






1. 介绍:
差分隐私是一种保护数据隐私的技术。它在联邦学习的过程中,对梯度信息添加噪声。联邦学习是一种分布式的机器学习方法,它允许多个参与者共享模型参数的更新,而不是直接共享数据。差分隐私则是一种隐私保护技术,它通过在数据中添加噪声来防止敏感信息的泄露。
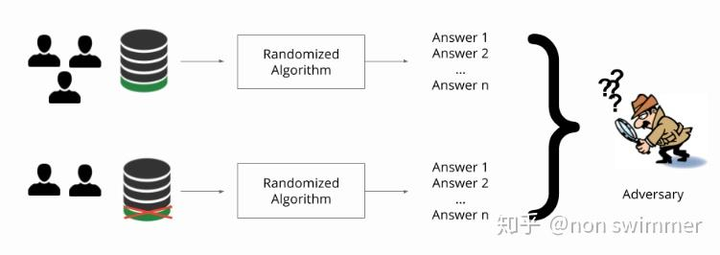
2. 作用与目的: 联邦学习中的差分隐私主要解决的是如何在进行联邦学习的同时,保护参与者的数据隐私。其目的是在不直接共享数据的情况下,允许多个参与者进行协同学习,从而提高模型的性能。同时,通过在数据中添加噪声,差分隐私可以防止敏感信息的泄露。
3. 实现原理: 联邦学习中的差分隐私主要包含三个步骤:裁剪、聚合和加噪。在这个过程中,每个参与者首先在本地计算模型的梯度,然后将梯度发送给服务器。服务器在收到梯度后,不是直接进行聚合,而是先进行梯度裁剪,然后再进行聚合。裁剪的目的是限制梯度的范围,防止某些参与者的梯度过大,从而影响到聚合结果。聚合后,服务器会在梯度上添加噪声,然后将带有噪声的梯度发送给所有的参与者。参与者收到带有噪声的梯度后,会用它来更新自己的模型。
4. 分类: 联邦学习中的差分隐私主要可以分为样本级差分隐私和用户级差分隐私。样本级差分隐私是指在每个样本上添加噪声,而用户级差分隐私则是在每个用户的数据上添加噪声。此外,根据噪声添加的位置,差分隐私还可以分为输入层差分隐私、隐藏层差分隐私和输出层差分隐私。输入层差分隐私是指在输入数据上添加噪声,隐藏层差分隐私是指在隐藏层的梯度上添加噪声,而输出层差分隐私则是在模型的输出上添加噪声。 5. 案例: 联邦学习中的差分隐私主要应用于需要进行协同学习但又需要保护数据隐私的场景。例如,在金融领域,多家银行可能需要共享模型参数来提高信贷模型的性能,但由于法律和隐私保护的需要,他们不能直接共享客户数据。在这种情况下,他们可以使用联邦学习进行协同学习,同时使用差分隐私来保护客户数据。
6. 参考资料:
-
[联邦学习之差分隐私_联邦学习差分隐私-CSDN博客]
-
[请问下该如何着手联邦学习和差分隐私结合方向的研究? - 知乎]
-
[联邦学习中的隐私保护——差分隐私 - 知乎 - 知乎专栏]
-
[差分隐私与深度学习–联邦学习 - CSDN博客]

















 1736
1736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









