







论文阅读:T-Rex2: Towards Generic Object Detection via Text-Visual Prompt Synergy
text-visual prompts in open-set object detection
Abstract
提出了一种实用的开集目标检测模型T-Rex2。以往的基于文本提示的开集对象检测方法有效地封装了常见对象的抽象概念,但由于数据稀缺和描述性限制,难以实现稀有或复杂的对象表示。相反,视觉提示擅长通过具体的视觉例子来描述新奇的物体,但不能像文本提示那样有效地传达物体的抽象概念。认识到文本提示和视觉提示的互补优势和劣势,我们引入了T-Rex2,它通过对比学习在单个模型中协同这两个提示。T-Rex2接受各种格式的输入,包括文本提示、视觉提示以及两者的组合,因此它可以通过在两种提示模式之间切换来处理不同的场景。综合实验表明,T-Rex2在多种场景下都表现出了卓越的零镜头目标检测能力。我们表明,文本提示和视觉提示可以在协同中相互受益,这对于覆盖大量复杂的现实世界场景和为通用对象检测铺平道路是必不可少的。模型应用编程接口现已在https://github.com/IDEA-Research/T-Rex.上提供
1. Introduction
对象检测是计算机视觉的基础支柱,旨在定位和识别图像中的对象。传统上,对象检测是在闭集范式[1、6、16、21、23、34、35、42、49、53、55]内操作的,其中预定义的类别集是先验已知的,并且系统被训练以识别和检测来自这一集中的对象。然而,现实世界不断变化和不可预测的本质要求物体检测方法学向开放式范式转变。
开放集对象检测代表了一种重大的范式转变,通过使模型能够识别预定类别集之外的对象,超越了封闭集检测的局限性。一种流行的方法是使用文本提示进行开放词汇对象检测[5,7,11,19,24,28,54]。这种方法通常涉及从CLIP [32]或BERT [3]等语言模型中提取知识,以将文本描述与视觉表示保持一致。
虽然使用文本提示在开放集检测中因其抽象描述对象的能力而受到青睐,但它仍然面临以下限制。
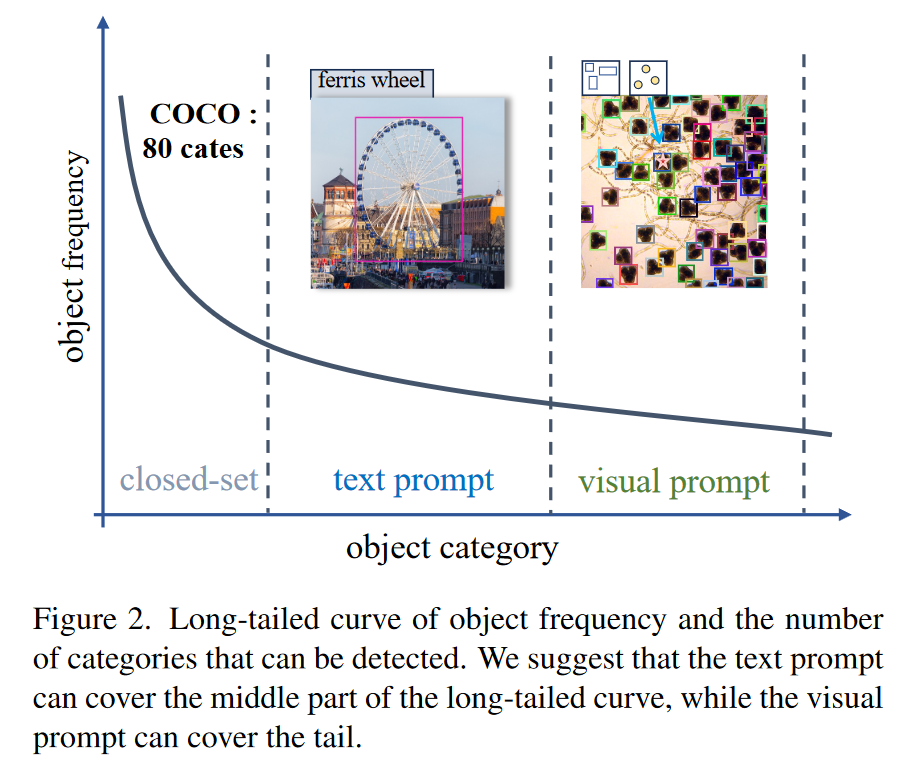
1)长尾数据短缺。文本提示的训练需要视觉表征之间的通道对齐,然而,长尾对象数据的稀缺可能会影响学习效率。如图2所示,对象的分布固有地遵循长尾模式,即,随着可检测对象的种类增加,这些对象的可用数据变得越来越稀缺。这种数据稀缺可能会削弱模型识别稀有或新奇物体的能力。
2)描述性限制。文字提示也不能准确地描述用语言难以描述的对象。例如,如图2所示,虽然文本提示符可以有效地描述摩天轮(ferris wheel),但在没有生物学知识的情况下,它可能难以准确地表示显微镜图像中的微生物(the microorganisms in the microscope image)。
相反,视觉提示[10,12,17,18,44,56]通过提供视觉示例来提供更直观和直接的方法来表示对象。例如,用户可以使用点或框来标记对象以进行检测,即使他们不知道对象是什么。此外,视觉提示不受跨模式对齐需求的限制,因为它们依赖于视觉相似性而不是语言相关性,使其能够应用于训练期间未遇到的新颖对象。
尽管如此,视觉提示也表现出局限性,因为与文本提示相比,它们在捕捉对象的一般概念方面效率较低。例如,作为文本提示的狗一词广泛涵盖了所有狗品种。相比之下,考虑到狗的品种、大小和颜色的巨大多样性,视觉提示需要全面的图像收集来在视觉上传达狗(dog)的抽象概念。
认识到文本提示和视觉提示的优势和劣势互补,我们引入了TRex2,这是一个集成了这两种模式的通用开放集目标检测模型。T-Rex2建立在DETR[1]架构之上,这是一个端到端的目标检测模型。它结合了两个并行编码器来对文本和视觉提示进行编码。对于文本提示,我们利用CLIP[32]的文本编码器将输入文本编码为文本嵌入。对于视觉提示,我们介绍了一种新型的视觉提示编码器,它配备了可变形的注意[55],可以将输入的视觉提示(点或框)在单个图像上或跨多个图像转换为视觉提示嵌入。为了促进这两种提示模式的协作,我们提出了一个对比学习模块[9,32],它可以显式地对齐文本提示和视觉提示。在对齐期间,视觉提示可以受益于文本提示固有的概括性和抽象能力。相反,文本提示可以通过查看各种视觉提示来增强其描述能力。这种迭代交互允许视觉提示和文本提示不断发展,从而提高了它们在一个模型中的通用理解能力。
