







文章目录
MMDetection 复现
一、环境配置
服务器信息
- 输入
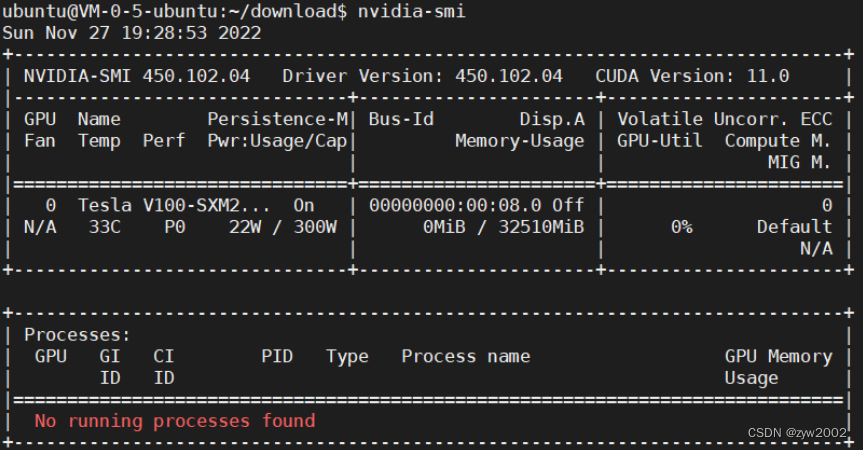
nvidia-smi查看显卡驱动。(或者输入nvidia-smi -a显示更详细的信息)
安装CUDA
下载并安装CUDA
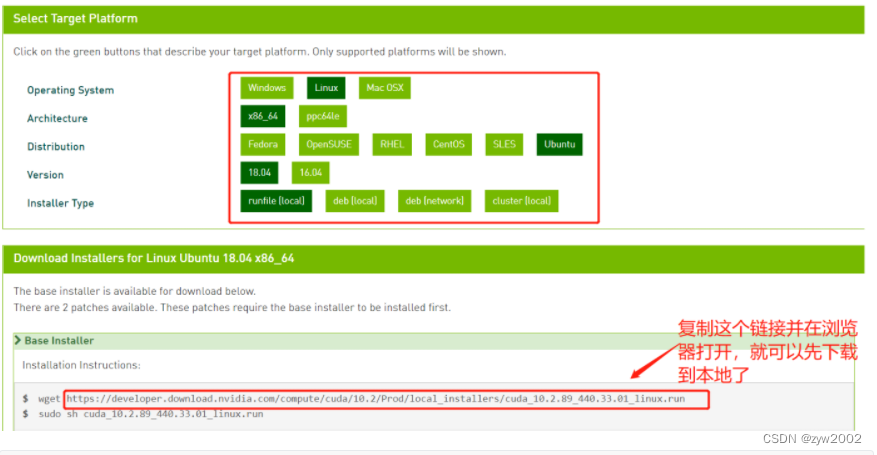
# 安装cuda10.2
sudo bash cuda_10.2.89_440.33.01_linux.run
在这一步时,一定要按Enter键取消Driver安装,因为我们先前已经安装好了显卡驱动。([ ] 表示不会安装,[X]表示安装)

配置环境变量
- 修改
~/.bashrc文件
vi ~/.bashrc
- 添加如下环境变量:
export CUDA_HOME=/usr/local/cuda
export PATH=$PATH:$CUDA_HOME/bin
export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
- 让环境变量生效
source ~/.bashrc
- 检查是否安装成功
nvcc -V

多个Cuda版本切换 (可选)
- 在安装了多个cuda版本后,可以在
/usr/local/目录下查看自己安装的cuda版本
cd /usr/local/
ls

