







11.2 基于噪声信道模型的统计机器翻译原理
由IBM研究人员提出:一个翻译系统看成一个噪声信道,对于一个观察到的信道输出 S,寻找最大可能的输入 T,
求解 a r g m a x T P ( T ∣ S ) argmax_T P(T|S) argmaxTP(T∣S),根据贝叶斯公式即求解 a r g m a x T P ( T ) P ( S ∣ T ) 。 argmax_T P(T)P(S|T)。 argmaxTP(T)P(S∣T)。
概率 P(T)为目标语言的语言模型,P(S|T) 给定T情况下 S的翻译概率,称作 翻译模型。
统计翻译就是根据信道输出搜索最大可能的信道输入过程,即噪声信道模型中的解码过程。因此,这个搜索过程的模块称作 decoder。
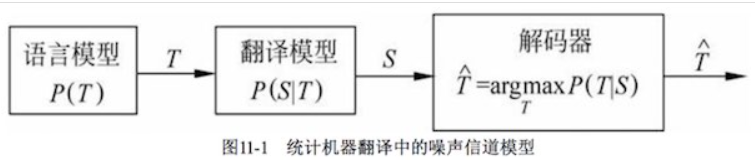
T和S的词之间存在 对齐(alignment)问题,刻画这种对齐关系的模型称作alignment model。
11.4 基于HMM的词对位模型
在基于HMM的词对齐模型中,源语言句子相当于 HMM 中的观测序列,对齐位置a为内部状态序列,翻译概率 p(f;lea)为输出概率(a;la;-1,I)为状态转移概率。利用求解 HMM学习问题的方法,可以获得初始概率、输出概率和状态转移概率等参数,然后利用解码算法就可以获得最优内部状态序列 a,即两个句子中词语之间的韦特比对齐结果。
基于短语的翻译模型
基于最大熵的翻译框架
短语的翻译模型
基于最大熵的翻译框架















 2283
2283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