T-Rex 2支持四种独特的工作流程,可应用于各种场景:
-
交互式视觉提示工作流程,允许用户通过当前图像上的框或点指定给定视觉示例要检测的对象;
-
通用视觉提示工作流程,允许用户通过视觉提示跨多个图像定义特定对象,从而创建适用于其他图像的通用视觉嵌入;
-
文本提示工作流程,使用户能够使用描述性文本进行开放词汇对象检测;
-
混合提示工作流程,结合文本和视觉提示进行联合推理。
T-Rex 2表现出强大的物体检测能力,并在COCO [20]、LVIS [8]、OdinW [15]和Roboflow 100 [2]上取得了显着的成绩,所有这些都是在zero-shot设置下。通过我们的分析,我们观察到文本和视觉提示发挥着补充作用,在另一种可能不那么有效的情况下,两者都表现出色。具体来说,文本提示特别擅长识别常见对象,而视觉提示在可能不容易通过语言描述的罕见对象或场景中表现出色。这种互补关系使该模型能够在广泛的场景中有效执行。总而言之,我们的贡献有三方面:
- 我们提出了一个开放式对象检测模型T-Rex 2,将文本和视觉提示统一在一个框架内,展示了在各种场景下强大的zero-shot能力。
- 我们提出了一个对比学习模块来显式地对齐文本和视觉提示,这导致这两种模式的相互增强。
- 大量实验证明了将文本和视觉提示统一在一个模型中的好处。我们还揭示了每种类型的提示都可以涵盖不同的场景,这些场景共同显示了向通用对象检测迈进的希望。
3. T-Rex2 Model
T-Rex 2集成了四个组件,如图3所示:i)图像编码器,ii)视觉提示编码器,iii)文本提示编码器,iv)框解码器。T-Rex 2遵循DETR [1]的设计原则,这是一种端到端物体检测模型。这四个组件共同促进了四个不同的工作流程,其中涵盖了广泛的应用场景。
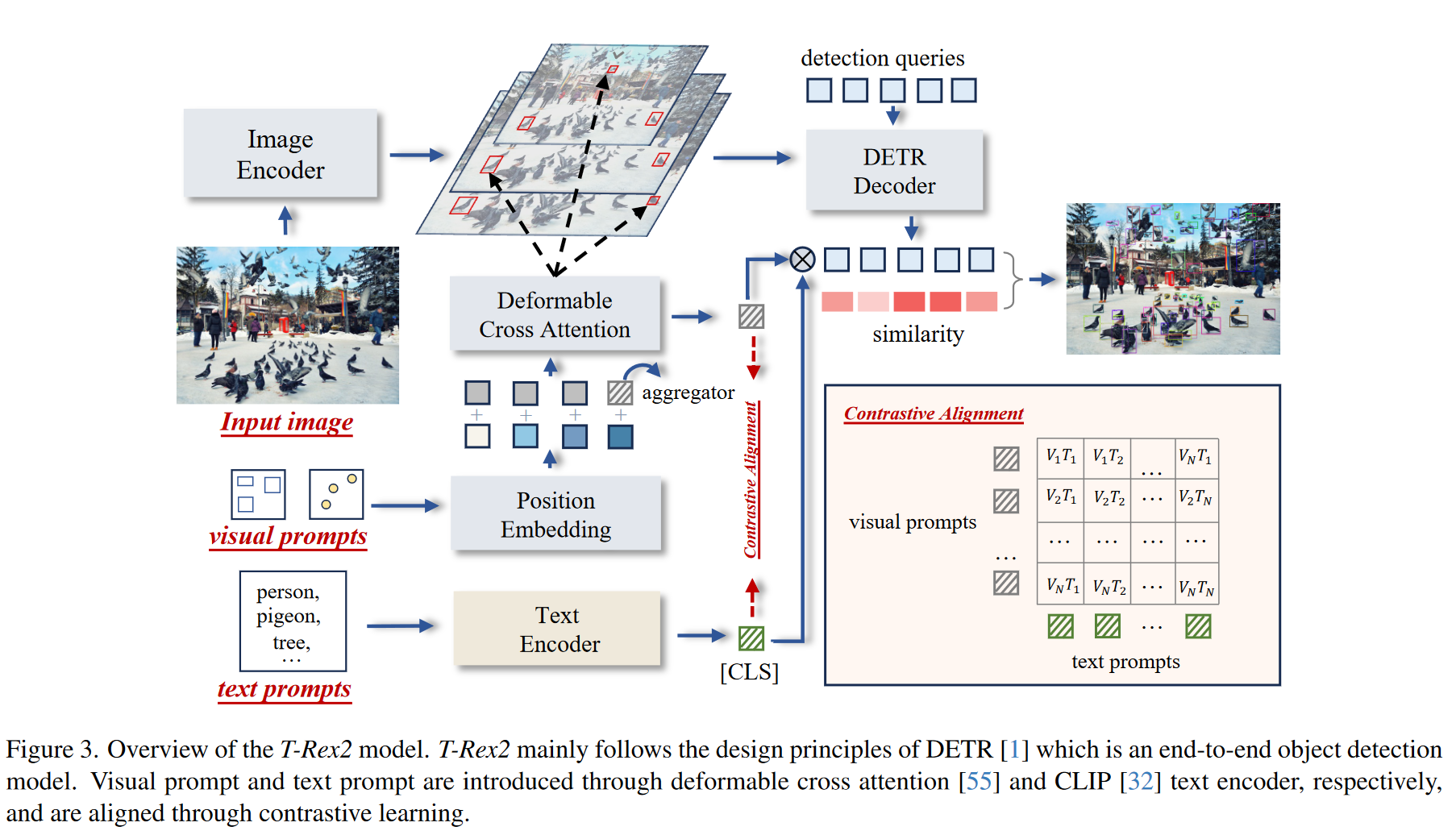
3.1. Visual-Text Promptable Object Detection
Image Encoder. T-Rex 2中的图像编码器follow了可Deformable DETR [55]框架,由视觉主干(例如Swin Transformer [25])组成,该主干从输入图像中提取多尺度特征图。随后是配备deformable self-attention[55]的几个Transformer编码器层[4],它们用于细化这些提取的特征地图。从图像编码器输出的特征地图被表示为 f i ∈ R C i × H i × W i , i ∈ { 1 , 2 , … , L } f_i\in\mathbb{R}^{C_i\times H_i\times W_i},i\in \{1, 2, \dots, L\} fi∈RCi×Hi×Wi,i∈{1,2,…,L},其中 L L L 是特征地图层的数量。
Visual Prompt Encoder 视觉提示已广泛用于交互式分割[12,18,56],但尚未在对象检测领域得到充分探索。我们的方法结合了框和点格式的视觉提示。设计原则涉及将用户指定的视觉提示从其坐标空间转换到图像特征空间。给定K个用户指定的4D规范化框
b
j
=
(
x
j
,
y
j
,
w
j
,
h
j
)
,
j
∈
{
1
,
2
,
.
.
.
,
K
}
b_j = (x_j,y_j,w_j,h_j),j \in \{1,2,...,K\}
bj=(xj,yj,wj,hj),j∈{1,2,...,K},或2D正规化点
p
j
=
(
x
j
,
y
j
)
,
j
∈
{
1
,
2
,
.
.
.
,
K
}
p_j = (x_j,y_j),j \in \{1,2,...,K\}
pj=(xj,yj),j∈{1,2,...,K}。在参考图像上,我们最初通过固定的sin-cos嵌入层将这些坐标输入编码到位置嵌入中。随后,使用两个不同的线性层将这些嵌入投影到统一维度中:
B
=
L
i
n
e
a
r
(
P
E
(
b
1
,
.
.
.