- 使用
stat命令查看当前cuda软链接指向的哪个cuda版本
stat cuda

- 重新建立软链接
# 删除当前的软链接
sudo rm -rf cuda
# 建立新的软链接到cuda9.2版本上
sudo ln -s /usr/local/cuda-9.2 /usr/local/cuda
安装CUDNN
- 安装Cudnn
# 解压
tar xvf cudnn-10.2-linux-x64-v7.6.5.32.tgz
# 复制cudnn中的一些文件到cuda下
sudo cp cuda/include/cudnn.h /usr/local/cuda/include/
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
# 改变权限
sudo chmod a+r /usr/local/cuda/include/cudnn.h
sudo chmod a+r /usr/local/cuda/lib64/libcudnn*
安装Anaconda
- 选择相应的版本进行下载
wget https://repo.anaconda.com/archive/Anaconda3-2022.05-Linux-x86_64.sh
- 安装Anaconda
bash Anaconda3-2022.05-Linux-x86_64.sh
# 然后下一步继续就行。
# 说明:中间需要选择的都选yes或enter。
- 初始化环境变量
cd ~ && source .bashrc
- 启动Anaconda
conda activate
- 退出Anaconda
conda deactivate
搭建虚拟环境
新建虚拟环境
# 新建名为open-mmlab的虚拟环境,python=3.8
conda create -n open-mmlab python=3.8 -y
# 查看当前存在的虚拟环境
conda env list
# 进入open-mmlab
conda activate open-mmlab
安装pytorch
pip install torch-1.9.0+cu102-cp38-cp38-linux_x86_64.whl
pip install torchvision-0.10.0+cu102-cp38-cp38-linux_x86_64.whl
Pycharm 远程连接
代码同步
-
选择
tools→deployment→configuration -
点击左上方的
+号选择SFTP协议传输文件。 -
配置
ssh configuration, 点击… -
点击左上角的
+号,按自己的服务器填写信息 -
配置完成后点击
test connnection测试连接

