正确的offsets。

假设一个网格单元对于图片左上角的偏移量是cx,cy,Bounding Boxes Prior的宽度和高度是pw,ph。


YOLO V2中没有采用这种预测方式,而是沿用了YOLO V1的方法,就是预测边界框中心点相对于对应cell左上角位置的相对偏移值。
网络在每一个网格单元cell有5个anchor box来预测5个bounding box,每个bounding box预测得到5个值。分别为:tx、ty、tw、th和to(类似YOLO V1的confidence)
为了将bounding box的中心点约束在当前cell中,使用sigmoid函数将tx、ty归一化处理,将值约束在0~1,这使得模型训练更稳定。
通过DimensionCluster+DirectLocationPrediction的改进
mAP提升5%。
Fine-Grained Features 细粒度特征
在FasterR-CNN和SSD中,通过不同的方式获得了多尺度的适应性,FasterR-CNN中使用不同的scale,SSD直接从不同大小的feature map上来提取ROI区域。
为了提升对小尺度物体的检测,在YOLOv2中加入了转移层(passthroughlayer),这个层次的功能就是将浅层特征图(26×26×256)连接到深层特征图(13×13×512)中,类似ResNet的残差网络结构。
对于26×26×512的特征图按行、按列隔一个进行采样,产生4个13×13×512维度的新特征图,然后concat合并得到13×13×2048的特征图,最后将其连接到深层特征图上。相当于做了特征融合,对于小目标检测比较有效。
即如下图这样提取特征,范围更大,最后再融合到一起

效果:mAP提升了1%
Multi-Scale Training 多尺度训练
每经过10次训练(10 epoch),就会随机选择新的图片尺寸进行训练。YOLO网络使用的降采样参数为32,那么就使用32的倍数进行尺度池化{320,352,…,608}。最终最小的尺寸为320 * 320,最大的尺寸为608 * 608。接着按照输入尺寸调整网络进行训练。
这种机制使得网络可以更好地预测不同尺寸的图片,意味着同一个网络可以进行不同分辨率的检测任务,在小尺寸图片上YOLO V2运行更快,在速度和精度上达到了平衡。


给Anchor打label
首先,对于一个物体的bbox,我们得到它的中心,看这个中心落在grid中的哪一个cell,那么这个cell就负责预测这个物体。但是,需要注意的是,每个cell中实际上有5个anchor,并不是每个anchor的会预测这个物体,我们只会选择一个长宽和这个bbox最匹配的anchor来负责预测这个物体。
那么什么叫长宽最为匹配?这个实际上就是将anchor和bbox都移动到了图像左上角,然后去计算它们的iou,iou最大的就意味着是宽高最为匹配,则这个anchor负责预测这个物体,如下图所示。

这种做法只是为了方便处理,anchor和bbox不转移到图像左上角的做法也是可行的。
网络架构
Backbone
为了改善YOLO模型的检测速度,YOLOv2在Faster方面也做了一些改进。
大多数神经网络依赖于VGGNet来提取特征,VGG-16特征提取功能是非常强大的,但是复杂度有点高,对于224*224的图像,前向计算高达306.9亿次浮点数运算。
YOLOv2中使用基于GoogleNet的定制网络DarkNet,一次前向传播仅需要85.2亿次浮点数计算。精度相比来降低2%(88%/90%)
网络结构小巧,但是性能强悍

看下图或许更清晰(一个大佬画的)
https://blog.csdn.net/weixin_44791964/article/details/102646387
YOLO V2使用了一个新的分类网络作为特征提取部分Darknet19,网络使用了较多的3 x 3卷积核,在每一次池化操作后把通道数翻倍。借鉴了network in network的思想,把1 x 1的卷积核置于3 x 3的卷积核之间,用来压缩特征。使用batch normalization稳定模型训练,加速收敛,正则化模型。
与此同时,其保留了一个shortcut用于存储之前的特征。


Neck
无
Head
Conv——》13 * 13 * (85x5)
除去网络结构的优化外,YOLO V2相比于YOLO V1加入了先验框部分,可以看到最后输出的conv_dec的shape为(13,13,425),其中13x13是把整个图分为13x13的网格用于预测,425可以分解为(85x5)。
在85中,由于YOLO V2常用的是coco数据集,其中具有80个类,剩余的5指的是x、y、w、h和其置信度。x5的5中,意味着预测结果包含5个框,分别对应5个先验框。
损失函数
YOLO V2 的损失函数
yoloV1 仅有两个box,但是编码(预测)基于单元格,分类向量只有一个,因此一个单元格只能预测一个目标。而yoloV2每个单元格有5个anchor box, 且单元格编码方式改变了,编码基于单元格的anchor box,通过anchor box 预测目标类别,实现了一个单元格同时预测多个目标)



