







1、CUDA(compute unified device architecture)可用于并行计算:
GTX1060 CUDA核心数:1280 显存大小:6G
2、随机梯度下降:计算偏导数需要的计算量很大,而采用随机梯度下降(即采用采样的概念)从中提取一部分样本来,这些样本中的特征已经可以在一定程度上代表完整训练集的特征。 Tensorflow中可以指定一个batch的size,规定每次被随机选择参与归纳的样本数。
3、梯度消失与梯度爆炸问题:
梯度消失:两个节点相连的神经网络,在使用链式法则的时候,会对导数进行连乘。即使用Sigmoid函数在自变量很大或者很小的时候,由下图可以看出,导数接近于0,这样在导数连乘的时候会使得w没什么变化。
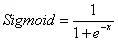
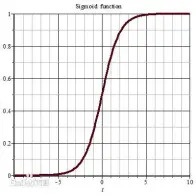
而对于这种问题比较好的解决方案是改用ReLu(修正线性单元)激活函数,如下图所示:
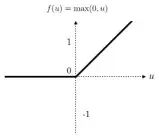
这样在第一象限中导数恒为1,不会很容易出现很大很小的值,求解复合函数的导数更简单。
4、归一化:
一般采用线性函数归一化(max-min)、0均值标准化(z-score standardization),在深度学习中,常见的是使用batch-normalization,这样可以让网络尽可能避免没有数据,代码为:
h2=tf.contrib.layers.batch_norm(h1,center=True,scale=True,is_training=false,scope=’bn’).
5、参数初始化问题:
常见的初始化为使用以0为均值,1为方差的分布生成后除以当前层的神经单元个数的算术平方根。或者初始为以0为均值,以很小的值为标准差的正态分布的方式。
中心极限定理:任何独立随机变量和极限分布都为正态分布。
6、正则化:
为防止出现过拟合问题,则进行正则化约束。方法是在损失函数中加入一个正则化项,以防止模型的规模过大所产生的过拟合。
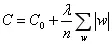
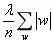
这个因子的含义是把整个模型中所有的权重w的绝对值加起来,lamda是惩罚因子,表示对这一项的重视程度。
L1正则化项即采用L1范数,L2正则化就是所有权重的平方之和。
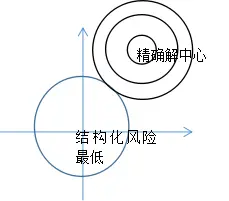
C0往往是经验风险,即误差所带来的代价,其收敛中心点记为黑色圆的圆心,其收敛中心为精确解,而蓝色的圆中心为正则化项的收敛点,即结构风险的最小化的收敛点,那么引入正则化项后,黑色大圆与蓝色圆相切的切点即为最后模型的收敛点。
7、其他超参数:有一些值需要在算法训练之前设定,无法通过学习获得,这就需要经验获得或者进行一定的预估、尝试。比如深度学习中的学习率,K-means算法中的簇数k.
8、Dropout:方法的目的在于克制过拟合状态,由于网络VC维很高,记忆能力很强,所以有些细枝末节的特征也会被网络记忆,从而削弱网络整体的泛化性能,使得其没有办法在验证集通过,仅有较好的训练集分类性能。这时候选择性的(随机)临时丢弃(关闭)一些节点,可以降低VC维,减小过拟合风险。
Keep_prob=tf.placehoder(tf.float32)
H_fc1_drop=tf.nn.dropout(h_fc1,keep_prob)
7、其他超参数:有一些值需要在算法训练之前设定,无法通过学习获得,这就需要经验获得或者进行一定的预估、尝试。比如深度学习中的学习率,K-means算法中的簇数k.
8、Dropout:方法的目的在于克制过拟合状态,由于网络VC维很高,记忆能力很强,所以有些细枝末节的特征也会被网络记忆,从而削弱网络整体的泛化性能,使得其没有办法在验证集通过,仅有较好的训练集分类性能。这时候选择性的(随机)临时丢弃(关闭)一些节点,可以降低VC维,减小过拟合风险。
Keep_prob=tf.placehoder(tf.float32)
H_fc1_drop=tf.nn.dropout(h_fc1,keep_prob)















 694
694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









