







前言:
上两章已经详细介绍了SSD目标检测(1):图片+视频版物体定位(附源码),SSD目标检测(2):如何制作自己的数据集(详细说明附源码)。由于SSD框架是开源的代码,自然有很多前辈研究后做了改进。我也不过是站在前辈的肩膀上才能完成这篇博客,在这里表示感谢。
这一章就是讲解如何使用自己的数据集,让SSD框架识别。
–-----------------------------------------------------------------------------—--------------------------------------------
申明:
- 本博客用的测试数据集在这,只有20张标记图片。并不包含最后训练得到的模型。测试数据集只是测试程序的可行性,数据规模很小,有需要的同学自己下载。
- 博主没有物体检测的项目需求,本篇博客只是博主闲暇无聊研究如何用自己的数据集外测SSD,写博客的初衷一是为了记录二也是为后来人填坑——效果好坏受算法结构、受数据集、受训练次数因素影响,留言板处因为你的结果表现不优良而无视博主无偿付出的人,我劝你善良。
–-----------------------------------------------------------------------------—--------------------------------------------
行文说明:
要用SSD训练自己的数据集,首先要知道怎样制作自己的数据集,上一章已经有详细的介绍。有了准备好了的数据集后,再怎样调整代码可以使SSD框架运行得到结果,这一章都有详细介绍。所以行文大致分如下三个部分:
- 第一部分:SSD目标检测(2):如何制作自己的数据集(详细说明附源码)
- 第二部分:SSD框架细节调整
- 第三部分:模型展示
在本文中,笔者的操作系统是win10,用的IDE是PyCharm,python3.6 + GTX1060 + cuda9 + cudnn7,在此情况下以下的步骤都是运行完好。Linux系统下笔者也成功运行,只是小部分实现的方式不相同,这里不做详细讲解,还望包涵。
–-----------------------------------------------------------------------------—--------------------------------------------
–-----------------------------------------------------------------------------—--------------------------------------------
一、SSD框架细节调整说明
1、前期准备工作
第一步:先将SSD框架下载到本地,解压出来;SSD源码下载
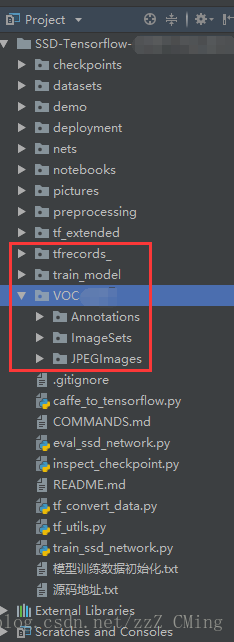