优缺点
优点:
1、相对于 yolo v1 最大的变化,是使用了anchor box。增加 anchor 准确率下降,但是召回率上升不少。
2、YOLO系列的优点,如快速,pipline简单、通用性强。
缺点:
YOLO系列的普遍缺点:
1、识别物体位置精准性差。
2、召回率相比RCNN系列还是偏低。
YOLO V3
YOLOv3: An Incremental Improvement
![]()
创新点
在YOLOv3中借鉴了大量其它网络结构的优点
其主要改进如下:
1.YOLOv3的改进主要是backbone网络的提升,从v2的darknet-19到v3的deaknet-53。在v3中,还提供了轻量高速的网络tiny-darknet;
2.借鉴FPN(特征金字塔)在不同scale的featuremap上提取特征信息,然后做融合。相比于v2中仅仅通过多尺度图像的训练来讲,v3对于小目标的检测效果更好;
3.AnchorBoxes数目从v2中的5个提升到v3中的9个;
4.采用Logistic分类器替换Softmax分类器;因为softmax做分类器的话,它一次只能分一个类别,无法针对一个单元格有多个物体,所以换成了logistic
5.Loss损失函数进行了改进;
Multiscale detection 多尺度检测
借鉴特征金字塔

底层特征图可能保留更多小目标的特征信息

DBL:代码中的Darknetconv2d_BN_Leaky,是yolo_v3的基本组件。就是卷积+BN+Leaky relu。
res n:n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有多少个res_unit。
concat:张量拼接。将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
YOLO V3在3个尺度行进行检测(预测的特征图13×13, 26×26, 52×52)
yolo v3设定的是每个网格单元预测3个box,所以每个box需要有(x, y, w, h, confidence)五个基本参数,然后还要有80个类别的概率。所以3*(5 + 80) = 255。
Bounding Box 预测框感受野
特征图中的每一个网格cell都会预测3个bounding box 。
bounding box 与anchor box的区别:
三次检测,每次对应的感受野不同

32倍降采样的感受野最大,适合检测大的目标,所以在输入为416×416时,为(116 ,90); (156 ,198); (373 ,326)。
16倍的感受野适合一般大小的物体,anchor box为(30,61); (62,45); (59,119)。
8倍的感受野最小,适合检测小目标,因此anchor box为(10,13); (16,30); (33,23)。

所以当输入为416×416时,实际总共有(52×52+26×26+13×13)×3=10647 个proposal box。
网络架构
Backbone
Darknet53

包含53个卷积层
1、Darknet53具有一个重要特点是使用了残差网络Residual,Darknet53中的残差卷积就是首先进行一次卷积核大小为3X3、步长为2的卷积,该卷积会压缩输入进来的特征层的宽和高,此时我们可以获得一个特征层,我们将该特征层命名为layer。之后我们再对该特征层进行一次1X1的卷积和一次3X3的卷积,并把这个结果加上layer,此时我们便构成了残差结构。通过不断的1X1卷积和3X3卷积以及残差边的叠加,我们便大幅度的加深了网络。 残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。
Darknet53的每一个卷积部分使用了特有的DarknetConv2D结构,每一次卷积的时候进行l2正则化,完成卷积后进行BatchNormalization标准化与LeakyReLU。普通的ReLU是将所有的负值都设为零,Leaky ReLU则是给所有负值赋予一个非零斜率。以数学的方式我们可以表示为:
![]()
2、提取多特征层进行目标检测,一共提取三个特征层,它的shape分别为(13,13,75),(26,26,75),(52,52,75)最后一个维度为75是因为该图是基于voc数据集的,它的类为20种,YOLO V3只有针对每一个特征层存在3个先验框,所以最后维度为3x25。
3、采用反卷积UmSampling2d设计,逆卷积相对于卷积在神经网络结构的正向和反向传播中做相反的运算,其可以更多更好的提取出特征。

