






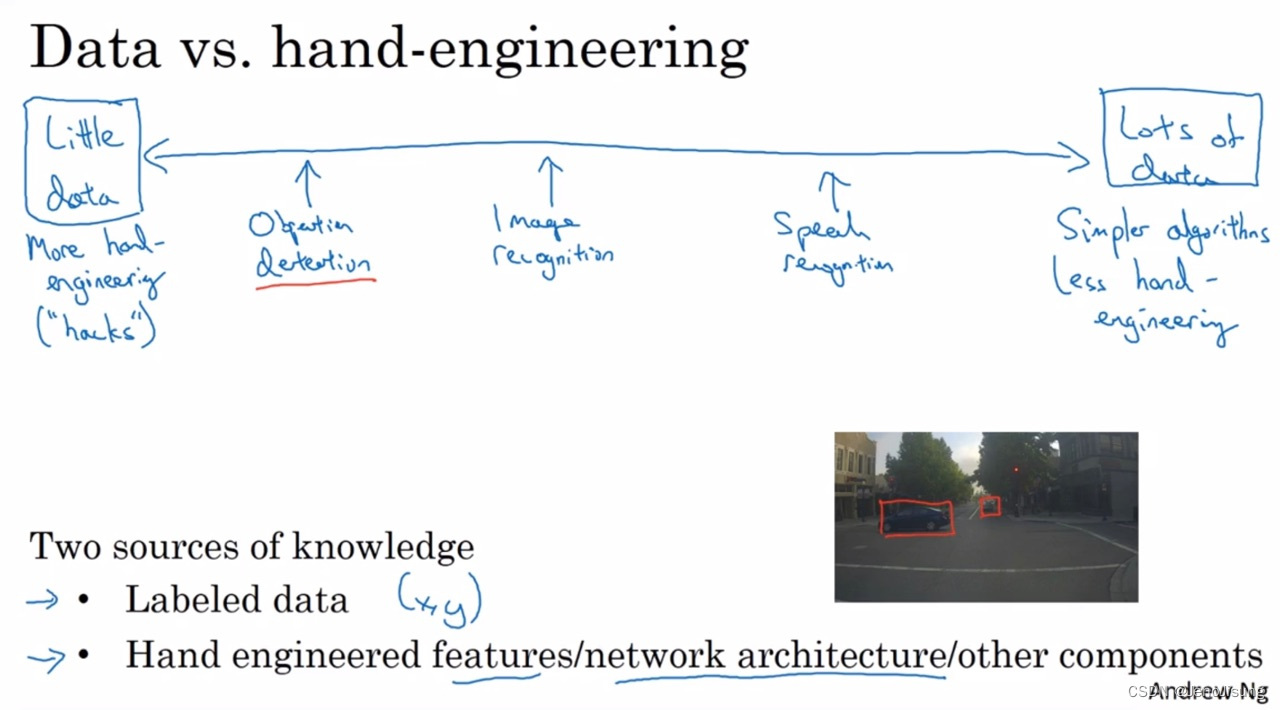
目标检测-获得边框的成本比标注目标和画出边界框的成本更高,相比于图像识别,我们往往使用更少的数据做目标检测。
一般情况下,当你有很多数据的时候,你往往会发现人们差不多使用比较简单的算法,以及更少的人工设计就可以了,所以不太需要针对问题来仔细地设计特征,取而代之当你有大量数据的时候,你可以用一个巨大的神经网络,甚至更为简单的结构就让一个神经网络学习我们想要学习的。
而数据没那么多的时候通常会看到人们做更多的人工设计,就是做更多的手工处理。在没有多少数据时人工设计实际上是获得良好效果的最好方法。
因为我们一直没有满意数量的数据所以神经网络一般都更为依赖于人工设计,这就是为什么在神经网络领域要么是开发了相当复杂的网络结构。
所幸的是,当只有很少量数据时,有一个能提供很大帮助的东西 就是迁移学习。
有一些对在基准数据上做的好的小建议:
1.集成:在弄清楚了你要什么神经网络,独立地训练多个神经网络,然后对它们的输出求平均作为结果初始化3、5、7个神经网络,然后训练所有这些神经网络,然后对它们的输出求平均。
重点-要对它们的输出求平均,不要对它们的权重求平均,那样是行不通的。
但因为集成意味着要在每幅图像上进行测试,又或许需要将一幅图像输入到3-15个不同的神经网络,这样会把运行速度降低3-15倍,有时候会降低更多(so它从来没被用到服务真正客户的产品中)
2.测试时使用多重剪切(multi-crop):多重剪切也就是在你的测试图像上应用数据增强的一种形式。先简单拷贝四次,包括附加镜像的两个版本。有一个技术叫十次剪切,即第一张:剪切中间部分,第二张:左上右上左下右下,后面两张同理。把这十张图像放入你的网络中运行,然后对他们的结果求平均。也许不需要10次,只需要若干几
集成最大的问题是你需要保留所有那些不同的网络随时用,那样会额外占用很多内存。
对于多重剪切,你只需要保存一个网络,所以它不会占用太大内存,但它仍然会很大程度上降低运行速度。
在产品中不建议使用这些方法。
要搭建一个架构,我们可以从别人的神经网络架构作为开始,而且如果可能,你可以用开源实现。使用别人预先训练的模型,然后在你的数据集上进行微调















 3024
3024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