b
K
)
;
θ
B
)
:
R
K
×
4
D
→
R
K
×
D
B=\mathrm{Linear}(\mathrm{PE}(b_1,...b_K);\theta_B):\mathbb{R}^{K\times4D}\to\mathbb{R}^{K\times D}
B=Linear(PE(b1,...bK);θB):RK×4D→RK×D
P = L i n e a r ( P E ( p 1 , . . . p K ) ; θ P ) : R K × 2 D → R K × D P=\mathrm{Linear}(\mathrm{PE}(p_1,...p_K);\theta_P):\mathbb{R}^{K\times2D}\to\mathbb{R}^{K\times D} P=Linear(PE(p1,...pK);θP):RK×2D→RK×D
其中
P
E
(
⋅
)
\mathrm{PE(\cdot)}
PE(⋅) 代表位置嵌入,
L
i
n
e
a
r
(
⋅
;
θ
)
\mathrm{Linear} (\cdot;\theta)
Linear(⋅;θ)表示具有参数
θ
\theta
θ 的线性项目操作。与之前将点视为宽度和高度最小的框的方法[18]不同,我们将框和点建模为不同的提示类型。然后,我们启动一个可学习的内容嵌入(initiate a learnable content embedding),该嵌入被广播
K
K
K 次,表示为
C
∈
R
K
×
D
C\in\mathbb{R}^{K\times D}
C∈RK×D。此外,还利用通用类标记
C
′
∈
R
1
×
D
C^{\prime}\in\mathbb{R}^{1\times D}
C′∈R1×D 来聚合来自其他视觉提示的特征,以适应用户可能在单个图像中提供多个视觉提示的场景。这些内容嵌入沿着通道维度与位置嵌入相连接,并应用线性层进行投影,从而构建输入查询嵌入
Q
Q
Q:
Q
=
{
Linear
(
CAT
(
[
C
;
C
′
]
,
[
B
;
B
′
]
)
;
φ
B
)
,
box
Linear
(
CAT
(
[
C
;
C
′
]
,
[
P
;
P
′
]
)
;
φ
P
)
,
point
Q=\begin{cases}\text{Linear}\left(\text{CAT}\left(\left[C;C'\right],\left[B;B'\right]\right);\varphi_B\right),\text{box}\\\text{Linear}\left(\text{CAT}\left(\left[C;C'\right],\left[P;P'\right]\right);\varphi_P\right),\text{point}\end{cases}
Q={Linear(CAT([C;C′],[B;B′]);φB),boxLinear(CAT([C;C′],[P;P′]);φP),point
其中
C
A
T
\mathrm{CAT}
CAT 代表channel维度的级联。
B
′
B'
B′ 和
P
′
P'
P′ 代表全局位置嵌入,其源自全局正规化坐标(global normalized coordinates)
[
0.5
,
0.5
,
1
,
1
]
[0.5, 0.5, 1, 1]
[0.5,0.5,1,1] 和
[
0.5
,
0.5
]
[0.5,0.5]
[0.5,0.5]。全局query的目的是聚合其他query的特征。随后,我们采用多尺度可变形交叉注意力[55]层以视觉提示为条件,从多尺度特征地图中提取视觉提示特征。对于第j个prompt,交叉注意后的查询特征
Q
j
′
Q'_j
Qj′ 算为:
Q
j
′
=
{
MSDeformAttn
(
Q
j
,
b
j
,
{
f
i
}
i
=
1
L
)
,
box
MSDeformAttn
(
Q
j
,
p
j
,
{
f
i
}
i
=
1
L
)
,
point
Q_j^{\prime}=\begin{cases}\text{MSDeformAttn}(Q_j,b_j,\{\boldsymbol{f}_i\}_{i=1}^L),\text{box}\\\text{MSDeformAttn}(Q_j,p_j,\{\boldsymbol{f}_i\}_{i=1}^L),\text{point}\end{cases}
Qj′={MSDeformAttn(Qj,bj,{fi}i=1L),boxMSDeformAttn(Qj,pj,{fi}i=1L),point
Deformable attention [55]最初用于解决DETR [1]中遇到的缓慢收敛问题。在我们的方法中,我们将可变形的注意力设置在视觉提示的坐标上,即,每个查询将选择性地关注包含视觉提示周围区域的有限的一组多尺度图像特征。这确保捕获表示感兴趣对象的视觉提示嵌入。在提取过程之后,我们使用自我注意层来调节不同查询之间的关系,并使用前向层进行投影。全局内容查询的输出将用作最终的视觉提示嵌入
V
V
V。
V
=
F
F
N
(
S
e
l
f
A
t
t
n
(
Q
′
)
)
[
−
1
]
V=\mathrm{FFN}(\mathrm{SelfAttn}(Q^{\prime}))[-1]
V=FFN(SelfAttn(Q′))[−1]
Text Prompt Encoder 我们使用CLIP [32]的文本编码器来编码类别名称或短短语,并使用[CLS]标记输出作为文本提示嵌入,标记为
T
T
T。
Box Decoder 我们使用类似DETR的解码器进行box预测。遵循DINO [49],每个查询都被公式化为4D锚点坐标,并在解码器层之间进行迭代细化。我们使用Grounding DINO [24]中提出的查询选择层来初始化锚点坐标
(
x
,
y
,
w
,
h
)
(x, y, w,h)
(x,y,w,h)。具体来说,我们计算encoder feature和prompt embedding之间的相似度,并选择相似度为前900的索引来初始化位置嵌入。随后,检测query利用deformable cross-attention[55]来聚焦于编码的多尺度图像特征,并用于预测每个解码器层的锚点偏差(anchor offsets)
(
Δ
x
,
Δ
y
,
Δ
w
,
Δ
h
)
(\Delta x,\Delta y,\Delta w,\Delta h)
(Δx,Δy,Δw,Δh)。最终的预测框是通过将anchors和offsets相加来获得的:
(
Δ
x
,
Δ
y
,
Δ
w
,
Δ
h
)
=
M
L
P
(
Q
d
e
c
)
Box
=
(
x
+
Δ
x
,
y
+
Δ
y
,
w
+
Δ
w
,
h
+
Δ
h
)
(\Delta x,\Delta y,\Delta w,\Delta h)=\mathrm{MLP}(Q_{dec})\\\text{Box}=(x+\Delta x,y+\Delta y,w+\Delta w,h+\Delta h)
(Δx,Δy,Δw,Δh)=MLP(Qdec)Box=(x+Δx,y+Δy,w+Δw,h+Δh)
其中
Q
d
e
c
Q_{dec}
Qdec是来自Box Decoder的预测查询。我们没有使用可学习的线性层来预测类别标签,而是遵循之前的开放集对象检测方法[19,24],而是利用提示嵌入作为分类层的权重:
L
a
b
e
l
=
V
⋅
Q
d
e
c
T
:
R
C
×
D
×
R
D
×
N
→
R
C
×
N
\mathrm{Label}=V\cdot Q_{dec}^T:\mathbb{R}^{C\times D}\times\mathbb{R}^{D\times N}\to\mathbb{R}^{C\times N}
Label=V⋅QdecT:RC×D×RD×N→RC×N
其中
C
C
C 表示visual prompt类的总数,
N
N
N 表示检测查询的数量。
visual prompt对象检测和open-vocabulary对象检测任务共享相同的image encoder 和 box decoder。
3.2. Region-Level Contrastive Alignment
为了将视觉提示和文本提示集成到一个模型中,我们采用区域级对比学习来协调这两种模式。具体来说,给定输入图像和
K
K
K 个视觉提示嵌入
V
=
(
v
1
,
.
.
.
,
v
K
)
V~=~(v_1,...,v_K)
V = (v1,...,vK) 从视觉提示编码器中提取,以及文本提示嵌入
T
=
(
t
1
,
.
.
.