Neck
FPN
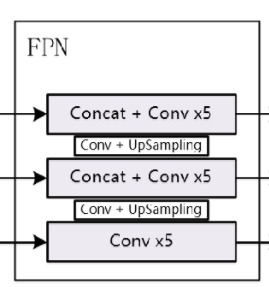
Head
对图像特征进行预测,生成边界框和并预测类别。
Head 主要用于最终检测部分,它在特征图上应用锚点框,并生成带有类概率、对象得分和包围框的最终输出向量。
VOC数据集
Conv——》
13 * 13 * (25x3)
26 * 26 * (25x3)
52 * 52 *( 25x3)
COCO数据集
Conv——》
13 * 13 * (85x3)
26 * 26 * (85x3)
52 * 52 * (85x3)
YOLO V3在3个尺度行进行检测(预测的特征图13×13, 26×26, 52×52)
YOLO V3设定的是每个网格单元预测3个box,所以每个box需要有(x, y, w, h, confidence)五个基本参数,然后还要有类别的概率(其中COCO数据集有80个类别、VOC数据集有20个类别)。
不同缩放尺度的 Head 被用来检测不同大小的物体,每个 Head 一共 (80个类 + 1个概率 + 4个坐标)* 3 锚点框,一共 255 个 channels。
损失函数
YOLO V3 的损失函数

只有正样本(物体)才参与分类,xywh的loss计算
优缺点
优点:
1、速度能达到 30 FPS,一般它比 R-CNN 快 1000 倍、比 Fast R-CNN 快 100 倍。
缺点:
YOLO系列的普遍缺点:
1、识别物体位置精准性差。
2、召回率相比RCNN系列还是偏低。
YOLO V4
YOLO v4: Optimal Speed and Accuracy of Object Detection

创新点
v4保留Darknet作为backbone,然后通过大量的实验研究了众多普适性算法对网络性能的影响,然后找到了它们最优的组合。
(1)提出了一个高效且强大的目标检测模型。任何人可以使用一个1080Ti或者2080Ti的GPU就可以训练出一个快速并且高精度的目标检测器。
(2)在检测器训练的过程中,测试了目标检测中最高水准的Bag-of-Freebies和Bat-of-Specials方法。
(3)改进了最高水准的算法,使得它们更加高效并且适合于在一个GPU上进行训练,比如CBN, PAN, SAM等。
Bag of freebies
pixel-wise调整
几何畸变:Random Scaling、Random Cropping、Random Filpping、Random Rotating
光照变化:brightness、contrast、hue、saturation、noise
遮挡:
Random Erase、CutOut、Hide-and-Seek、Grid Mask、
正则:Dropout、DropConnect、DropBlock
多张图片进行增强
Mixup、CutMix
GAN
Style Transfer GAN
样本据分布不均匀
两阶段:Online Hard Example Mining、Hard Negative Example Mining
一阶段:Focal Loss
类别关联度难以描述
Lable Smoothing、知识蒸馏
BBox回归
IOU loss、DIOU loss、GIOU loss、CIOU loss
常用的技巧方法
Bag of specials
Plugin Model
提高感受野:SPP、RFB、ASPP
注意力机制:SE、SAM、
特征融合模块:FPN、SFAM、ASFF、BiFPN
激活函数:ReLU、ReLU6、Swish、Mish
post processing method:
NMS、soft NMS、DIOU MNS
V4 采用的方法

CutMix Mosaic数据增强
CutMix数据增强方式利用两张图片进行拼接。
可参考博客:https://blog.csdn.net/weixin_38715903/article/details/103999227

YOLO V4的mosaic数据增强参考了CutMix数据增强方式。
但是mosaic利用了四张图片,根据论文所说其拥有一个巨大的优点是丰富检测物体的背景!且在BN计算的时候一下子会计算四张图片的数据!
1、每次随机读取四张图片。
2、分别对四张图片进行翻转、缩放、色域变化等,并且按照四个方向位置摆好。
3、进行图片的组合和框的组合

Dropblock
Dropout的主要问题就是随机drop特征,这一点在FC层是有效的,但在卷积层是无效的,因为卷积层的特征是空间相关的。当特征相关时,即使有dropout,信息仍能传送到下一层(去掉少量像素点并不妨碍我们理解图片含义),导致过拟合。
在DropBlock中,特征在一个block中,例如一个feature map中的连续区域会一起被drop掉。当DropBlock抛弃掉相关区域的特征时,为了拟合数据网络就不得不往别处看以寻找新的证据。

