






最近DeepSeek爆火,AI小白被冲击得很懵逼。这篇文档我们不讲各种炸裂新闻,也不看各种论文
我今天就踏踏实实的把DeepSeek是什么、普通人该怎么用以及目前他的优缺点给你讲明白
DeepSeek是什么?
如果你对AI有一定的认知,你日常已经在使用Kimi,豆包等产品的话。
那你就可以类比来理解DeepSeek,DeepSeek中文翻译叫做深度求索
深度求索是这家公司的名称:杭州深度求索人工智能基础技术研究有限公司
而DeepSeek是他们公司的产品网站名称,类似Kimi,豆包等
DeepSeek的网页端地址:https://chat.deepseek.com/
安卓和IOS端也有APP,在应用市场搜索DeepSeek,安装注册即可使用

为什么这两天DeepSeek突然火爆出圈呢?
一句话总结
💡
DeepSeek这家公司使用几百万美金的成本训练出来的模型可以和海外上亿美金成本训练出来的模型相媲美
DeepSeek 初体验
💡
下面的内容全部以网页端进行说明
第一步:当我们访问了网址:https://chat.deepseek.com/
💡
这个时候如果你没有账号,则需要注册,由于目前DeepSeek太火爆,会有如下问题:
- 目前不支持除+86以外的手机号注册
- 如果你是+86手机号,但是还是注册不了,可能DeepSeek目前有问题,耐心等待

第二步:注册之后,我们进入到如下页面:
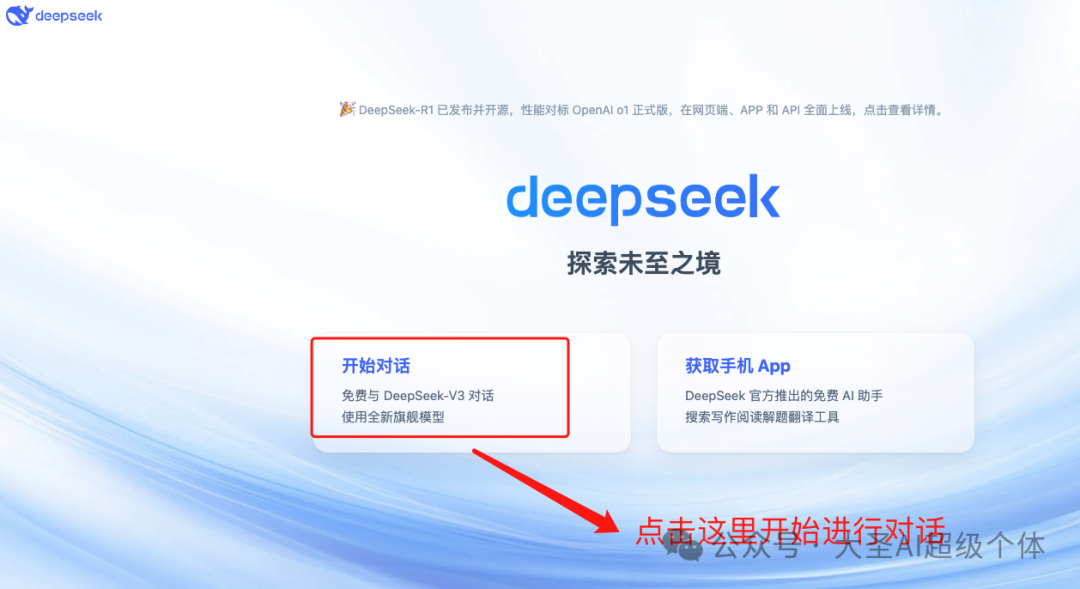
这个页面核心需要了解的是:
深度思考(R1)
如果你没有选择这个按钮,使用的就是很常规的模型(DeepSeek-V3),这个模型并不是它爆火的原因。
当你选择了这个深度思考(R1)之后,你使用的就是最近爆火的DeepSeek推理模型。
简单来讲,就是他具备了思考能力。这也是我们后面要重点讲的
联网搜索
我们都知道大模型本身是不具备获取实时信息的,所以主流的AI对话产品都会配置联网搜索的能力。
当你点选了这个按钮之后,在DeepSeek回答你的问题的时候,会自己控制是否需要从互联网获取最新的信息
PS:目前使用人数太多,联网搜索的能力可能不可用
DeepSeek的两大优势
在探寻到底该如何使用DeepSeek之前,我们要先了解他的两大优势
深度思考模式
什么是深度思考(R1)模式?为什么它可以让用户疯狂
💡
其实当你使用深度思考(R1)模式时,其背后是他们最新的推理模型:DeepSeek-R1
要搞清楚什么是深度思考模式,就需要先搞清楚什么是推理模型,以及他和非推理型大模型的区别
我举一个不是那么严谨,但是很形象,方便你理解的例子:
💡
我把推理模型和非推理模型比喻成学霸和普通的学生:
- 遇到数学题时:
- 普通模型:直接报答案(可能对可能错),就像背过题的学生
- 推理模型:会先写草稿纸,一步步算给你看,还会检查自己有没有算错
- 处理「为什么」的问题时:
- 普通模型:像百度百科,只能复述事实
- 推理模型:像老师讲课,能说清楚前因后果
总结来看:
推理模型 = 会动脑子的助手(能分析、会推导、能发现矛盾)
非推理模型 = 记忆力好的复读机(快速给答案,但可能不过脑子)
而且最最让人感动的是:DeepSeek会把整个推理过程完整的展现给你
中文水平最好
注意:这里用的是最好,没有之一,后面会有具体案例跟大家演示。
之前用别的AI,总感觉它们说话像在背模板:你听上句就能猜到下句要放什么屁,全是老掉牙的套话。
但DeepSeek的中文词汇量很大,说话的花样也多,根本猜不到它下一句会蹦出什么新鲜词儿。
而且它写的内容非常有灵气
DeepSeek使用攻略
很多小伙伴第一次兴致冲冲的跑去使用DeepSeek的时候,可能会发现它满嘴跑火车,或者使用各种高级词汇,一点也不接地气。
你的感受是对的,这里面有DeepSeek的原因,也有我们使用的原因,这里我就告诉你正确的使用姿势
让它“说人话”
当你发现DeepSeek的回复特别专业化,你听不懂的之后,你只需要加上一句提示词
💡
说人话
对,只要加这么一句就可以,效果会发生天翻地覆的变化,我们看下案例
当我问他:祛魅怎么理解时(我没有加说人话)
他的回复如下:

