






下面介绍一个特别的、有用的Network的架构
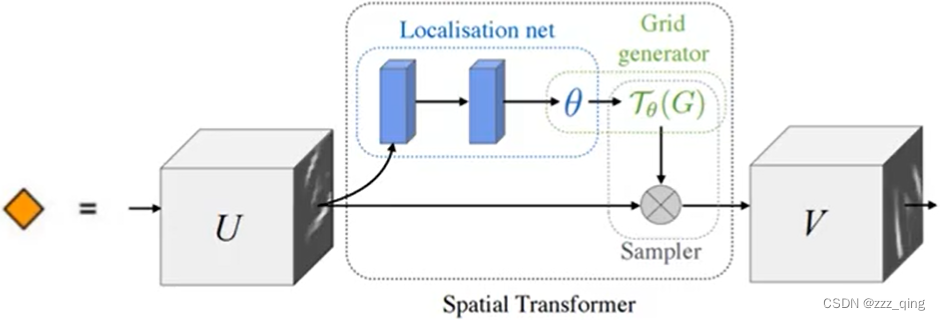
Spatial Transformer Layer
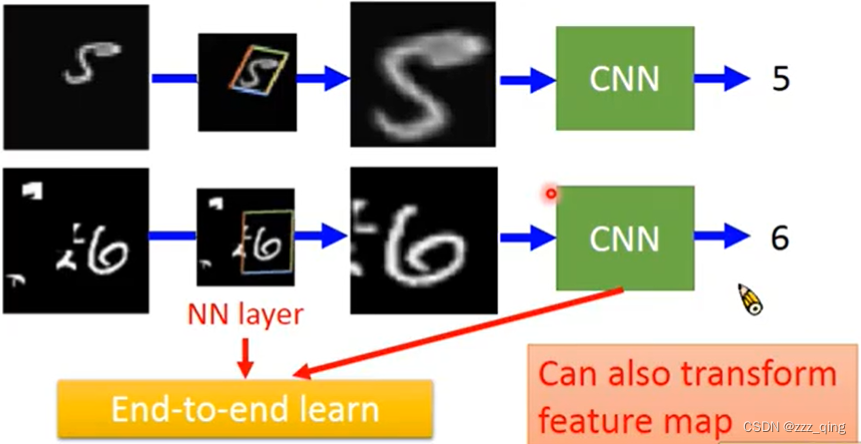
CNN is not invariant to scaling and rotation.
Spatial Transformer Layer的目的是learn一个Layer,这个Layer的作用是对input image做旋转缩放。
Spatial Transformer Layer也是一个Neuron Network,它可以跟CNN连接起来,即在原来CNN的Layer前面多叠了一个Spatial Transformer Layer。它不止可以transform input image,同样也可以transform CNN的每一个feature map(因为可以把feature map也当成image,只不过这个image的channel是取决于filter的数目),所以它也可以被放在CNN里面去transform那些feature map。