,
t
K
)
T = (t_{1},...,t_{K})
T=(t1,...,tK)对于每个提示区域,我们计算两种类型嵌入之间的InfoNSO损失[30]:
L
a
l
i
g
n
=
−
1
K
∑
i
=
1
K
log
exp
(
v
i
⋅
t
i
)
∑
j
=
1
K
exp
(
v
i
⋅
t
j
)
\mathcal{L}_{align}=-\frac1K\sum_{i=1}^K\log\frac{\exp(v_i\cdot t_i)}{\sum_{j=1}^K\exp(v_i\cdot t_j)}
Lalign=−K1i=1∑Klog∑j=1Kexp(vi⋅tj)exp(vi⋅ti)
对比对齐可以被视为一个相互蒸馏的过程,每个模式都有助于知识的交流并从中受益。具体来说,文本提示可以被视为一个概念anchor,各种视觉提示可以围绕它聚合,以便视觉提示可以获得常识。相反,视觉提示充当文本提示的持续细化来源。通过接触各种视觉实例,文本提示被动态更新和增强,获得深度和细微差别。
3.3. Training Strategy and Objective
Visual prompt training strategy 对于视觉提示训练,我们采用“当前图像提示,当前图像检测”(current image prompt, current image detect)的策略。具体来说,对于训练集图像中的每个类别,我们随机选择一个到所有可用的GT框来用作视觉提示。我们将这些GT box转换为它们的中心点,有50%的机会进行点提示训练。虽然使用来自不同图像的视觉提示进行交叉图像检测训练似乎更有效,但由于数据集之间的标签空间不一致,创建此类图像对在开放集场景中带来了挑战。尽管简单,但我们简单的训练策略仍然具有强大的概括能力。
Text prompt training strategy T-Rex 2使用检测数据和 Grounding 数据进行文本提示训练。对于检测数据,我们使用当前图像中的类别名称作为正面文本提示,并随机采样剩余类别中的负面文本提示。对于 Grounding 数据,我们提取与边界框对应的积极短语,并排除标题中的其他单词以进行文本输入。遵循DetCLIP [46,47]的方法,我们维护一个全局词典来采样基础数据的负面文本提示,这些提示与正面文本提示相关联。该全局词典是通过选择文本提示训练数据中出现超过100次的类别名称和短语名称来构建的。
Training objective 我们使用L1损失和GIOU [36]损失进行箱回归。对于分类损失,遵循Grounding DINO [24],我们应用对比损失,该损失测量预测对象和提示嵌入之间的差异。具体来说,我们通过点积计算每个检测查询与视觉提示或文本提示嵌入之间的相似性,以预测logit,然后计算每个 logit 的 sigmoid focal loss[21]。box回归和分类损失最初用于预测和GGT之间的bipartite matching[1]。随后,我们计算GT和匹配预测之间的final losses,并纳入相同的损失成分。我们在每个解码器层之后和编码器输出之后使用auxiliary loss。继DINO [49]之后,我们还使用去噪训练来加速收敛。最终的损失采取以下形式:
L
t
o
t
a
l
=
L
c
l
s
+
L
L
l
+
L
G
l
o
U
+
L
D
N
+
L
a
l
i
g
n
\mathcal{L}_{{\mathrm{total}}}=\mathcal{L}_{{\mathrm{cls}}}+\mathcal{L}_{{\mathrm{Ll}}}+\mathcal{L}_{{\mathrm{GloU}}}+\mathcal{L}_{{\mathrm{DN}}}+\mathcal{L}_{{\mathrm{align}}}
Ltotal=Lcls+LLl+LGloU+LDN+Lalign
我们采用循环训练策略,在连续迭代中在文本提示和视觉提示之间交替。
3.4. Four Inference Workflows
T-Rex 2通过以不同的方式组合文本提示和视觉提示,提供四种不同的工作流程。
文本提示工作流程 该工作流程专门使用文本提示进行对象检测,这与开放词汇对象检测相同。该工作流程适合常见对象的检测,其中文本提示可以提供清晰的描述。
交互式视觉提示工作流程 该工作流程是围绕用户驱动的交互性的核心原则设计的。给定来自用户提供的提示的T-Rex 2的初始输出,用户可以根据可视化结果通过添加有关错过或错误检测到的对象的额外提示来细化检测结果。这个迭代周期允许用户交互式地微调T-Rex 2的性能,确保精确检测。这种交互过程保持快速且资源高效,因为T-Rex 2是一种后期融合模型,只需要图像编码器转发一次。
通用视觉提示工作流程 在此工作流程中,用户可以通过向T-Rex 2提示任意数量的示例图像来定制特定对象的视觉嵌入。这种能力对于通用对象检测至关重要,因为一类对象可能具有非常多样化的实例,因此我们需要一定数量的视觉示例来表示它。让