第二步:在解压出来的主目录下依次创建tfrecords_、train_model、VOC2007文件夹,再将之前在SSD目标检测(2):如何制作自己的数据集(详细说明附源码)中制作的三个文件夹Annotations、ImageSets、JPEGImages全都拖入VOC2007文件夹内;
第2.5步:为方便操作不易混淆,请在PyCharm里建立工程;得到的截图如下,截图说明如下:
- 请注意红色框
VOCxxx使用的是具体的名字,不过一般都是VOC2007; - 目录对应的从属关系不要出错
tfrecords_文件夹是用来存储.tfrecords文件(后面有程序可以直接生成)train_model文件夹是用来存储模型的记录与参数的
2、生成.tfrecords文件的代码微调说明
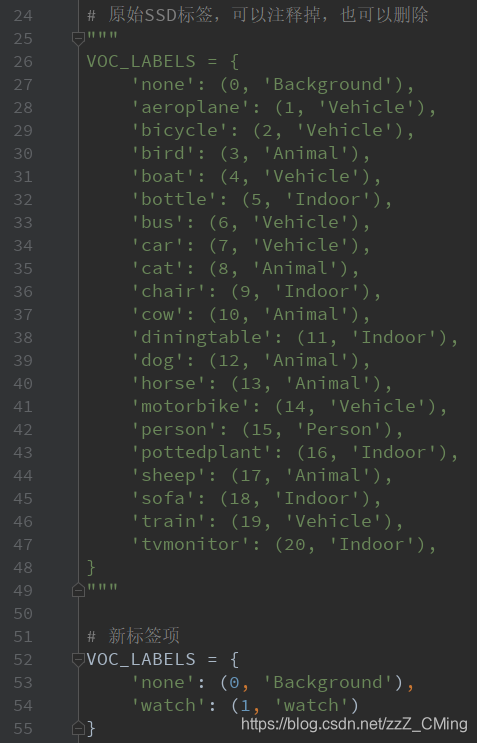
第三步:修改标签项——打开datasets文件夹中pascalvoc_common.py文件,将自己的标签项填入。我之前做的图片标签.xml文件中,就只有一个标签项“watch”,所以要根据你自己数据集实际情况进行修改;
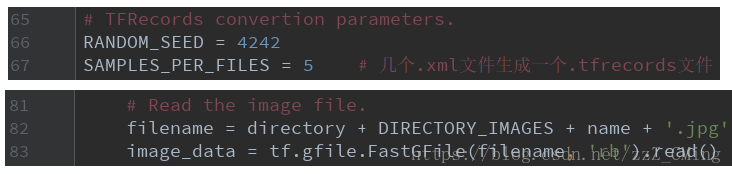
第四步:修改读取个数、读取方式——打开datasets文件夹中的pascalvoc_to_tfrecords.py文件,
- 修改67行
SAMPLES_PER_FILES的个数; - 修改83行读取方式为
'rb'; - 如果你的文件不是
.jpg格式,也可以修改图片的类型;
3、生成.tfrecords文件
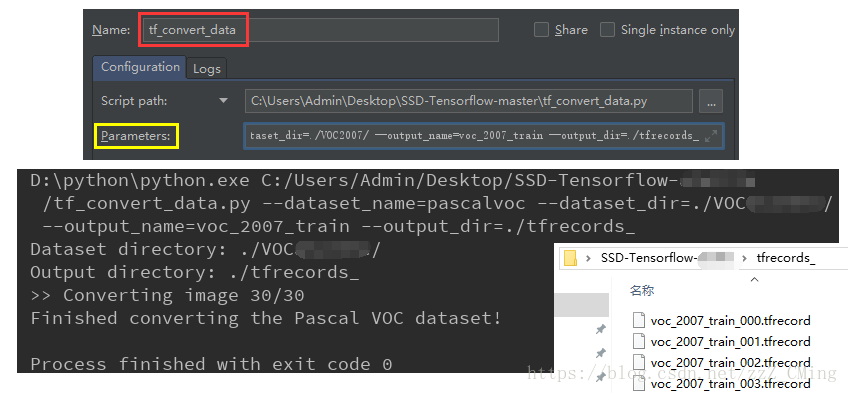
第五步:生成.tfrecords文件——打开tf_convert_data.py文件,依次点击:run、Edit Configuration,在Parameters中填入以下内容,再运行tf_convert_data.py文件,在面板中得到成功信息,可以在tfrecords_文件夹下看到生成的.tfrecords文件;
--dataset_name=pascalvoc
--dataset_dir=./VOC2007/
--output_name=voc_2007_train
--output_dir=./tfrecords_
4、重新训练模型的代码微调说明
第六步:修改训练数据shape——打开datasets文件夹中的pascalvoc_2007.py文件,
- 根据自己训练数据修改:
NUM_CLASSES= 类别数;
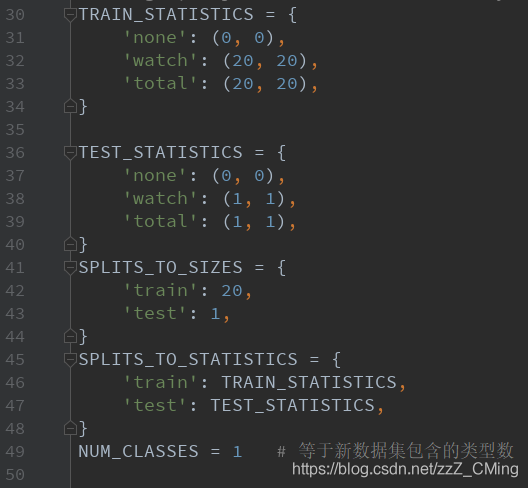
说明:TRAIN_STATISTICS的数值我并没有深入了解,大于新数据集该标签的总数一般都不会报错。我的数据集是由20张、每张包含一只手表的图片组成,所以下图的值我设定为20,大于20也没有报错,如果你有更精确的想法,请留言告诉大家!
