







 本文介绍了卷积神经网络(CNN)在图像识别中的应用,探讨了其网络架构设计,包括receptive field、kernel size、stride和padding。此外,还讨论了CNN的平移不变性,并引入了Spatial Transformer Layer(STL),用于处理图像的旋转、缩放等变换,强调STL在CNN中作为中间模块的作用,以提高模型的适应性。
本文介绍了卷积神经网络(CNN)在图像识别中的应用,探讨了其网络架构设计,包括receptive field、kernel size、stride和padding。此外,还讨论了CNN的平移不变性,并引入了Spatial Transformer Layer(STL),用于处理图像的旋转、缩放等变换,强调STL在CNN中作为中间模块的作用,以提高模型的适应性。
第三节 2021 - 卷积神经网络(CNN)_哔哩哔哩_bilibili
network架构设计
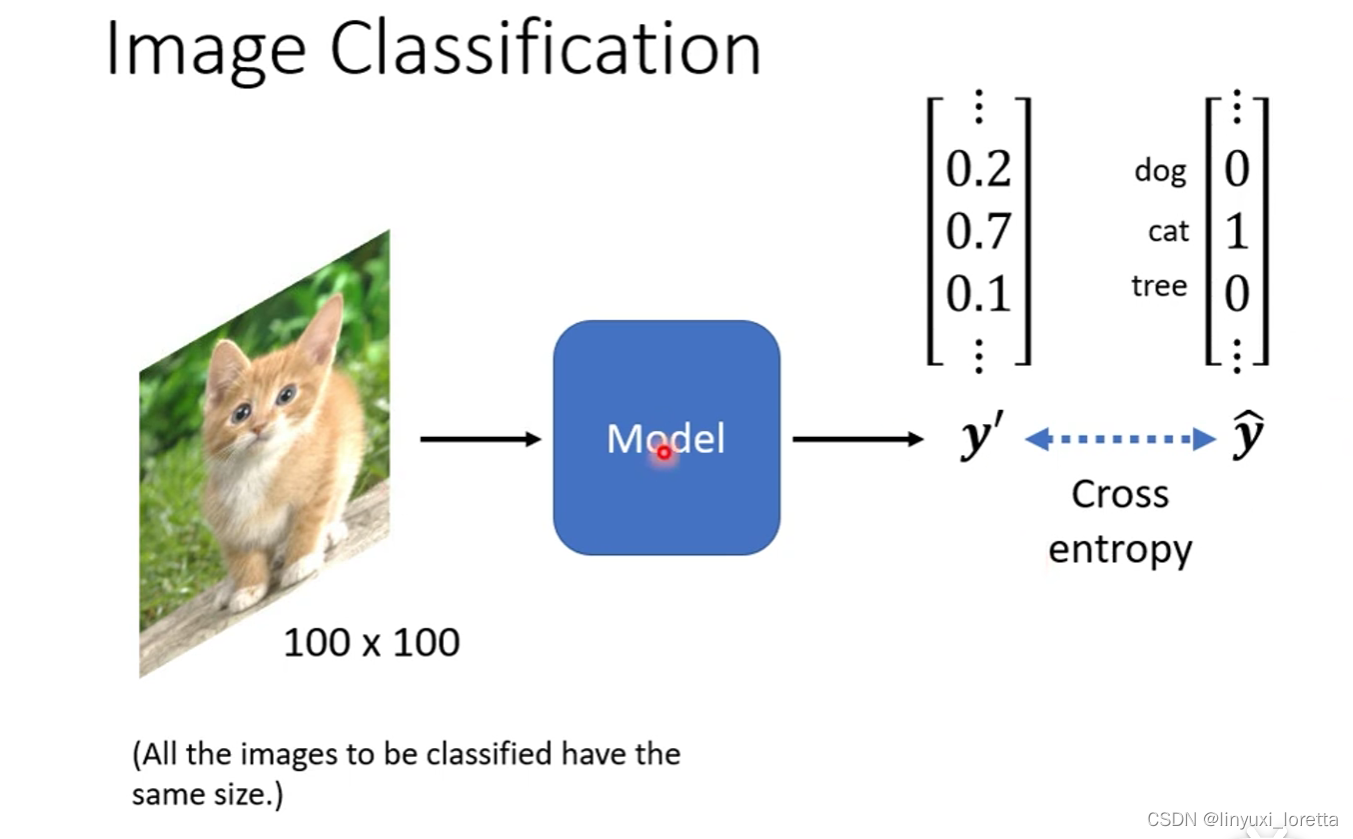
我们往往需要假设一个模型输入的影像大小都是一样的
把所有图片都先rescale成大小一样,再丢到影像辨识系统里
今天比较强的影像辨识系统,往往可以辨识出1000种以上的东西、甚至上万种
接下来的问题是,怎么把一个影像当作一个模型的输入?