V
1
,
V
2
,
.
,
V
n
V_1,V_2,.,V_n
V1,V2,.,Vn 表示从
n
n
n 个不同图像获得的视觉嵌入,一般视觉嵌入
V
V
V 被计算为这些嵌入的平均值。
V
=
1
n
∑
i
=
1
n
V
i
V=\frac1n\sum_{i=1}^nV_i
V=n1i=1∑nVi
混合提示工作流程 视觉提示和文本提示对齐后,可以同时用于推理。这种融合是通过平均它们各自的嵌入来实现的。
P
m
i
x
e
d
=
T
+
V
2
P_{\mathrm{mixed}}=\frac{T+V}2
Pmixed=2T+V
在此工作流程中,文本提示有助于广泛的上下文理解,而视觉提示则添加了精确性和具体的视觉线索。
4. Experiments
4.1. Data Engines
对于每种模式,专门的数据引擎旨在策划适合其各自训练时需求的数据。
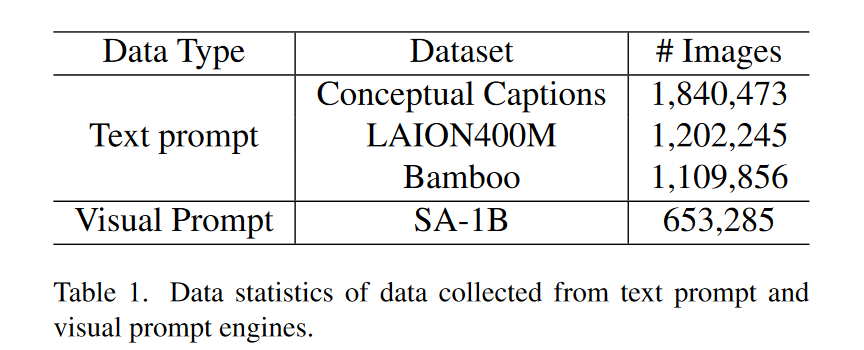
Data engine for text prompt T-Rex 2支持集成检测和 Grounding 数据以进行训练。在[19,24]之后,我们利用检测数据集Objects 365 [39]、OpenImages [13]以及基础数据集GoldG [11]进行训练。为了增强T-Rex 2的文本提示功能,我们还广泛使用来自图像字幕数据集和图像分类数据集的伪标签数据。具体来说,对于Conceptual Captions [40]和LAION 400 M [37]数据集中的图像说明数据,我们使用spaCy从图像说明中提取名词块,并使用这些名词块提示Grounding DINO [24]获取框。对于Bamboo [51]数据集中的图像分类数据,我们只需使用当前图像的类别来提示Grounding DINO [24]。我们总共使用3.15万个标记图像和3.39万个伪标记图像进行文本提示训练。
Data engine for visual prompt 视觉提示的训练过程是使用GT框的一部分或其在当前图像中的中心点作为输入。因此,我们可以利用已建立的检测数据集,包括Objects 365 [39]、OpenImages [13]、Hiertext [26]、CrowdHuman [38]进行初始训练。与此同时,为了使视觉提示的数据足够多样化,我们构建了一个数据引擎来从SA-1B获取数据[12]。该数据引擎通过自我训练循环运行,包括两个阶段:
1)初始训练阶段:在这个阶段,我们首先在上述数据集上训练仅具有视觉提示通道的T-Rex2的初始版本,使其具有初步的交互目标检测能力。
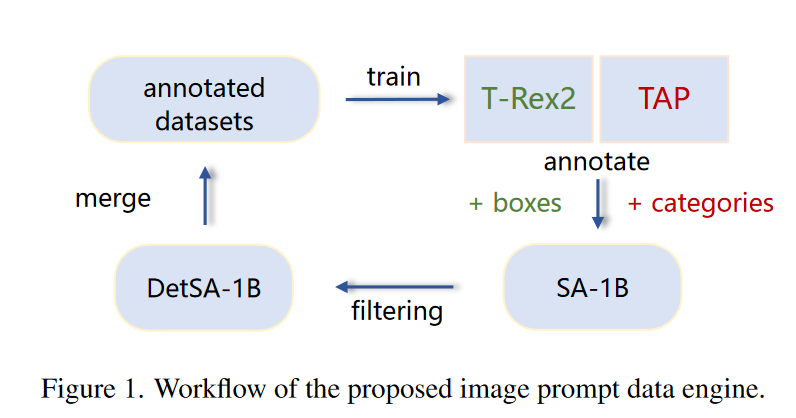
2)注解阶段:利用初始模型对SA-1B中的数据进行注解。SA-1B拥有巨大的方框,可以放置各种粒度的物体。但是,该框没有语义标签,不适合进行目标检测训练。因此,我们使用TAP[31]用来自2560个类别的词典中的类别名称来注释每个框。然后,我们采用如下过滤策略:如果一幅图像至少有一个类别的实例数大于某个阈值,则将其保留。然而,在SA-1B中,并不是所有的对象都有框,所以我们使用原始的GT框作为交互式视觉提示输入,并使用初始的T-Rex2来注释缺少标签的框。我们总共使用了240万张标记图像和0.65M张伪标记图像来进行视觉提示训练。
4.2. Model Details
T-Rex 2基于DINO [49]构建。我们利用Swin Transformer [25]作为视觉支柱,然后是六层Transformer编码器层。我们使用CLIP-B [32]作为文本编码器并对其进行微调。对于视觉提示编码器,我们堆叠了三层可变形交叉注意层,并将前向层的隐藏维度设置为1024。我们使用AdamW [27]作为优化器,并将主干和文本编码器的学习率设置为 1 e-5,所有其他模块的学习率设置为1 e-4。
4.3. Settings and Metrics
对于对象检测任务,我们在 zero-shot 设置下进行评估,即T-Rex 2不会在评估基准上进行训练。我们在COCO [20]、LVIS [8]、OodinW [15]和Roboflow 100 [2]上使用 AP 指标。COCO数据集包含80个常见类别。相比之下,LVIS数据集的特点是包含1203个类别的长尾类别分布。这些类别进一步分为三个不同的组:常见、常见和罕见,val分裂的比例为405:461:337,minival分裂的比例为389:345:70 [11]。OdinW和Roboflow 100数据集分别包含从Roboflow收集的35个和100个数据集,涵盖多种场景,包括空中、视频游戏、水下、文档、现实世界等,具有长尾类别。我们比较了不同工作流程下TRex 2的几种不同评估协议。
Text 在该协议中,我们使用基准的所有类别名称作为文本提示输入,这与之前的开放词汇对象检测设置一致。