第七步:修改类别个数——打开nets文件夹中的ssd_vgg_300.py文件,
- 根据自己训练类别数修改96 和97行:等于类别数+1;

第八步:修改类别个数——打开eval_ssd_network.py文件,
- 修改66行的类别个数:等于类别数+1;

第九步:修改训练步数epoch——打开train_ssd_network.py文件,
- 修改27行的数据格式,改为
'NHWC'; - 修改135行的类别个数:等于类别数+1;
- 修改154行训练总步数,
None会无限训练下去; - 说明:60行、63行是关于模型保存的参数;

5、加载vgg_16,重新训练模型
第十步:下载vgg_16模型——下载地址请点击,密码:ge3x;下载完成解压后存入checkpoint文件中;
最后一步:重新训练模型——打开train_ssd_network.py文件,依次点击:run、Edit Configuration,在Parameters中填入以下内容,再运行train_ssd_network.py文件
--train_dir=./train_model/
--dataset_dir=./tfrecords_/
--dataset_name=pascalvoc_2007
--dataset_split_name=train
--model_name=ssd_300_vgg
--checkpoint_path=./checkpoints/vgg_16.ckpt
--checkpoint_model_scope=vgg_16
--checkpoint_exclude_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box
--trainable_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box
--save_summaries_secs=60
--save_interval_secs=100
--weight_decay=0.0005
--optimizer=adam
--learning_rate=0.001
--learning_rate_decay_factor=0.94
--batch_size=4
--gpu_memory_fraction=0.7
注意:上面是输入参数:
--save_interval_secs是训练多少次保存参数的步长;--optimizer是优化器;--learning_rate是学习率;--learning_rate_decay_factor是学习率衰减因子;- 如果你的机器比较强大,可以适当增大
--batch_size的数值,以及调高GPU的占比--gpu_memory_fraction --model_name:我并没有尝试使用其他的模型做增量训练,如果你有需要,也请留言联系我,我很乐意研究;
若得到下图日志,即说明模型开始训练:

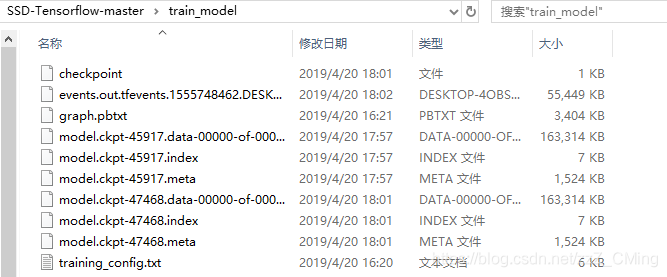
训练结束可以在train_model文件夹下看到生成的参数文件;
到这里,训练终于结束了!!!
–-----------------------------------------------------------------------------—--------------------------------------------
–-----------------------------------------------------------------------------—--------------------------------------------
二、结果展示
这是我训练的loss,我的数据集总共就20张图片,进行4.8W次训练用了将近一个小时,我的配置是GTX1060的单显卡;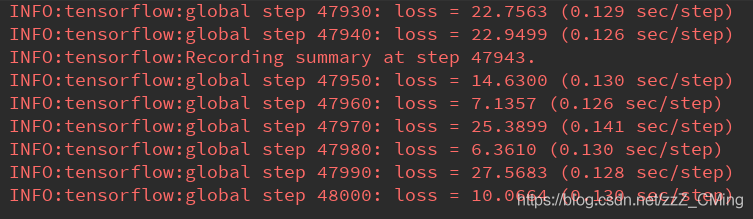
1、在日志中,选取最后一次生成模型作为测试模型进行测试;
2、在demo文件夹下放入测试图片;
3、最后在notebooks文件夹下建立demo_test.py测试文件,代码如下:
4、注意第48行,导入的新模型的名称是否正确;
# -*- coding:utf-8 -*-
# -*- author:zzZ_CMing CSDN address:https://blog.csdn.net/zzZ_CMing
# -*- 2018/07/20; 15:19
# -*- python3.6
import os
import math
import random
import numpy as np
import tensorflow as tf
import cv2
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from nets import ssd_vgg_300, ssd_common, np_methods
from preprocessing import ssd_vgg_preprocessing
from notebooks import visualization
import sys
sys.path.append('../')
