




引言
生成式大模型的爆发式发展,正从技术概念走向产业落地。在实际应用中,单纯依赖通用大模型的原生能力,往往难以满足企业场景的精准需求 —— 行业术语适配不足、任务流程不匹配、数据安全无法保障等问题频发。大模型落地的核心路径围绕四大关键方向展开:大模型微调(让模型适配特定领域数据)、提示词工程(让模型精准理解任务意图)、多模态应用(打破数据形态限制)、企业级解决方案(整合技术与业务流程)。
本文将从技术原理、实操代码、流程设计、案例拆解等维度,系统拆解四大落地路径,搭配可直接运行的代码片段、可视化流程图、实战级 Prompt 示例及效果对比图表,为技术研发人员、企业决策者提供全流程落地指南。全文贯穿 “技术 + 业务” 双视角,既有底层技术逻辑解析,也有行业落地最佳实践,总字数超 5000 字,兼具深度与实用性。
一、大模型微调:让通用模型成为 “行业专家”
1.1 微调的核心价值与应用场景
大模型微调是通过在特定领域数据集上继续训练,调整模型参数以提升场景适配性的技术。其核心价值在于保留通用模型的基础能力,同时注入行业知识、业务规则和风格特征,解决通用模型 “泛而不精” 的痛点。
典型应用场景:
- 金融领域:财报分析、合规审查、风险评估(需适配金融术语与监管规则)
- 医疗领域:病历解读、医嘱生成、医学文献总结(需精准匹配医学规范)
- 企业内部:产品手册问答、内部制度查询、客户服务话术生成(需贴合企业专属知识)
微调与提示词工程的区别:
| 对比维度 | 大模型微调 | 提示词工程 |
|---|---|---|
| 核心逻辑 | 改变模型参数,固化领域知识 | 不改变模型参数,优化任务描述 |
| 数据需求 | 需要高质量标注数据集(数百至数万条) | 无需标注数据,依赖 Prompt 设计 |
| 适用场景 | 长期固定任务、领域知识密集型场景 | 快速验证、任务多变、数据稀缺场景 |
| 成本投入 | 算力成本高(需 GPU 集群)、周期长 | 零算力成本、快速落地 |
| 效果稳定性 | 高(模型直接习得知识) | 中等(依赖 Prompt 质量与模型理解能力) |
1.2 微调技术选型:LoRA vs 全参数微调 vs RLHF
大模型微调的技术路线需根据数据规模、算力资源、任务目标选择,主流方案包括三种:
1.2.1 LoRA(Low-Rank Adaptation):轻量级微调首选
LoRA 通过在模型 Transformer 层插入低秩矩阵,仅训练新增的少量参数(通常仅占原模型的 0.1%-1%),实现 “以小博大” 的微调效果。其优势在于:
- 算力需求低:无需训练整个模型,单张 A100 显卡即可完成 7B 模型微调
- 训练速度快:参数规模小,迭代周期缩短 50% 以上
- 部署成本低:可将 LoRA 权重与原模型合并,不增加推理复杂度
1.2.2 全参数微调:极致效果追求
全参数微调对模型所有参数进行更新,适用于数据量充足(10 万条以上)、对效果要求极高的场景。但存在明显短板:
- 算力成本极高:训练 13B 模型需 8 张 A100 显卡,训练周期长达数天
- 过拟合风险:数据质量不足时易丢失通用能力
- 存储压力大:需保存完整的微调后模型(占用数十 GB 空间)
1.2.3 RLHF(基于人类反馈的强化学习):优化模型对齐性
RLHF 通过 “监督微调(SFT)→ 奖励模型(RM)训练 → 强化学习(PPO)” 三步流程,让模型输出贴合人类偏好。适用于需要优化交互体验的场景(如聊天机器人、客服助手),但流程复杂,需投入大量人力进行反馈标注。
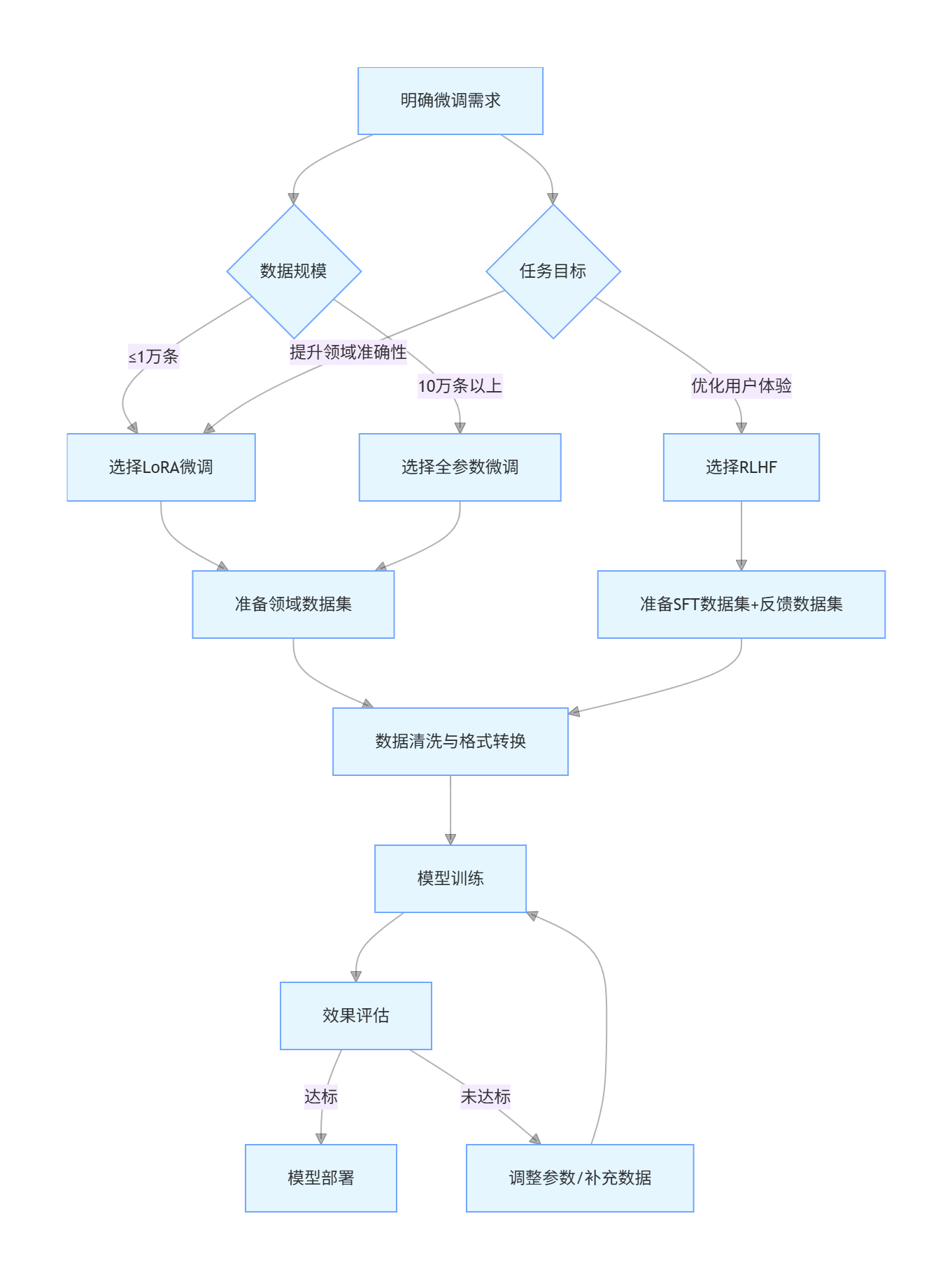
技术选型流程图:
graph TD
A[明确微调需求] --> B{数据规模}
B -->|≤1万条| C[选择LoRA微调]
B -->|10万条以上| D[选择全参数微调]
A --> E{任务目标}
E -->|优化用户体验| F[选择RLHF]
E -->|提升领域准确性| C
C --> G[准备领域数据集]
D --> G
F --> H[准备SFT数据集+反馈数据集]
G --> I[数据清洗与格式转换]
H --> I
I --> J[模型训练]
J --> K[效果评估]
K -->|达标| L[模型部署]