Visual-G(Generic):在此协议中,T-Rex 2处理通用视觉提示工作流程。我们从每个类别的每个基准的训练集图像中提取视觉提示嵌入。以COCO为例,我们首先为每个至少有该类别的一个实例的类别随机抽样 N N N 张图像。接下来,我们使用每个图像的GT框作为视觉提示的输入,为每个类别提取 N N N 个视觉嵌入。随后,我们计算每个类别的这 N N N 个嵌入的平均值。这些平均视觉嵌入(总共80个嵌入)将用于评估。默认情况下, N N N 设置为16。对于每个测试图像,我们将重复此过程。
Visual-I(Interactive):在此协议中,T-Rex 2处理交互式视觉提示工作流程。给定一个测试图像,假设它有 M M M 个类别,那么对于每个类别,我们在当前图像中随机选择一个GT框(或将其转换为其中心点)作为该类别的视觉提示输入。该协议比Visual-G相对容易,因为我们提前知道测试集图像的类别,并且提供了GT box。然而,尽管交互式对象检测很简单,但它具有广泛的应用场景,包括自动注释、对象计数等。
4.4. Zero-Shot Generic Object Detection
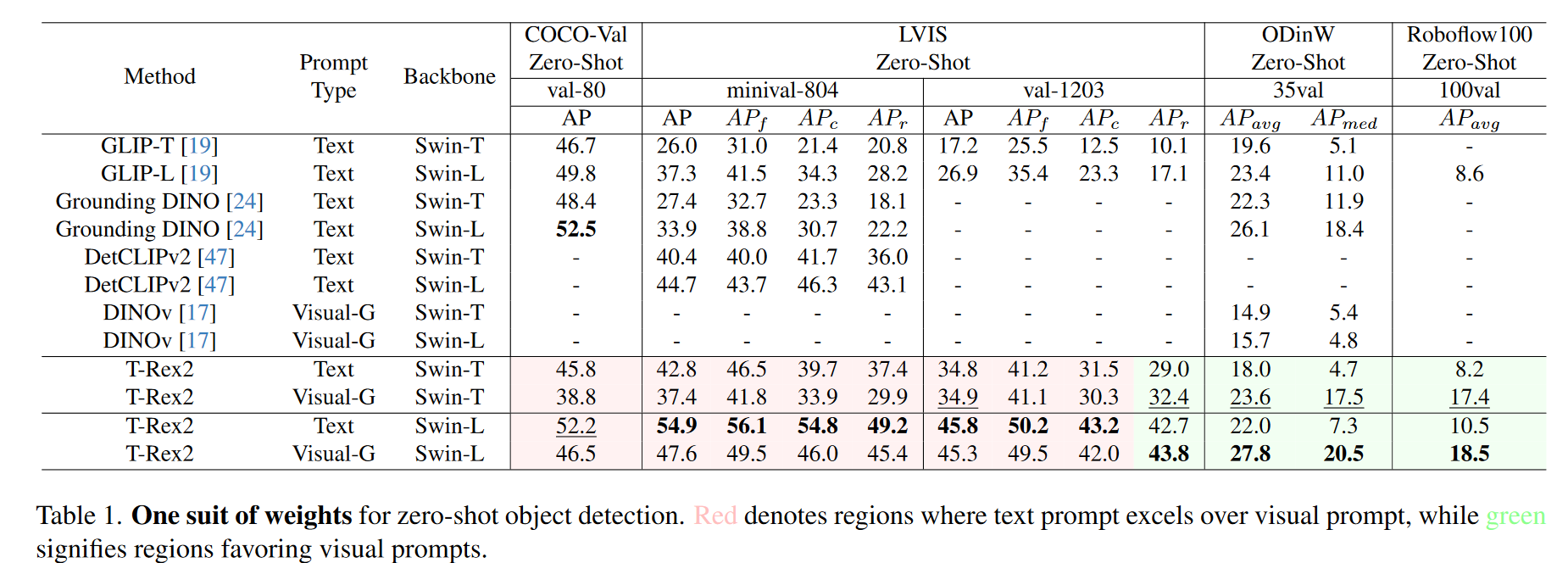
在这项研究中,我们将通过四个不同的基准测试来探索T-Rex2的 zero-shot 目标检测能力:COCO、LVIS、ODinW和Roboflow 100。“zero-shot”一词指的是一种方法论方法,即评价基准在模型的培训阶段没有暴露在模型中,可能包括新的类别和图像分布。如表1中所示,我们观察到文本提示和视觉提示可以分别覆盖不同的场景。文本提示在具有相对常见类别的场景中表现出卓越的性能。例如,在通用视觉提示和Swin-T主干设置下,文本提示在Coco(80个类别)上比视觉提示高出7个AP点。同样,在LVIS-Minival(804个类别)中,文本提示比视觉提示获得5.4AP点的优势。相反,在以长尾分布为特征的场景中,与文本提示相比,视觉提示表现出更稳健的性能。具体地说,在LVIS-Val(1203个类别)上,视觉提示在Rare组领先3.4AP点,在ODinW组领先5.6AP点,在Roboflow 100组领先9.2AP点,这突显了其在处理不常见对象方面的有效性。
在图4中,我们展示了LVIS基准测试上视觉提示和文本提示之间的每个类别AP差异。我们按照其在训练集中出现频率的降序对LVIS数据集的类别进行排名。我们的分析表明,文本提示在识别出现频率较高的常见类别方面表现更好。相比之下,随着频率的降低,视觉提示更擅长识别更罕见的类别。这表明文本提示适合常见概念,而视觉提示对于罕见类别更有效。
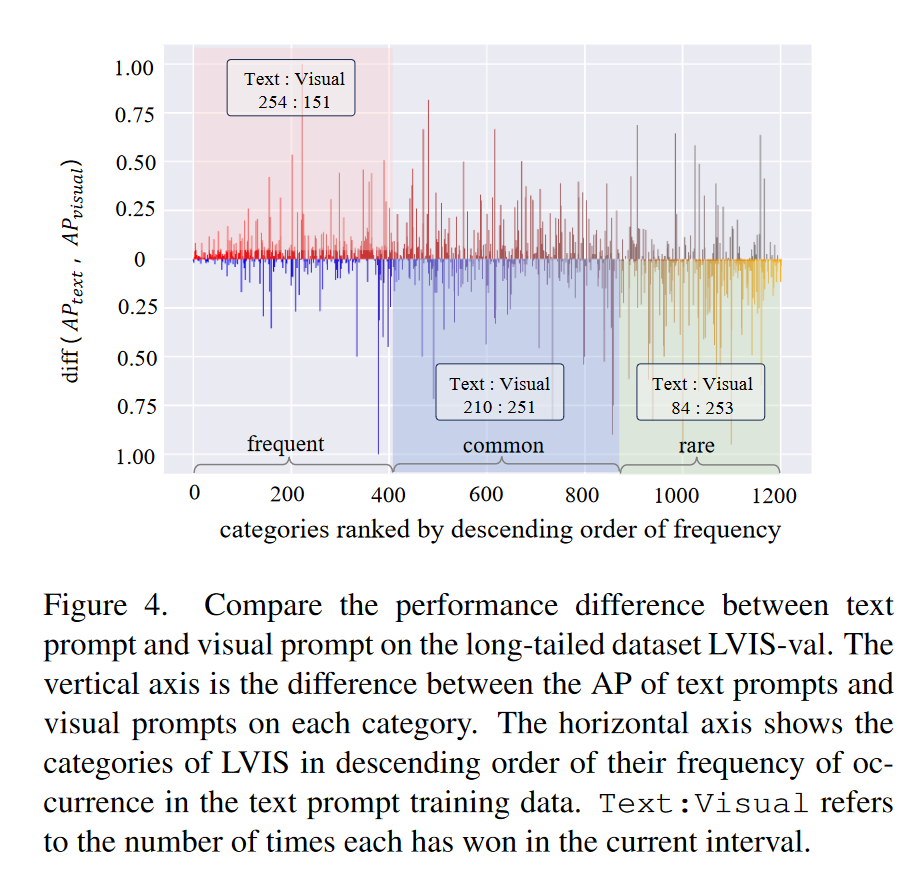
图4.比较长尾数据集LVIS-val上文本提示和视觉提示之间的性能差异。垂直轴是每个类别上文本提示和视觉提示的AP之间的差异。水平轴按文本提示训练数据中出现频率的降序显示LVIS类别。Text:Visual是指每个人在当前间隔中获胜的次数。
4.5. Zero-Shot Interactive Object Detection
T-Rex2还展示了强大的交互式对象检测能力。如表2中所示。2、交互视觉提示显著优于文本提示和一般视觉提示策略。然而,这种比较可能并不完全公平,因为在Visual-I设置下,我们对测试图像中存在的类别具有先验知识。
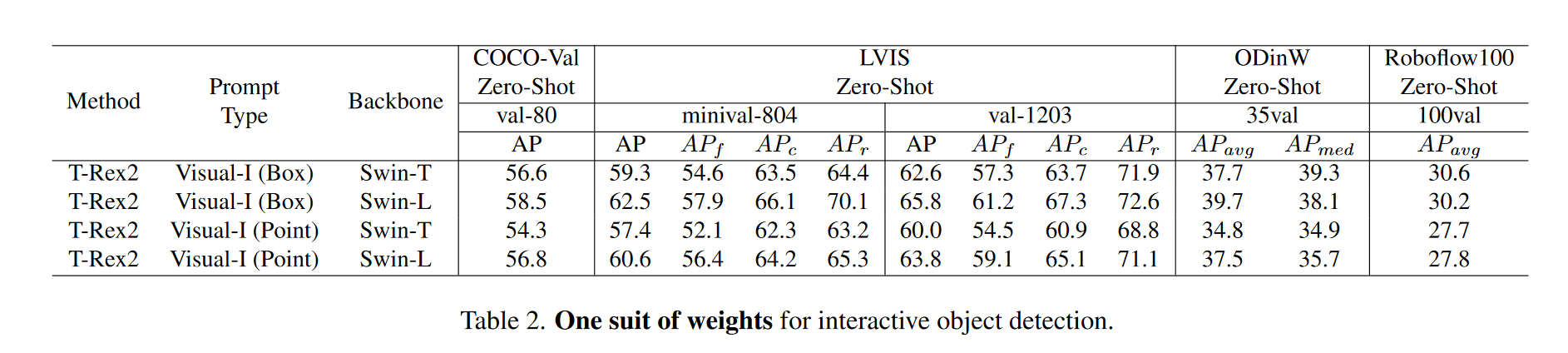
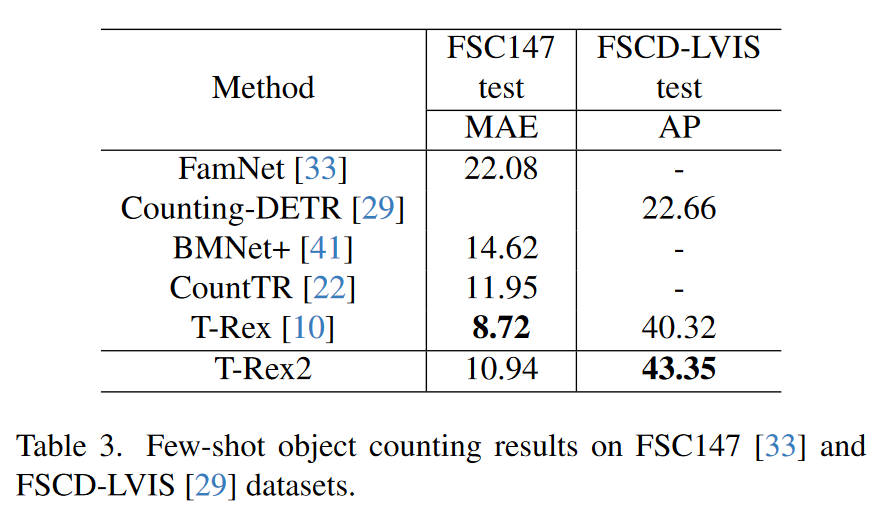
为了提供更多的洞察力,我们在少镜头物体计数任务中评估了T-Rex2。在该任务[10,22,29,41]中,每个测试图像将被提供目标对象的三个视觉样本框,并且需要输出目标对象的编号。我们在FSC147[33]和FSCD-LVIS[29]数据集上进行了评估。这两个数据集都包含具有密集填充的小对象的场景。具体地说,FSC147通常以单目标场景为特征,其中每个图像通常只存在一种类型的对象,而FSCDLVIS主要包括多目标图像。我们报告了FSC147的平均平均误差(MAE)度量和FSCD-LVIS的AP度量。在前人工作[10]的基础上,我们使用视觉样本框作为交互的视觉提示。如表3中所示,T-Rex2算法与以前的SOTA算法T-Rex相比取得了与之相当的结果。虽然在MAE方面比不上T-Rex,但T-Rex2在AP方面比T-Rex表现得更好,后者衡量了总体检测精度。这一结果表明,TRex2的交互能力在密集和小对象场景中具有很高的能力。
4.6. Ablation Experiments
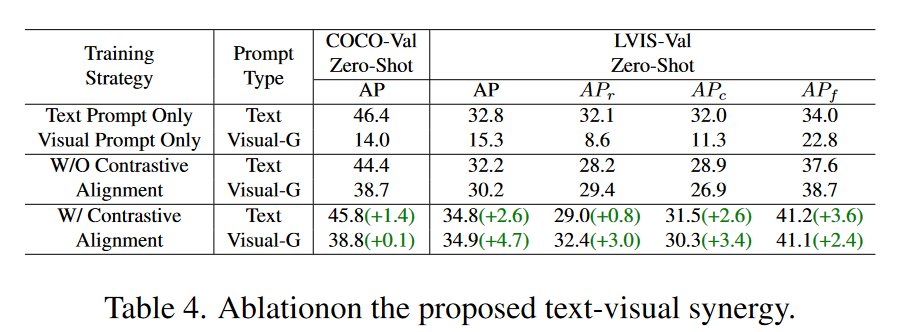