slim = tf.contrib.slim
# TensorFlow session: grow memory when needed. TF, DO NOT USE ALL MY GPU MEMORY!!!
gpu_options = tf.GPUOptions(allow_growth=True)
config = tf.ConfigProto(log_device_placement=False, gpu_options=gpu_options)
isess = tf.InteractiveSession(config=config)
# 定义数据格式,设置占位符
net_shape = (300, 300)
# 输入图像的通道排列形式,'NHWC'表示 [batch_size,height,width,channel]
data_format = 'NHWC'
# 预处理,以Tensorflow backend, 将输入图片大小改成 300x300,作为下一步输入
img_input = tf.placeholder(tf.uint8, shape=(None, None, 3))
# 数据预处理,将img_input输入的图像resize为300大小,labels_pre,bboxes_pre,bbox_img待解析
image_pre, labels_pre, bboxes_pre, bbox_img = ssd_vgg_preprocessing.preprocess_for_eval(
img_input, None, None, net_shape, data_format, resize=ssd_vgg_preprocessing.Resize.WARP_RESIZE)
# 拓展为4维变量用于输入
image_4d = tf.expand_dims(image_pre, 0)
# 定义SSD模型
# 是否复用,目前我们没有在训练所以为None
reuse = True if 'ssd_net' in locals() else None
# 调出基于VGG神经网络的SSD模型对象,注意这是一个自定义类对象
ssd_net = ssd_vgg_300.SSDNet()
# 得到预测类和预测坐标的Tensor对象,这两个就是神经网络模型的计算流程
with slim.arg_scope(ssd_net.arg_scope(data_format=data_format)):
predictions, localisations, _, _ = ssd_net.net(image_4d, is_training=False, reuse=reuse)
# 导入新训练的模型参数
ckpt_filename = '../train_model/model.ckpt-xxx' # 注意xxx代表的数字是否和文件夹下的一致
# ckpt_filename = '../checkpoints/VGG_VOC0712_SSD_300x300_ft_iter_120000.ckpt'
isess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.restore(isess, ckpt_filename)
# 在网络模型结构中,提取搜索网格的位置
# 根据模型超参数,得到每个特征层(这里用了6个特征层,分别是4,7,8,9,10,11)的anchors_boxes
ssd_anchors = ssd_net.anchors(net_shape)
"""
每层的anchors_boxes包含4个arrayList,前两个List分别是该特征层下x,y坐标轴对于原图(300x300)大小的映射
第三,四个List为anchor_box的长度和宽度,同样是经过归一化映射的,根据每个特征层box数量的不同,这两个List元素
个数会变化。其中,长宽的值根据超参数anchor_sizes和anchor_ratios制定。
"""
# 主流程函数
def process_image(img, select_threshold=0.6, nms_threshold=.01, net_shape=(300, 300)):
# select_threshold:box阈值——每个像素的box分类预测数据的得分会与box阈值比较,高于一个box阈值则认为这个box成功框到了一个对象
# nms_threshold:重合度阈值——同一对象的两个框的重合度高于该阈值,则运行下面去重函数
# 执行SSD模型,得到4维输入变量,分类预测,坐标预测,rbbox_img参数为最大检测范围,本文固定为[0,0,1,1]即全图
rimg, rpredictions, rlocalisations, rbbox_img = isess.run([image_4d, predictions, localisations, bbox_img],
feed_dict={img_input: img})
# ssd_bboxes_select()函数根据每个特征层的分类预测分数,归一化后的映射坐标,
# ancohor_box的大小,通过设定一个阈值计算得到每个特征层检测到的对象以及其分类和坐标
rclasses, rscores, rbboxes = np_methods.ssd_bboxes_select(