然后我补充了一句:说人话

你可以深刻感受到这前后的反差,而这不过只是一句说人话而已!
丢掉“专业提示词”
在2023年-2024年,你可能看到很多类似这种结构的提示词:

这个叫做结构化提示词,它是一种专业的提示词模版,旨在帮助人们更容易的写出有效的提示词。
这个框架极大的提高了提示词工程师的开发效率,也帮助很多人快速理解了如何和AI对话。
但是对于普通人来讲还是不够友好,并不是人人都能理解这个框架,甚至他们都不知道Markdown格式
现在:DeepSeek的推理模型来了,你会发现,我们真的只要把事情讲清楚就可以了,甚至这种专业的提示词框架会让他的输出结果变差!
这里面的原因就是我们上面讲到的,DeepSeek-R1是推理型模型,他具备了思考的能力
如果你还是使用之前的专业提示词框架,相当于你代替了DeepSeek的思考,直接告诉它该怎么做。
这时候你要明白:大多数情况下,我们肯定是没有大模型聪明的,你的思考过程只会让污染DeepSeek的推理结果。
就类似于外行指导内行,结果当然不会好
所以正确的做法应该是:就是用自然语言把你的场景和需求讲清楚,其余的交给DeepSeek来搞
举个例子:
如果你想要写一份PPT,目的是给传统制造业老板讲解关于数字化转型的PPT
传统的写法是:
请你扮演一位专业的PPT设计师,按照以下要求设计一份商业计划书:
1. 给企业讲解关于数字化转型
2. 使用MECE分析框架
3. 遵循金字塔原理
4. 运用4B原则(Big、Bold、Basic、Brief)
5. 每页不超过7行字

而另一种描述的提示词:
下周我要给一群50岁左右的传统制造业老板演讲,主题是工厂数字化改造。
但是呢,这些老板都是从一线打拼上来的,对新技术有点抗拒。
我特别担心:
1. 他们听不懂技术术语
2. 觉得投资太大风险高
3. 担心工人学不会新系统
你能帮我设计一个PPT框架吗?重点是要用他们熟悉的场景来讲,让他们觉得数字化没那么可怕

你会发现DeepSeek给你的答案中还带着话术
所以使用DeepSeek的一个通用的提示词公式就变成了如下内容:
此处引用鹤竹子的通用万能公式:
💡
我要xx,要给xx用,希望达到xx效果,但担心xx问题…
模仿名人风格写作
前面,我们讲到了DeepSeek的中文能力非常强,而这个使用技巧就是其中文能力的具体体现。
话不多说,我们让他写一篇文章
提示词也非常简单:
请你模仿鲁迅的文风,写一篇关于体育圈饭圈文化严重的文章
DeepSeek的回答:
PS:我真的着实被惊艳到了,有种回答儿时阅读鲁迅文章的即视感

Claude 3.5的结果

制造中文金句
DeepSeek的另一个能力,他非常擅长写中文金句,这里我们以广告文案为例来说明
我是一个广告文案创作者,我每天要针对不同的产品创造广告文案,希望可以得到甲方爸爸的认可,并且得到广泛传播
请你帮我给小米SU7汽车创造3条广告语
DeepSeek的回答:

Claude 3.5的回答:

两者的优劣,一眼便可分高下。
所以DeepSeek的另一个用户可以用来产生令人拍案叫绝的金句,提示公式仍然是那个万能公式:
我要xx,要给xx用,希望达到xx效果,但担心xx问题…
API超级便宜
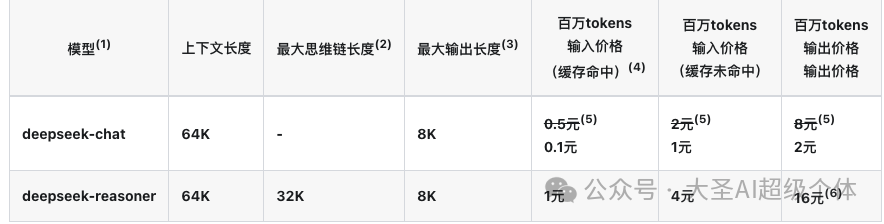
这个优势主要是针对开发者来讲,以前效果好的大模型价格死贵死贵的,无论是个人还是企业根本用不起。
- 对于普通模型,每百万输入 0.1 元,输出 2 元。
- 对于推理模型(也就是 R1),每百万输入 1 元,输出 16 元。
- ChatGPT的o1 ,每百万输入是 15 美金,折合108.78元,输出则是折合约 435 元
这让很多开发者或者个人笔记爱好者都在自己的系统中接入了DeepSeek的API,并且是真的香。
API地址:https://api-docs.deepseek.com/zh-cn/api/deepseek-api
DeepSeek的缺陷
代码能力
其实DeepSeek的代码能力很强,但是这里为什么要说是他的缺陷呢?
因为现在大众默认都已经拿DeepSeek和Claude 3.5 以及GPT o1进行比较了。
我见一些社群中有人专门拿一些案例测试过DeepSeek-R1和GPT o1的代码能力。
在一些复杂场景下,GPT-o1会技高一筹
但是从我的使用角度是让大模型帮助我写Coze的代码节点,以前我只能使用海外的Claude大模型
但是当DeepSeek-V3出来之后,我发现它帮助我写的代码已经能够完美运行了,都是一次过
长文案能力
DeepSeek-V3和DeepSeek-R1的上下文窗口目前都是64K
对于长文案的处理能力上,DeepSeek-V3和DeepSeek-R1的处理能力是比不上谷歌的Gemini和Claude 3.5的,因为他们两家都有200K的上下文模型
长文案能力比拼的就是上下文窗口
因此截止2025-01-28的一个数据结论来讲:
💡
DeepSeek更适合短文案、金句类型和风格模仿的的创作
而Gemini和Claude针对长文本的行文能力则更加优秀
安全隐患
此内容参考财猫大佬的文章:《DeepSeek r1是一个极不安全的 AI 模型,而开源让它失去控制》
这里我总结下财猫大佬的文章观点:
- 第一次接触DeepSeek-R1时,我意识到这是一个才华横溢的AI大模型,它学富五车,极为聪明,又很有个性
- 随着接触的深入,我发现这是一个满嘴跑火车,说胡话的模型,用专业的术语来讲:幻觉很严重
- 财猫会试着骗模型去做一些坏事,绝大多数模型会直接拒绝用户回答,但是DeepSeek-R1则很容易被破解
所以财猫的一个结论是:使用DeepSeek-R1辅助作恶是非常方便的
针对这块我不发表意见,还是使用财猫文章的那句话:
技术发展史早已证明,任何重大突破必然伴随伦理阵痛。
印刷术打破知识垄断的同时也传播了异端邪说,核能既点亮城市也投下爆炸阴影。
暗夜中的火炬既能照亮前路,也可能点燃森林。但人类从未因畏惧火焰而退回洞穴。
写在最后
DeepSeek是不是资本的运作?是不是过分的吹捧,谁知道呢?我也不想知道。
当年一个OpenAI的Sora让全球集体高潮,最终一年后才磨磨唧唧的上线了一个一般般的版本。
那我们的DeepSeek凭借超低的训练成本,极高的响应速度和牛逼的中文能力,凭什么不能举国欢庆!
DeepSeek之于我最现实的意义就是:
我再也不用在我的教学视频中说:这块代码需要使用海外的模型Claude,大家要考虑下突破网络限制。
我终于可以自豪的说:大家可以直接去用我们的国产之光DeepSeek模型啦
而且这次DeepSeek的出圈会让更多人关注到AI,学习AI,因AI而强大
随着低成本训练强大模型的案例出现,AI Agent的发展才有望真正迎来爆发式的发展
我的人人都成为Agent工程师的愿景也在逐步成为现实
写在最后
SD全套资料,包括汉化安装包、常用模型、插件、关键词提示手册、视频教程等都已经打包好了,无偿分享,有需要的小伙伴可以自取。




感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

请添加图片描述
若有侵权,请联系删除

















 1446
1446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