Ablation of naive joint training 如表4中所示(前两行),当两个提示通道单独训练时,视觉提示的一般检测能力显著较差(COCO上14.0AP,LVIS-VAL上15.3AP)。问题的核心在于视觉数据的多样性和变异性。例如,当模型试图理解 chair 是由什么组成的时候,模型看到的每个例子都与上一个截然不同。如果没有一致的上下文,模型很难仅通过视觉提示来形成一般概念。在联合培训时(表4中的后两行),视觉提示的效能显著提高。这一改进表明,文本上下文与视觉数据的结合有助于模型形成更稳定和可概括的表示。然而,两个提示之间没有明确对齐的朴素的联合训练在一定程度上降低了文本提示的有效性,因为AP on Coco和LVIS都有所下降。
观察到的文本提示能力下降可能是由于多任务学习的复杂性增加。我们使用t-SNE [43]来可视化图5a中文本提示和视觉提示嵌入的分布。我们发现相应的文本提示和视觉提示嵌入在特征空间中是分开的,而不是聚集的。因此,区域特征无法同时与文本提示和视觉提示对齐,从而使学习过程更具挑战性。

Ablations of contrastive alignment 如表4中所示(最后两行),采用对比对齐可以提高文本和视觉提示的性能。通过对比对齐,文本提示和视觉提示之间的分布更加结构化,如图5 b所示:文本提示充当锚点,视觉提示聚集在它们周围。这种分布意味着视觉提示可以从密切相关的文本提示中学习或获取常识,使学习过程更加高效。此外,与图5a相比,文本提示在特征空间中更加分离,这表明它允许通过将文本提示暴露于大量视觉提示来细化文本提示,从而使它们更加独特和更好地定义。
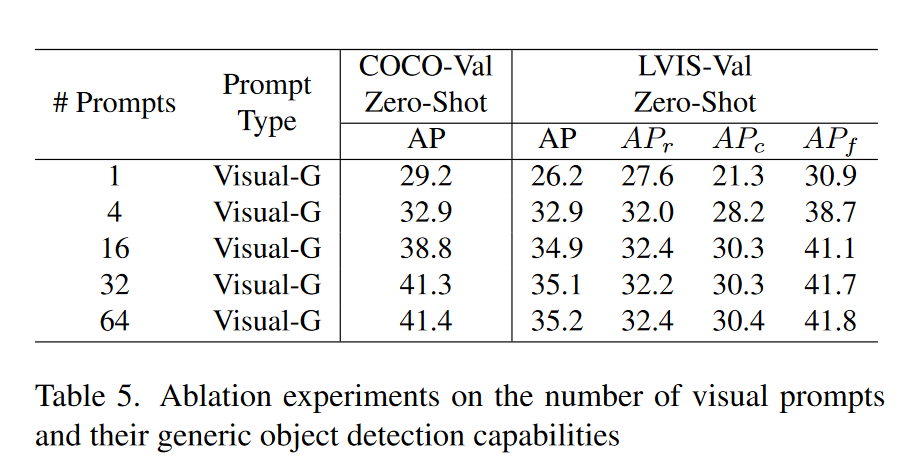
Ablation of generic visual prompt 在表5中,我们表明,通过使用更多的视觉提示,可以逐步提高通用检测能力。原因是视觉提示不像文本提示那么通用,因此我们需要大量的视觉例子来尽可能好地描述通用概念。
Ablation of mixed prompt 我们进一步展示了通用对象检测的混合提示的结果。这种混合方法旨在利用两种模式的优势来提高检测性能。在表8中,COCO上的混合提示实现了文本提示和视觉提示之间的平衡,而LVIS上的性能进一步提高。我们相信这种混合推理工作流程更适合长尾分布的情况,其中文本提示和视觉提示可以相互促进。
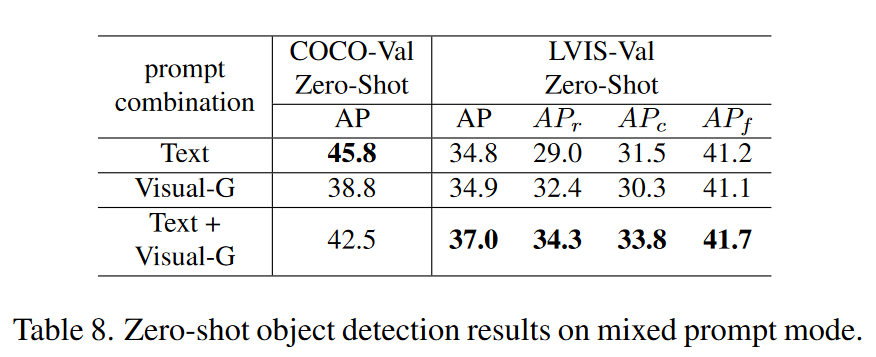
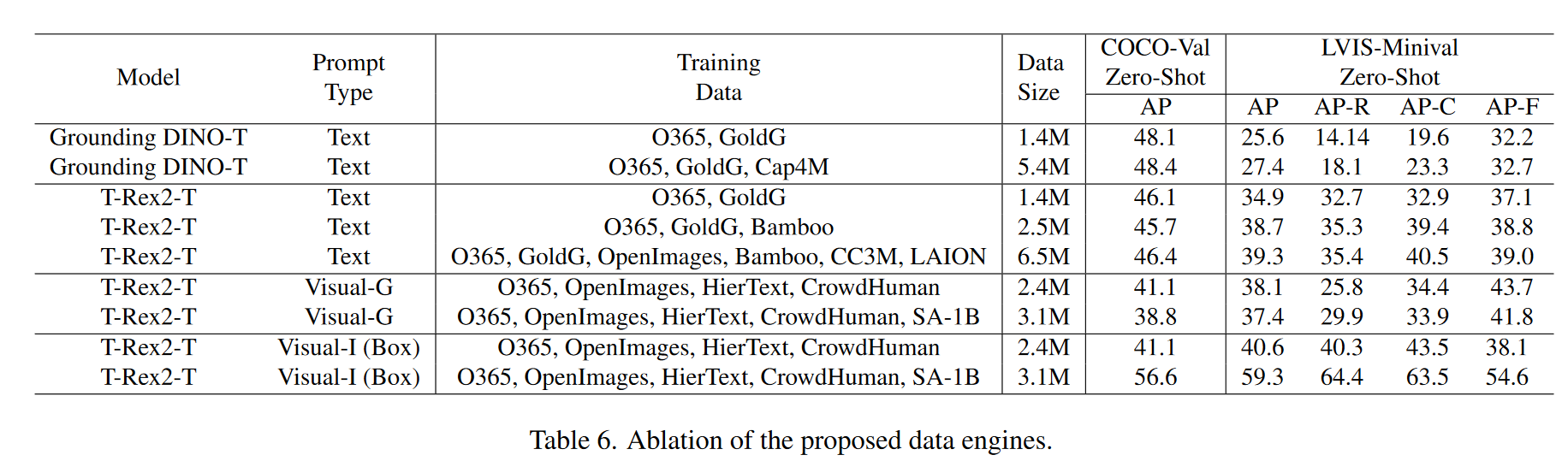
Ablation of data engines 在表6中,我们削弱了两个数据引擎的有效性。对于文本提示,引入Bamboo数据集可以提高LVIS数据集(+3.8AP)的性能,因为其类别多样,但在COCO数据集(-0.4AP)上的性能略有下降,表明该模型不太适合COCO类别。添加图像字幕数据进一步提高了两个基准测试的性能。对于视觉提示,SA-1B数据的引入显着提高了模型的交互能力,但稍微削弱了其通用能力。我们推测,观察到的性能下降可能是由于简单地使用RAP [31]进行SA-1B内的对象分类的不足,这导致模型对SA-1B数据进行不正确的语义学习。未来的工作将需要进一步优化该数据引擎。
Ablation of inference speed 在本节中,我们测量T-Rex 2每个模块的推理速度。该实验在NVIDIA RTX 3090图形处理器上进行,批量大小为1。在测量之前,我们进行了一个预热阶段以稳定图形处理器性能。推理时间被记录超过100次迭代。结果显示在Tab7.得益于后期融合设计,TRex 2在使用交互式视觉提示模式时可以实时工作。具体来说,用户上传图片后,我们只需用主要处理步骤(主干和编码器)处理一次即可获得图像特征。用户的任何进一步交互只需以实时方式运行我们的视觉提示编码器和解码器多次即可。这种快速响应对于自动注释等场景特别有用。

5. Conclusion
T-Rex 2是通用对象检测的一次有希望的尝试。我们揭示了文本提示和视觉提示之间的互补优势,并成功将两种提示模式整合到单个模型中,使其既通用又交互,适合开放集对象检测。我们表明,这两种提示模式可以相互受益并通过对比学习获得绩效。通过在不同场景下在不同提示模式之间切换,T-Rex 2展示了令人印象深刻的零镜头物体检测能力,并可用于各种应用。我们希望这项工作能够为开放集对象检测领域带来新的见解,并为进一步发展做出贡献。
局限性。尽管文本和视觉提示的集成在统一模型中显示了互利,但挑战仍然存在。视觉提示有时可能会干扰文本提示,尤其是在涉及公共对象的场景中,正如在表8中同时使用两者时COCO基准测试的性能下降所表明的那样。尽管如此,LVIS基准的改进凸显了这种方法的潜在好处。因此,进一步研究改善这些模式之间的一致性至关重要。此外,由于视觉多样性,需要多达16个视觉示例来确保可靠检测,这凸显了对使视觉提示能够以更少的视觉示例实现类似效果的方法的需求。
Supplementary Material
A. Model Details
A.1. Implementation Details