Class label smoothing 类标签平滑
Class label smoothing(类标签平滑)是一种正则化方法。如果神经网络过度拟合和/或过度自信,我们都可以尝试平滑标签。也就是说在训练时标签可能存在错误,而我们可能“过分”相信训练样本的标签,并且在某种程度上没有审视了其他预测的复杂性。
因此为了避免过度相信,更合理的做法是对类标签表示进行编码,以便在一定程度上对不确定性进行评估。YOLO V4使用了类平滑,选择模型的正确预测概率为0.9,例如[0,0,0,0.9,0…,0 ]。

从上图看出,标签平滑为最终的激活产生了更紧密的聚类和更大的类别间的分离,实现更好的泛化。
CIOU
参考博客:目标检测中的IoU、GIoU、DIoU与CIoU
具体公式在链接里可以看到
IoU是比值的概念,对目标物体的scale是不敏感的。然而常用的BBox的回归损失优化和IoU优化不是完全等价的,寻常的IoU无法直接优化没有重叠的部分。
于是有人提出直接使用IOU作为回归优化loss,CIOU是其中非常优秀的一种想法。
CIOU将目标与anchor之间的距离,重叠率、尺度以及惩罚项都考虑进去,使得目标框回归变得更加稳定,不会像IoU和GIoU一样出现训练过程中发散等问题。而惩罚因子把预测框长宽比拟合目标框的长宽比考虑进去。

Self-Adversarial Training自对抗训练
可参考博客:对抗样本和对抗训练笔记------简述
一种新的数据扩充技术,分两阶段:
第一阶段,神经网络先改变原始图像而不是网络权值,对自身执行对抗性攻击,改变原始图像,从而造成图像上没有目标的假象;
第二阶段,训练神经网络对修改后的图像进行正常的目标检测。
最优超参数
概念可以参考博客:最优超参数
在应用遗传算法去选择最优的超参数
可以参考我以前做过的类似的方法:基于遗传算法的BP神经网络的股票预测模型_matlab实现
SAM(Spatial Attention Module)改进
将SAM从空间上的attention修改为点上的attention,并将PAN的short-cut连接改为拼接,如下图:

Cross mini -Batch Normalization CmBN
BN是对当前mini-batch进行归一化,CBN是对当前以及当前往前数3个mini-batch的结果进行归一化,而CmBN则是仅仅在这个Batch中进行累积。

网络架构
Backbone

改进
a).主干特征提取网络:
DarkNet53 => CSPDarkNet53
b).激活函数:使用Mish激活函数

CSPnet
CSPnet结构并不算复杂,就是将原来的残差块的堆叠进行了一个拆分,拆成左右两部分:
主干部分继续进行原来的残差块的堆叠;
另一部分则像一个残差边一样,经过少量处理直接连接到最后。
因此可以认为CSP中存在一个大的残差边。

Neck
Spatial Pyramid Pooling SPP
可参考博客:SPP(Spatial Pyramid Pooling)详解
1、SPP结构参杂在对CSPdarknet53的最后一个特征层的卷积里,在对CSPdarknet53的最后一个特征层进行三次DarknetConv2D_BN_Leaky卷积后,分别利用四个不同尺度的最大池化进行处理,最大池化的池化核大小分别为13x13、9x9、5x5、1x1(1x1即无处理)
其可以它能够极大地增加感受野,分离出最显著的上下文特征。

PANet
PANet 基于 Mask R-CNN 和 FPN 框架,同时加强了信息传播。
该网络的特征提取器采用了一种新的增强自下向上路径的 FPN 结构,改善了低层特征的传播。
第三条通路的每个阶段都将前一阶段的特征作为输入,并用 3*3 卷积层处理他们,输出通过横向连接被添加到自上而下通路的同一阶段 feature map 中,这些特征图为下一阶段提供信息。
使用自适应特征池化(Adaptive feature pooling)来恢复每个候选区域和所有特征层次之间被破坏的信息路径,聚合每个特征层次上的每个候选区域,避免被任意分配。

上图为原始的PANet的结构,可以看出来其具有一个非常重要的特点就是特征的反复提取。在(a)里面是传统的特征金字塔结构,在完成特征金字塔从下到上的特征提取后,还需要实现(b)中从上到下的特征提取。