-
配置
mapping,local path是自己项目的本地地址,deployment path是服务器上我们存放项目的地址。

-
在pycharm中选中要上传的文件,然后点击
Upload to Default Server -
勾选
Automatic Upload,至此我们的文件就不需要手动同步到服务器上了,可以通过upload to命令执行。
配置服务器解释器
-
选择
file→settings -
选择
project→python interpreter,点击右上方add interpreter -
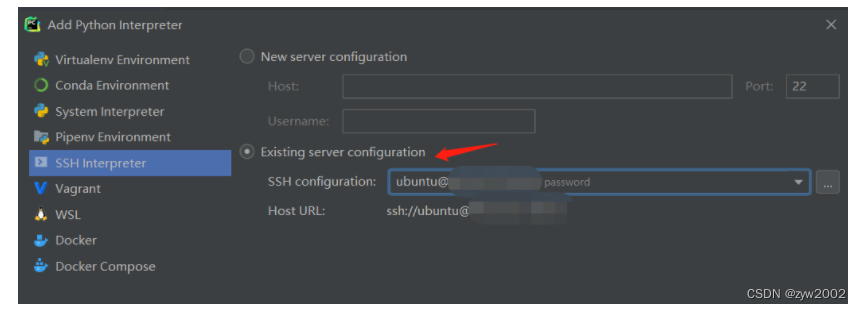
选择
ssh interpreter -
选择
existing interpreter,选择我们刚刚添加的服务器
-
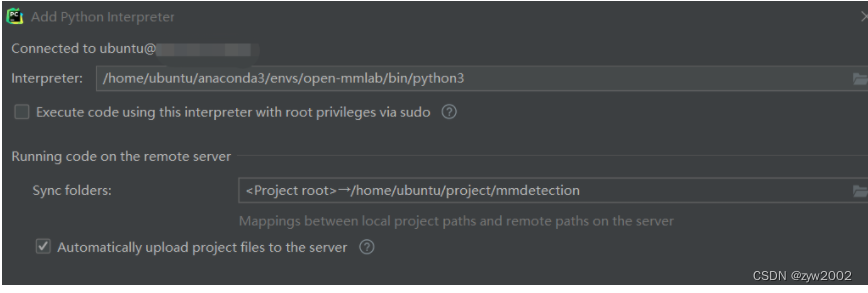
点击
interpreter右边的…,找到服务器中安装的anaconda
路径, 然后在该路径下选择解释器anaconda/envs/环境名称/bin/python3 -
点击
sync folders并将remote path改成我们服务器上存放项目的地址。
二、训练和推理
自制COCO格式数据集
coco数据集
├── coco2017: 数据集根目录
├── train2017: 所有训练图像文件夹(118287张)
├── val2017: 所有验证图像文件夹(5000张)
└── annotations: 对应标注文件夹
├── instances_train2017.json: 对应目标检测、分割任务的训练集标注文件
├── instances_val2017.json: 对应目标检测、分割任务的验证集标注文件
├── captions_train2017.json: 对应图像描述的训练集标注文件
├── captions_val2017.json: 对应图像描述的验证集标注文件
├── person_keypoints_train2017.json: 对应人体关键点检测的训练集标注文件
└── person_keypoints_val2017.json: 对应人体关键点检测的验证集标注文件夹
coco数据集中的标签文件 .json
- json 文件类型
<class 'dict'>
- 字典长度
5
- 字典中的key
dict_keys(['info', 'images', 'licenses', 'annotations', 'categories'])
info对应的键值
{'description': 'This is stable 1.0 version of the 2014 MS COCO dataset.',
'url': 'http://mscoco.org',
'version': '1.0',
'year': 2014,
'contributor': 'Microsoft COCO group',
'date_created': '2015-01-27 09:11:52.357475'
}
licenses对应的键值
[{'url': 'http://creativecommons.org/licenses/by-nc-sa/2.0/', 'id': 1, 'name': 'Attribution-NonCommercial-ShareAlike License'},
{'url': 'http://creativecommons.org/licenses/by-nc/2.0/', 'id': 2, 'name': 'Attribution-NonCommercial License'},
{'url': 'http://creativecommons.org/licenses/by-nc-nd/2.0/', id': 3, 'name': 'Attribution-NonCommercial-NoDerivs License'},
{'url': 'http://creativecommons.org/licenses/by/2.0/', 'id': 4, 'name': 'Attribution License'},
{'url': 'http://creativecommons.org/licenses/by-sa/2.0/', 'id': 5, 'name': 'Attribution-ShareAlike License'},
{'url': 'http://creativecommons.org/licenses/by-nd/2.0/', 'id': 6, 'name': 'Attribution-NoDerivs License'},
{'url': 'http://flickr.com/commons/usage/', 'id': 7, 'name': 'No known copyright restrictions'},
{'url': 'http://www.usa.gov/copyright.shtml', 'id': 8, 'name': 'United States Government Work'}
]
-
**image**对应的键值id: 每一张图片具有唯一的一个独特的编号height: 代表的是图片的高width:代表的是图片的宽file_name:代表的是图片的名字
'images': [
{
'file_name': 'COCO_val2014_000000001268.jpg',
'height': 427,
'width': 640,
'id': 1268
},
...
],
-
**annotation**对应的键值id:指的是这个annotation的一个id
image_id:等同于前面image字段里面的id。
category_id:类别id
segmentation:实例分割的区域
area:标注区域面积
bbox:标注框,x,y为标注框的左上角坐标。
iscrowd:决定是RLE格式还是polygon格式。
'annotations': [
{
'segmentation': [[192.81,
247.09,
...
219.03,
249.06]], # if you have mask labels
'area': 1035.749,
'iscrowd': 0,
'image_id': 1268,
'bbox': [192.81, 224.8, 74.73, 33.43],
'category_id': 16,
'id': 42986
},
...
],
-
categories对应的键值id:类别idname:类别名字
'categories': [
{'id': 0, 'name': 'car'},
]
训练
- 说明
num_classes=13
CLASSES=('Yellow','RedLeft','Red','GreenLeft','Green','off','GreenRight','GreenStraight','GreenStraightRight','RedRight','RedStraight','RedStraightLeft','GreenStraightLeft')
修改数据集相关参数
-
修改数据集路径文件:
configs/_base_/datasets/coco_detection.py- 修改
data_root为自己数据集的路径 - 修改
data字典中train、val、teat相关路径
- 修改
-
修改模型配置文件:
configs/_base_/models/faster_rcnn_r50_fpn.py- 定位到
roi_head字典出,修改bbox_head字典中的num_classes为13
- 定位到
-
修改coco数据集定义文件:
mmdet/datasets/coco.py-
将