对于一个machine来说,一张图片其实是一个三维的tensor(Tensor张量,可以看做是一个多维数组。维度大于2的矩阵)
一张彩色的图片,他每个pixel都是由R G B三个颜色所组成的,3个channel就代表了R G B三个颜色
长和宽代表了图片的解析度,这张图片里有的pixel像素的数目
接下来把三维的tensor拉直,拉直后就可以丢到一个network里去了(因为network的输入都是一个向量,)
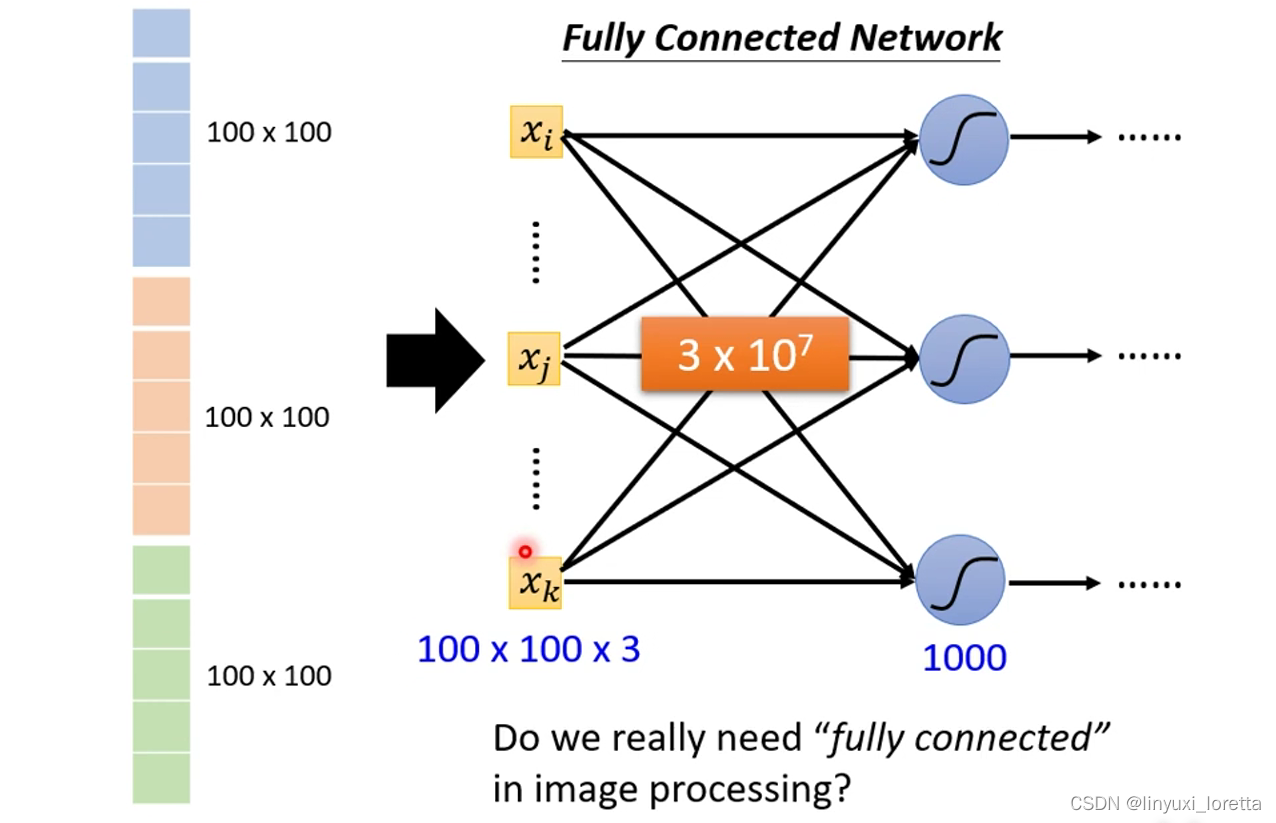
目前为止 只讲过fully connected network
如果把这个向量当作network的输入,input这边 这个feature vector的长度就是100*100*3,假设第一层的neuron数目有1000个,那能计算一下第一层一共多少个weight吗?
参数增加可以增加模型的弹性、但也增加了overfitting的风险。