而在YOLO V4当中,其主要是在三个有效特征层上使用了PANet结构。
Head
同YOLO V3
损失函数
大量实验组合






优缺点
优点:
1、速度差不多与V3差别不大,采用各种调优手段使mAP提高。
YOLO V5
主要参考博客(侵权删):
YOLOv5网络详解
睿智的目标检测56——Pytorch搭建YoloV5目标检测平台
Yolov5 系列1— Yolo发展史以及Yolov5模型详解
一文读懂YOLO V5 与 YOLO V4
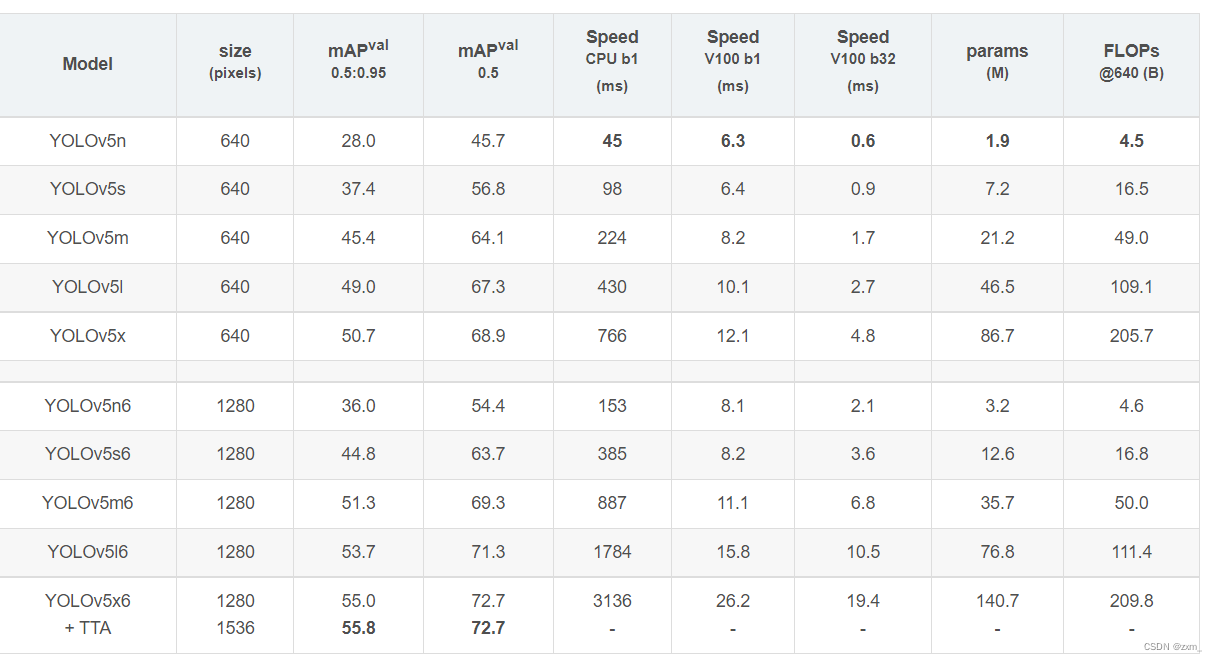
YOLOv5项目的作者是Glenn Jocher并不是原Darknet项目的作者Joseph Redmon。并且这个项目至今都没有发表过正式的论文。
YOLO V5基本上在YOLO V3的结构上进行修改。
创新点
1、使用了Focus网络结构增加通道数
2、Auto Learning Bounding Box Anchors-自适应锚定框
3、通过社渚一些内置的超参优化策略,提升整体性能
3、更适合工程落地
网络架构
下图来自:睿智的目标检测56——Pytorch搭建YoloV5目标检测平台
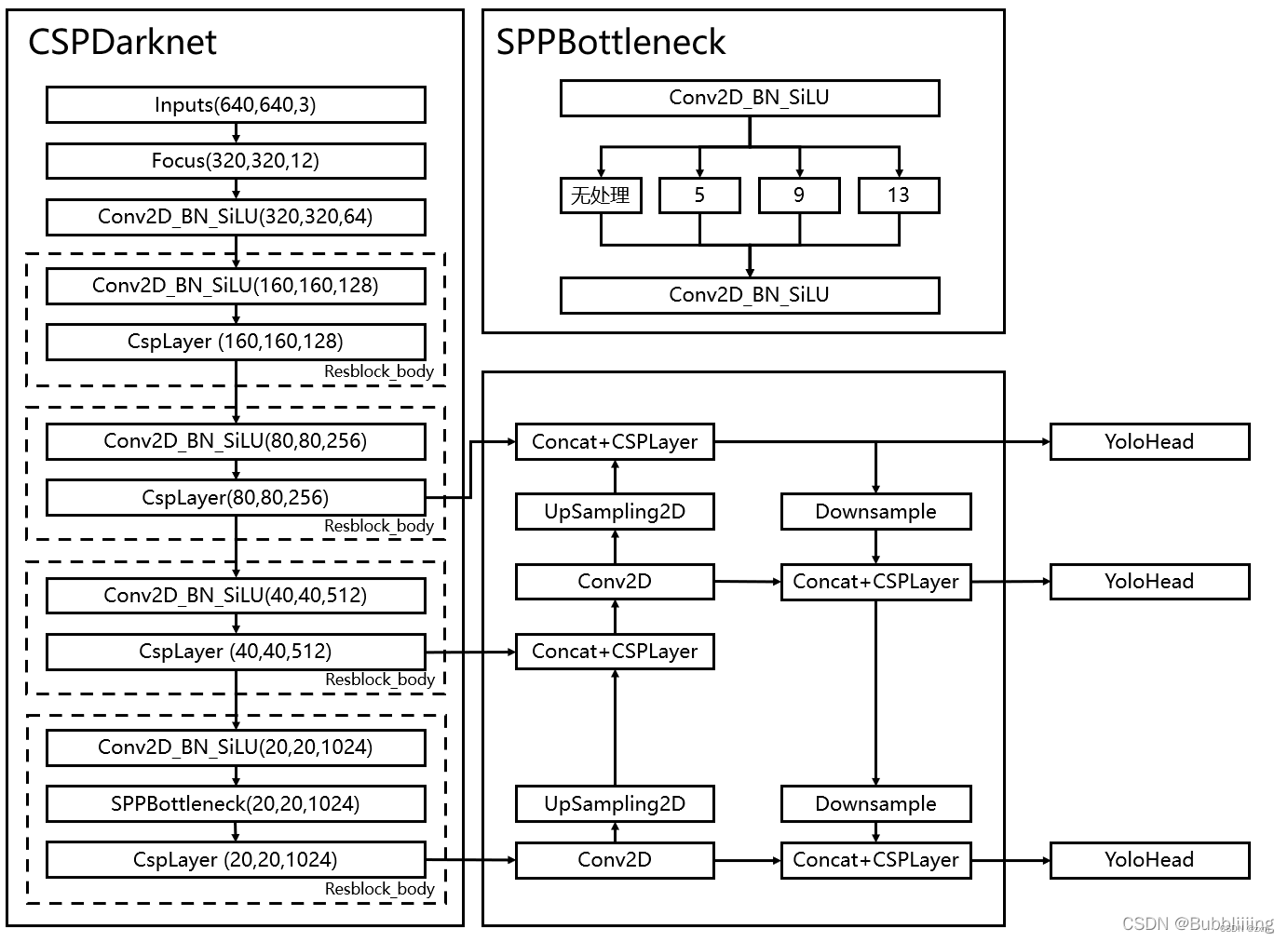