rpredictions, rlocalisations, ssd_anchors,
select_threshold=select_threshold, img_shape=net_shape, num_classes=21, decode=True)
"""
这个函数做的事情比较多,这里说的细致一些:
首先是输入,输入的数据为每个特征层(一共6个,见上文)的:
rpredictions: 分类预测数据,
rlocalisations: 坐标预测数据,
ssd_anchors: anchors_box数据
其中:
分类预测数据为当前特征层中每个像素的每个box的分类预测
坐标预测数据为当前特征层中每个像素的每个box的坐标预测
anchors_box数据为当前特征层中每个像素的每个box的修正数据
函数根据坐标预测数据和anchors_box数据,计算得到每个像素的每个box的中心和长宽,这个中心坐标和长宽会根据一个算法进行些许的修正,
从而得到一个更加准确的box坐标;修正的算法会在后文中详细解释,如果只是为了理解算法流程也可以不必深究这个,因为这个修正算法属于经验算
法,并没有太多逻辑可循。
修正完box和中心后,函数会计算每个像素的每个box的分类预测数据的得分,当这个分数高于一个阈值(这里是0.5)则认为这个box成功
框到了一个对象,然后将这个box的坐标数据,所属分类和分类得分导出,从而得到:
rclasses:所属分类
rscores:分类得分
rbboxes:坐标
最后要注意的是,同一个目标可能会在不同的特征层都被检测到,并且他们的box坐标会有些许不同,这里并没有去掉重复的目标,而是在下文
中专门用了一个函数来去重
"""
# 检测有没有超出检测边缘
rbboxes = np_methods.bboxes_clip(rbbox_img, rbboxes)
rclasses, rscores, rbboxes = np_methods.bboxes_sort(rclasses, rscores, rbboxes, top_k=400)
# 去重,将重复检测到的目标去掉
rclasses, rscores, rbboxes = np_methods.bboxes_nms(rclasses, rscores, rbboxes, nms_threshold=nms_threshold)
# 将box的坐标重新映射到原图上(上文所有的坐标都进行了归一化,所以要逆操作一次)
rbboxes = np_methods.bboxes_resize(rbbox_img, rbboxes)
return rclasses, rscores, rbboxes
# 测试的文件夹
path = '../demo/'
image_names = sorted(os.listdir(path))
# 文件夹中的第几张图,-1代表最后一张
img = mpimg.imread(path + image_names[-1])
rclasses, rscores, rbboxes = process_image(img)
# visualization.bboxes_draw_on_img(img, rclasses, rscores, rbboxes, visualization.colors_plasma)
visualization.plt_bboxes(img, rclasses, rscores, rbboxes)
结果展示:这是我自己拍的照片,得到的识别效果还算勉强吧(请自动忽略我那性感的手毛!)

如果你的测试结果是下面这样的:
导致的原因:
- 训练次数太少,loss过高——解决方法除了优化数据集外,就是增大训练次数(要明白谷歌公布的模型都是在大型集群上训练好多天的结果,我们就在GTX1060单显卡上训练4.8W次就想出非常好的结果?偶然的成功比失败更可怕,而且想弯道超谷歌不太可能吧!)
- 另外上面程序65行的
select_threshold、nms_threshold参数你也可以做调整;观察下图可以发现误标框框的预测值都小于0.55,而唯一正确的框框预测值等于0.866。所以认真理解上面程序66、67行我写的注释,对你的问题会有帮助;

–-----------------------------------------------------------------------------—--------------------------------------------
本博客用的测试数据集在这,只有20张标记图片。并不包含最后训练得到的模型。
申明:测试数据集只是测试程序的可行性,数据规模很小,有需要的同学自己下载。
–-----------------------------------------------------------------------------—--------------------------------------------















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