如何减少参数,考虑到影像辨识问题本身的特性,不需要fully connected。不需要每个neuron和input的每个dimension都有一个weight
对影像辨识问题本身的特性的观察:
1.
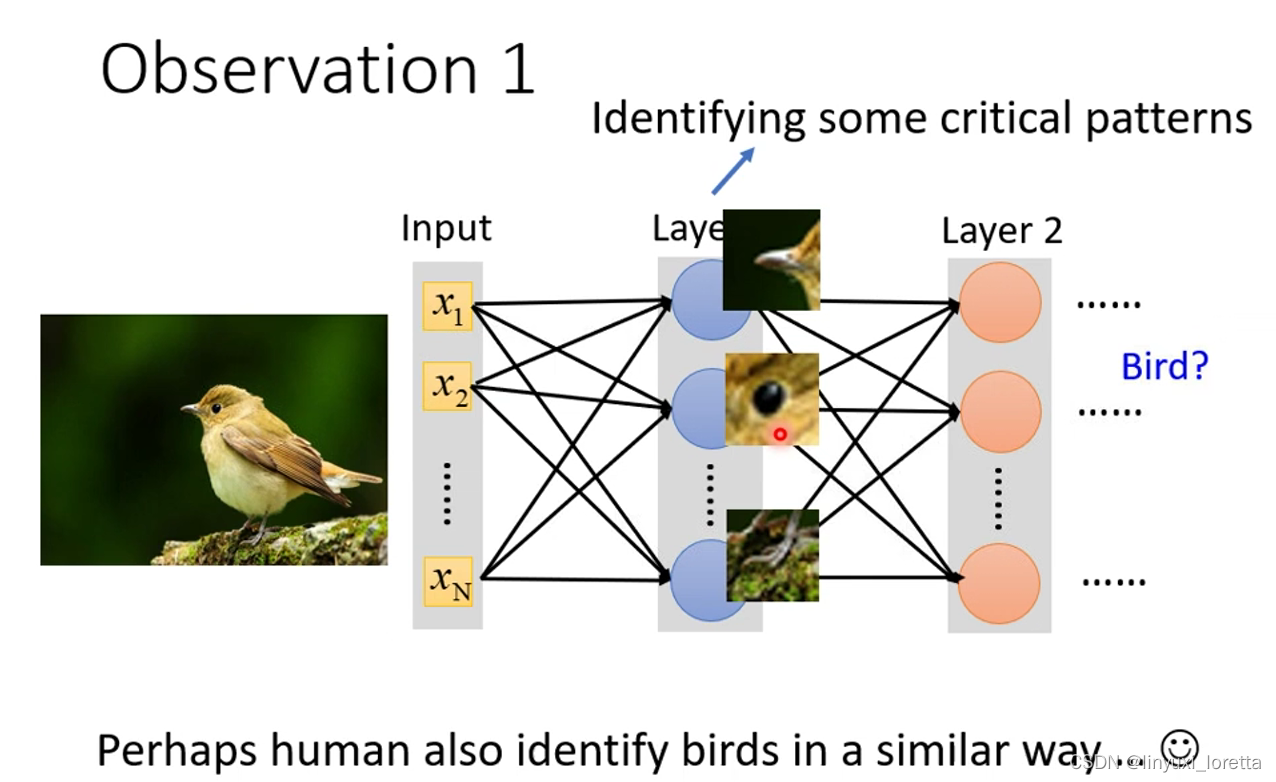
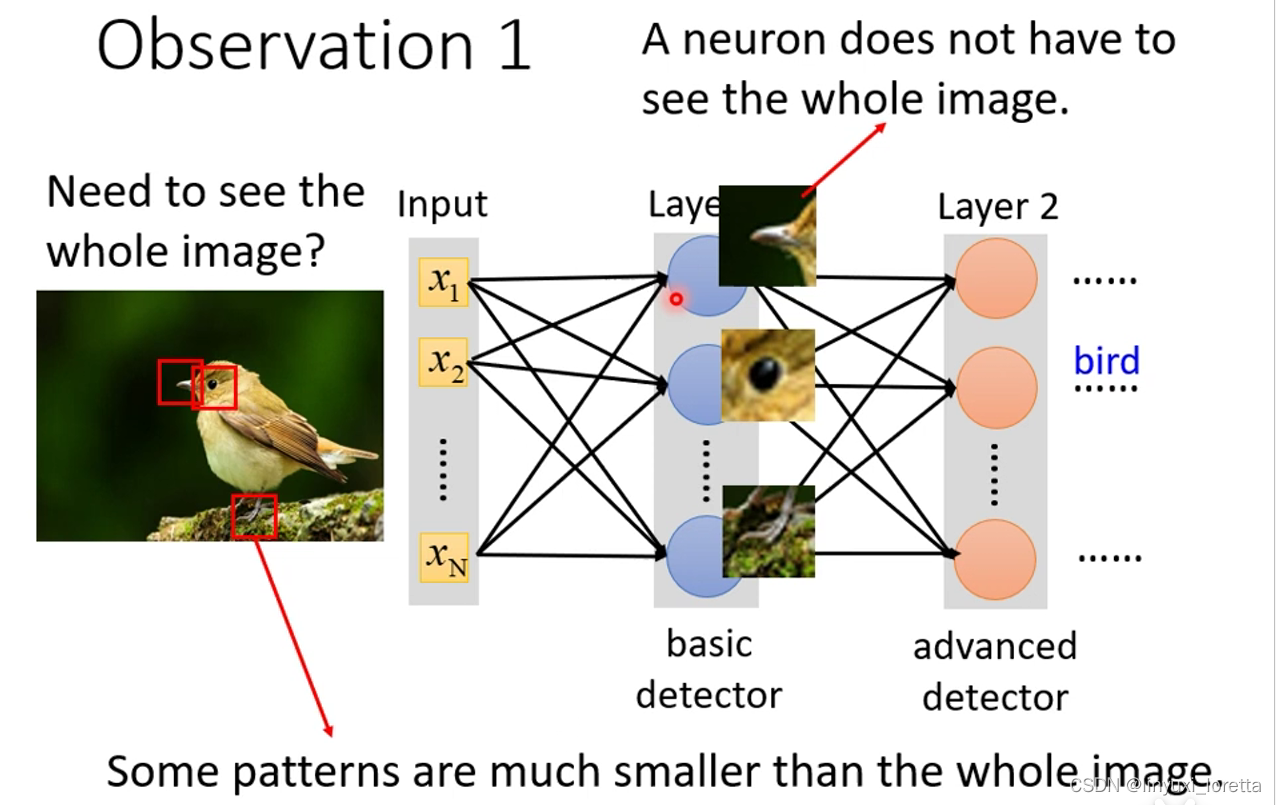