下图来自:YOLOv5网络详解
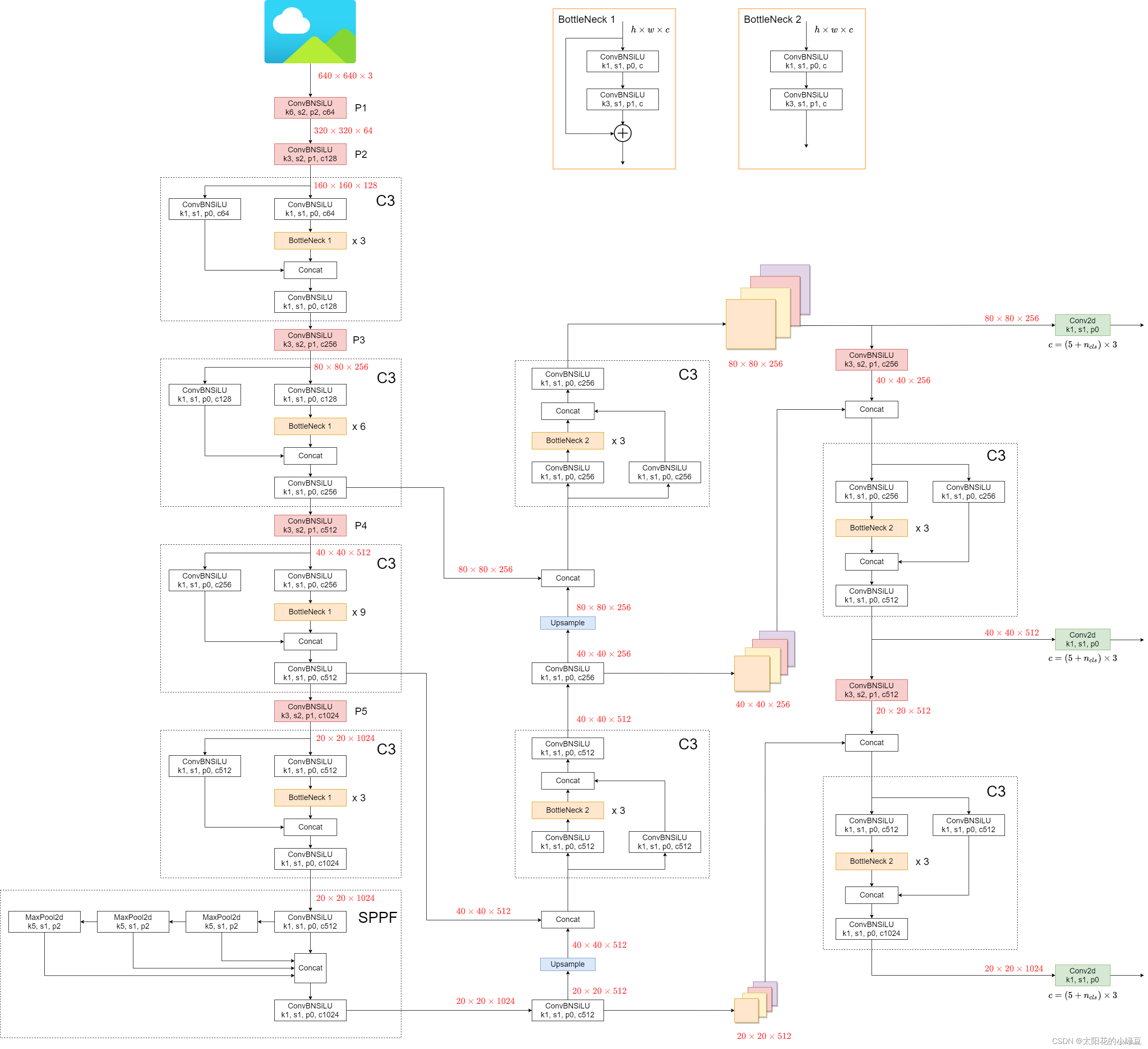
Backbone: New CSP-Darknet53
Neck: SPPF, New CSP-PAN
Head: YOLOv3 Head
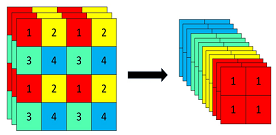
Focus网络结构
使用了Focus网络结构,,具体操作是在一张图片中每隔一个像素拿到一个值,这个时候获得了四个独立的特征层,然后将四个独立的特征层进行堆叠,此时宽高信息就集中到了通道信息,输入通道扩充了四倍。拼接起来的特征层相对于原先的三通道变成了十二个通道。
Auto Learning Bounding Box Anchors-自适应锚定框
在YOLO V3和YOLO V4中是采用 kmean 和遗传学习算法对自定义数据集进行分析,获得适合自定义数据集中对象边界框预测的预设锚定框。
在 YOLO V5中锚定框是基于训练数据自动学习的。
还没看代码,之后有机会在补充。
网络架构
Backbone
yolov4 和 yolov5 都使用 CSPDarknet 作为 backbone,从输入图像中提取丰富的信息特征。
基本上可以直接参考前面V4中提到的。
Neck
PaNet
可以直接参考前面V4中提到的。
Head
同YOLO V3 Head
优缺点
1、增加了正样本:方法是领域的正样本anchor匹配策略
2、超参数优化策略
3、通过灵活的配置参数,提升整体性能
参考博客链接:
https://blog.csdn.net/qq_36076110/article/details/105947444
https://blog.csdn.net/weixin_44791964/article/details/105310627
https://blog.csdn.net/weixin_44791964/article/details/102646387
https://zhuanlan.zhihu.com/p/161083602
https://blog.csdn.net/libo1004/article/details/110928070
https://blog.csdn.net/qq_29893385/article/details/81178261















 315
315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