CLASSES那里的参数修改为:CLASSES = ( 'Yellow', 'RedLeft', 'Red', 'GreenLeft', 'Green', 'off', 'GreenRight', 'GreenStraight', 'GreenStraightRight', 'RedRight', 'RedStraight', 'RedStraightLeft', 'GreenStraightLeft') -
将
PALETTE参数随意选13个留下即可,这个参数用来指定每个类别框的显示颜色
-
-
修改class_name:
mmdet/core/evaluation/class_names.py-
定位到
coco_classes函数,修改return中的参数为:def coco_classes(): return [ 'Yellow', 'RedLeft', 'Red', 'GreenLeft', 'Green', 'off', 'GreenRight', 'GreenStraight', 'GreenStraightRight', 'RedRight', 'RedStraight', 'RedStraightLeft', 'GreenStraightLeft' ]
-
修改训练相关参数
- 修改学习率、优化器相关参数:
configs/_base_/schedules/schedule_1x.py- 主要修改学习率
lr的值,一般按照线性计算,官方8张GPU设置为0.02,则4张为0.01,2张为0.005
- 主要修改学习率
训练模型
- 在训练前要先编译
sudo python3 setup.py develop
在mmdetection目录下新建test_work_dirs文件夹
- 单GPU训练
python tools/train.py configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py --gpus 1 --work-dir test_work_dirs
- 多GPU训练
不指定GPU训练
python3 tools/train.py configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py --gpus 1 --validate --work_dir test_work_dirs
指定GPU训练
CUDA_VISIBLE_DEVICES=${指定的GPU} tools/dist_train.sh ${configs下面的配置文件} ${GPU个数} --work-dir ${存储输出权重、日志等的目录}
CUDA_VISIBLE_DEVICES=2,3指定使用GPU-3和GPU-4,同时要设置GPUS=2
CUDA_VISIBLE_DEVICES=2,3 tools/dist_train.sh configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py 2 --work-dir test_work_dirs
推理
对批量数据进行标注
# Copyright (c) OpenMMLab. All rights reserved.
import asyncio
from argparse import ArgumentParser
from mmdet.apis import (async_inference_detector, inference_detector,
init_detector, show_result_pyplot)
import os
import tqdm
def parse_args():
parser = ArgumentParser()
# 存放推理数据的文件夹
parser.add_argument('--img', default='../data/coco/test2017', help='Image file')
# 存放配置文件
parser.add_argument('--config', default='../configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py', help='Config file')
# 存放权重文件
parser.add_argument('--checkpoint', default='../test_work_dirs/epoch_45.pth', help='Checkpoint file')
parser.add_argument('--out-file', default='output/rcnn_45', help='Path to output file')
parser.add_argument('--device', default='cuda:0', help='Device used for inference')
parser.add_argument(
'--palette',
default='coco',
choices=['coco', 'voc', 'citys', 'random'],
help='Color palette used for visualization')
parser.add_argument('--score-thr', type=float, default=0.2, help='bbox score threshold')
args = parser.parse_args()
return args
def main(args):
# build the model from a config file and a checkpoint file
model = init_detector(args.config, args.checkpoint, device=args.device)
for filename in tqdm.tqdm(os.listdir(args.img)):
img = os.path.join(args.img, filename)
result = inference_detector(model, img)
out_file = os.path.join(args.out_file, filename)
show_result_pyplot(
model,
img,
result,
palette=args.palette,
score_thr=args.score_thr,
out_file=out_file)
if __name__ == '__main__':
args = parse_args()
main(args)
参考
- 数据集
Bosch Small Traffic Lights Dataset
- 环境配置
ubuntu18.04 安装多个CUDA版本并可以随时切换_平凡中寻找不平凡的博客-CSDN博客
Pycharm连接服务器中的anaconda环境_LGhoyg的博客-CSDN博客_pycharm使用服务器的conda环境
mmdetection/get_started.md at master · open-mmlab/mmdetection
- 训练
Bosch Small Traffic Lights Dataset
【ubuntu】如何解压 .zip.001 .zip.002 .zip.003 文件_轮子去哪儿了的博客-CSDN博客_zip.001 zip.002
COCO数据集的 标签文件.json解读、理解_轮子去哪儿了的博客-CSDN博客_coco数据集标签文件
COCO数据集标注格式及意义_梦坠凡尘的博客-CSDN博客_coco标注格式
【MMDetection】v2.22.0入门:训练自己的数据集_嗜睡的篠龙的博客-CSDN博客
mmdetection_周月亮的博客-CSDN博客_mmdetection
















 3123
3123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