这些neuron只需要把图片的一小部分当作输入(receptive field(自己决定的)),就足以观察某些特别重要的pattern有没有出现了,
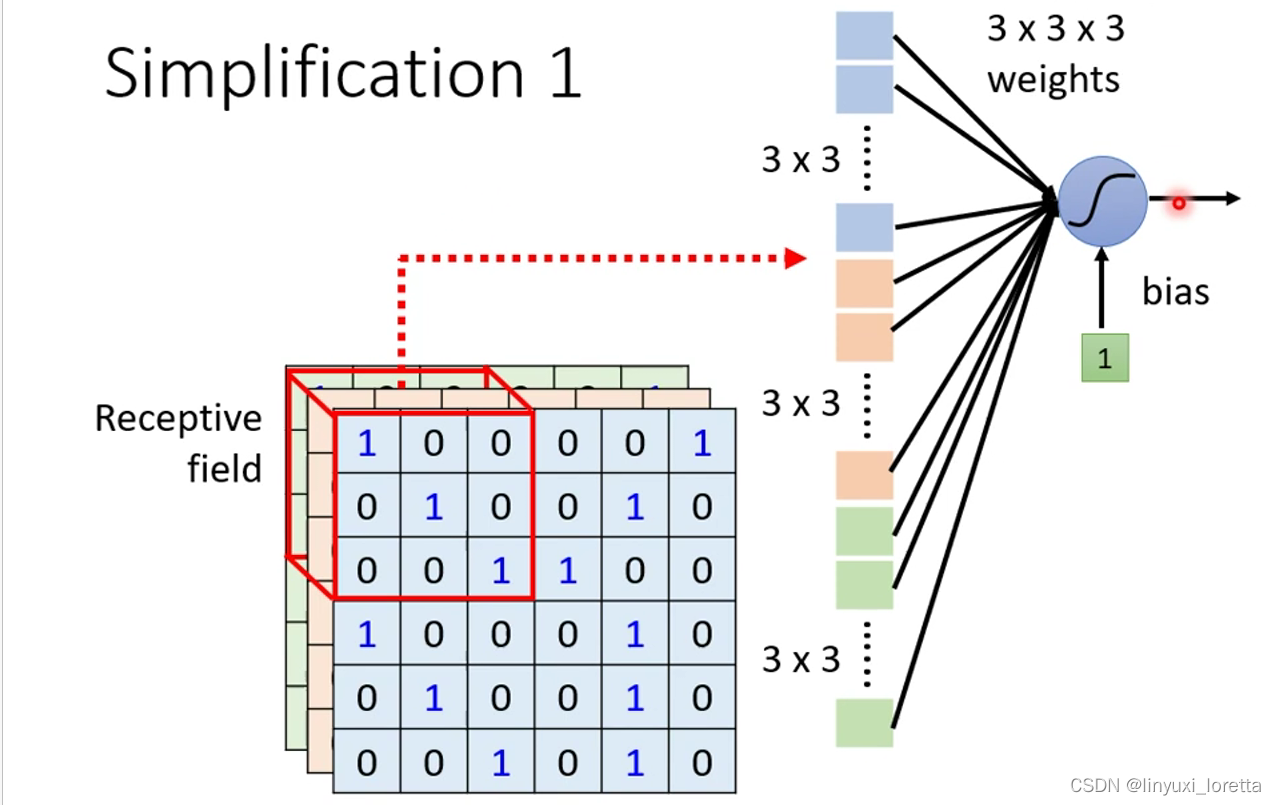
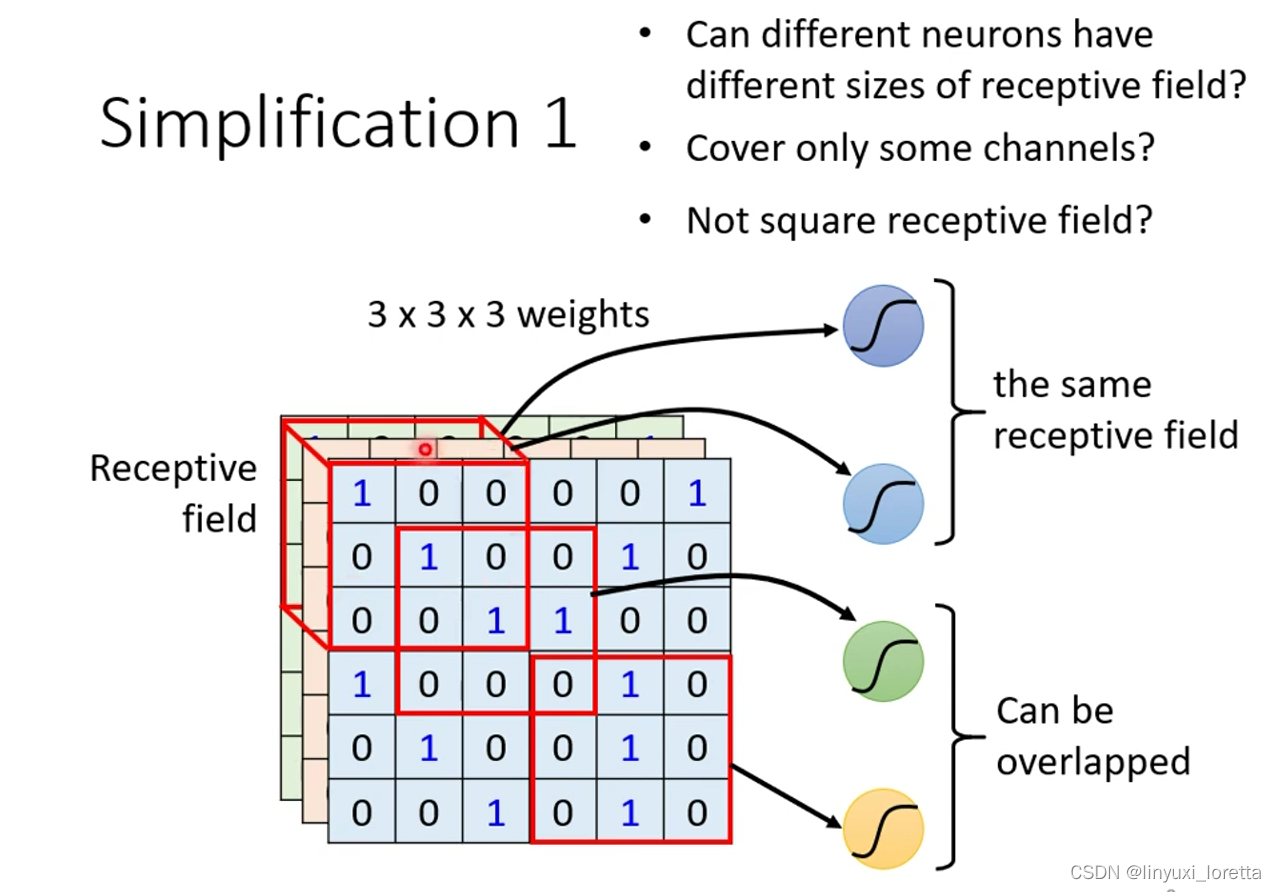
有的neuron只考虑一个channel的情况,也是可以的, 之后讲到network corporation时,会讲到这种架构。一般CNN里不常这样考虑