对于视觉backbond,我们使用在ImageNet上预训练的Swin Transformer。对于文本编码器,我们使用开源CLIP中的文本编码器。匈牙利匹配过程中,我们只使用分类损失、box L1损失和GIOU损失。损失权重分别为2.0、5.0和2.0。对于最终的损失,我们使用分类损失、box L1损失、GIOU损失和假设损失,并将权重分别设置为1.0、5.0、2.0和1.0。继DINO之后,我们使用对比去噪训练(CDO)来稳定训练并加速收敛。
我们使用自动混合精度进行训练。对于Swin Transformer tiny model,训练是在16个NVIDIA A100图形处理器上执行的,总批量大小为128。对于Swin Transformer large model,训练在32个NVIDIA A100图形处理器上执行,总批量为64个。
B. Data Engine Details
B.1. Text Prompt Data Engine
为了从字幕数据集LAION 400 M和概念字幕中收集区域-文本对,我们首先使用CLIP计算每张图像及其字幕的CLIP得分,并仅保留相似性大于0.8的图像描述对。接下来,我们使用spaCy提取每个标题中的名词短语,然后使用这些名词提示GroundingDINO模型获取与图像中这些名词短语对应的框区域。最后,我们将再次计算每个框区域及其相应的名词短语的CLIP分数,并仅保留相似度大于0.8的对。
B.2. Image Prompt Data Engine
B.3. Data Statistics
C. Advanced Capabilities for T-Rex2
C.1. Region Classification
除了上述三个推理工作流程外,TRex 2还支持区域分类功能。文本提示和视觉提示之间的对比对齐还解锁了对视觉提示区域进行分类的能力。就像CLIP的零镜头分类方法一样,我们可以通过测量视觉提示和预先计算的文本提示之间的相似性来为视觉提示分配类别标签:
L
a
b
e
l
=
argmax
j
(
exp
(
V
⋅
t
j
)
∑
l
=
1
K
exp
(
V
⋅
t
l
)
)
\mathrm{Label}=\operatorname{argmax}j\left(\frac{\exp(V\cdot t_j)}{\sum_{l=1}^K\exp(V\cdot t_l)}\right)
Label=argmaxj(∑l=1Kexp(V⋅tl)exp(V⋅tj))
我们可以使用预定义的类别名称来预先计算文本嵌入,这使我们能够通过视觉提示识别任意对象。
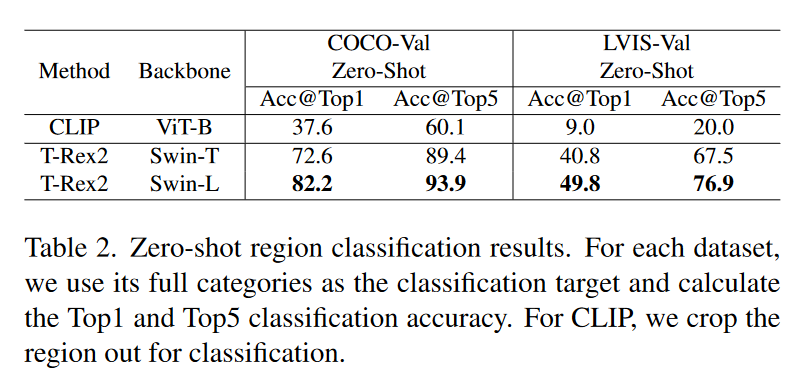
我们在Tab中显示了COCO和LVIS上的零镜头区域分类结果。2.我们使用每个GT框作为视觉提示,并计算与该数据集中所有类别名称的相似性。与CLIP相比,T-Rex 2具有更强的区域分类能力。我们在图3中显示了一些可视化结果。

C.2. Open-set Video Object Detection
T-Rex 2还可用于开放集视频对象检测。给定一个视频,我们可以提取任意N个帧,通过使用T-Rex 2的通用视觉提示工作流程为特定对象定制通用视觉嵌入,然后使用此嵌入来检测视频中的所有帧。我们还在图4中显示了一些可视化结果。尽管没有接受视频数据训练,T-Rex 2也可以很好地检测视频中的对象。
D. More Experiment Details
D.1. Details on Object Counting Task
我们在物体计数任务中评估了T-Rex 2,以展示其交互式物体检测能力。具体来说,我们专注于少镜头物体计数任务。在此任务中,每张图像将在当前图像上提供三个样本框来指示目标对象,并要求输出目标对象的编号。
我们对常用的计数数据集FSC 147和更具挑战性的数据集FSCD-LVIS进行评估。FSC 147包括测试集中的147个类别的物体和1190张图像,FSCD-LVIS包括测试集中的377个类别和1014张图像。这两个数据集都为每张图像提供了三个样本对象的边界框,我们将将其用作T-Rex 2的视觉提示。
Metric. 我们采用平均平均误差(MAE)指标,这是对象计数中广泛采用的标准。数学表达如下:
MAE
=
1
J
∑
j
=
1
J
∣
c
j
∗
−
c
j
∣
\begin{aligned}\text{MAE}&=\frac{1}{J}\sum_{j=1}^{J}\left|c_j^*-c_j\right|\end{aligned}
MAE=J1j=1∑J
cj∗−cj
我们在FSC 147数据集上报告MAE,因为它没有在测试集图像上提供基本真值框,并在FSCD-LVIS数据集上报告AP,因为它提供基本真值框。我们在图5中展示了T-Rex 2在FSC 147和FSCO数据集上的一些预测结果。















 456
456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