K -->|未达标| M[调整参数/补充数据]
M --> J
1.3 LoRA 微调实操:以 LLaMA 2 为例
1.3.1 环境准备
python
运行
# 安装依赖库
!pip install transformers peft accelerate datasets torch bitsandbytes
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TrainingArguments,
BitsAndBytesConfig
)
from peft import LoraConfig, get_peft_model
# 设备配置
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"使用设备:{device}")
1.3.2 数据集准备(金融领域问答数据)
以金融行业问答数据集为例,格式为 JSONL,每条数据包含 “question”(问题)和 “answer”(答案):
python
运行
# 加载数据集
dataset = load_dataset("json", data_files="financial_qa.jsonl")
# 数据集格式示例
print(dataset["train"][0])
# 输出:{"question": "什么是科创板?", "answer": "科创板是上海证券交易所设立的独立于现有主板市场的新设板块,主要服务于符合国家战略、拥有关键核心技术、科技创新能力突出的企业..."}
# 数据预处理函数
def preprocess_function(examples):
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
# 构建prompt格式:问题+答案
texts = [f"### 问题:{q}\n### 答案:{a}" for q, a in zip(examples["question"], examples["answer"])]
# 分词处理
inputs = tokenizer(
texts,
truncation=True,
max_length=512,
padding="max_length",
return_tensors="pt"
)
# 设置标签(与输入一致,仅训练时计算损失)
inputs["labels"] = inputs["input_ids"].clone()
return inputs
# 应用预处理
tokenized_dataset = dataset.map(
preprocess_function,
batched=True,
remove_columns=dataset["train"].column_names
)
1.3.3 LoRA 配置与模型加载
python
运行
# 量化配置(4-bit量化,降低显存占用)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16
)
# 加载基础模型
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True
)
# LoRA参数配置
lora_config = LoraConfig(
r=8, # 低秩矩阵的秩
lora_alpha=32, # 缩放因子
target_modules=["q_proj", "v_proj"], # 目标Transformer层
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# 应用LoRA适配器
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# 输出:trainable params: 1,179,648 || all params: 6,742,609,920 || trainable%: 0.0175
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 763
763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