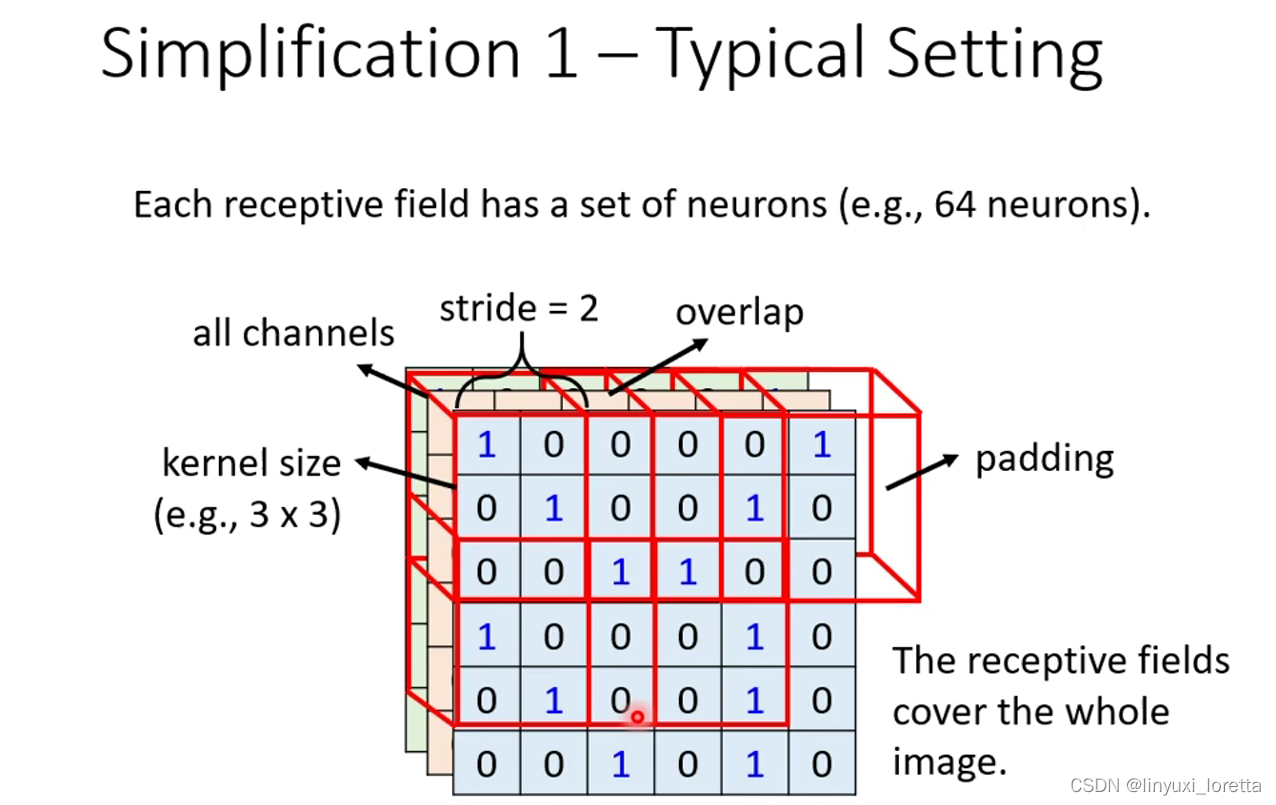
经典的 receptive field安排方式,会看所有的channel,高和宽合起来叫kernel size(一般不会设太大,3x3就足够了),
一般同一个receptive field会有一组neuron去守卫这个范围,
移动的量叫stride,自己决定的,往往不会设太大,1或2就可以了,因为希望receptive field之间是有重叠的
超出范围就做padding,补0,也有别的补植的方法,可以补整张图片里所有value的平均,可以拿边边的这些数字来补,etc.
观察2,同样的pattern可能出现在图片的不同区
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3011
3011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