-
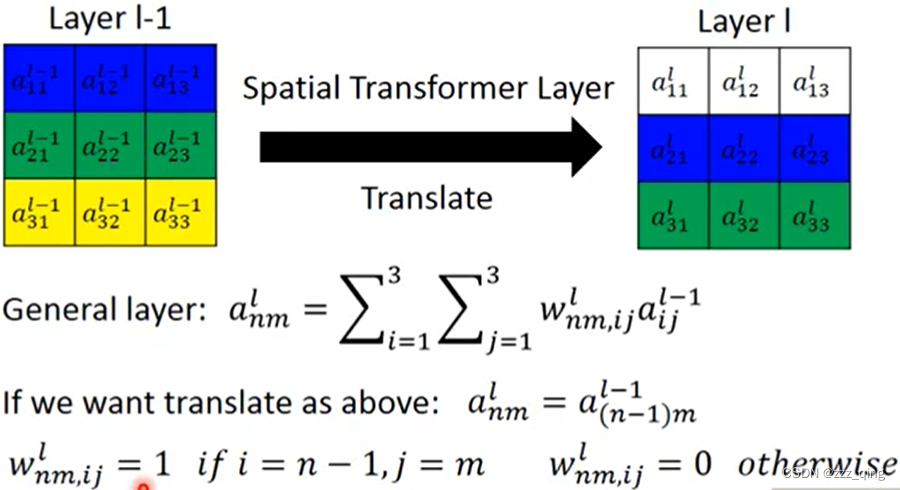
How to transform an image/feature map
把weight参数做不同的设计,就可以把一张image旋转缩放变成另外一张image,如下图:
-
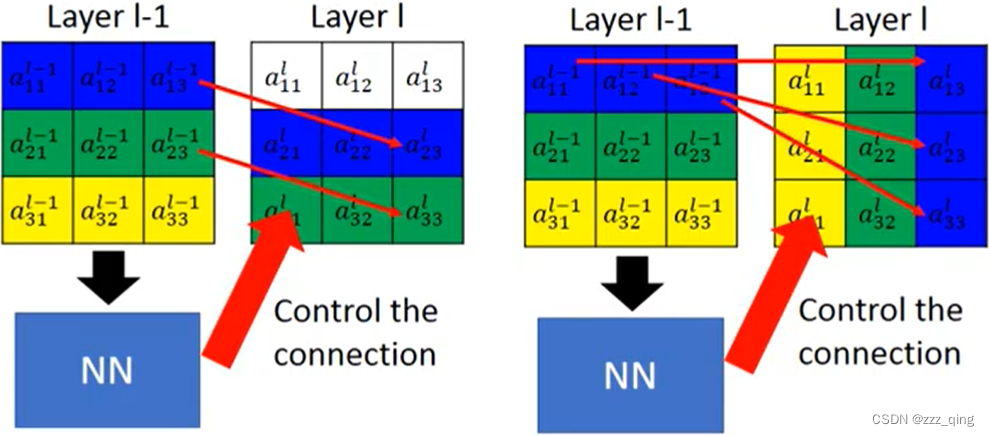
Image Transformation
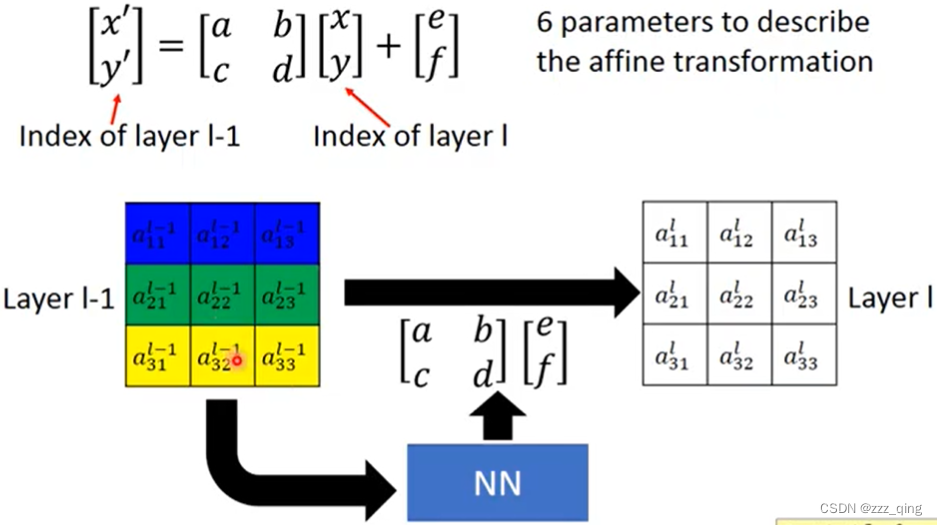
我们把旋转、平移、缩放叫做affine transformation。只需要六个参数来做affine transformation。
-
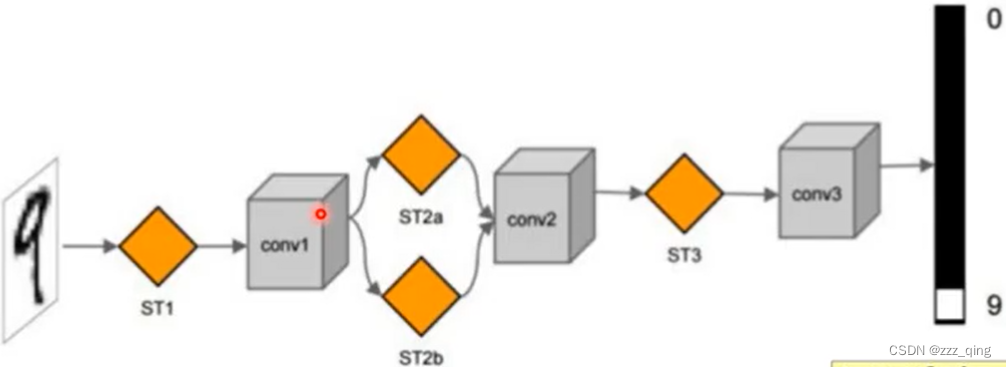
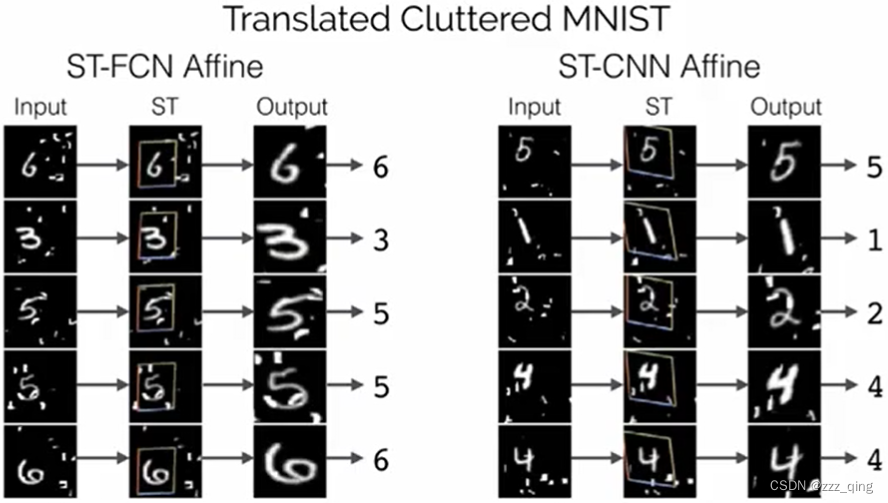
example
下面是数字识别的一个example:















 1303
1303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









