






TensorCore 指令是 NVIDIA 在其 GPU(图形处理单元)中引入的一种特殊硬件指令,用于加速深度学习计算,特别是矩阵乘法和卷积操作。TensorCore 指令专为处理深度学习的张量运算而设计,能够在单个时钟周期内执行大量的计算,极大地提升了深度学习模型的训练和推理速度。
TensorCore 指令的特点
- 高性能矩阵乘法:TensorCore 能够执行高效的混合精度矩阵乘法操作,包括 FP16 和 FP32 数据类型,从而加速训练和推理过程。
- 张量运算加速:TensorCore 通过特定的硬件指令支持张量运算,加速深度学习中的常见操作,如卷积、矩阵乘法等。
- 高吞吐量:TensorCore 可以在单个时钟周期内执行大量的运算,提高了 GPU 的计算能力和吞吐量。
使用 TensorCore 指令的编程示例
在使用 CUDA 编程时,可以通过 cuBLAS 和 cuDNN 库来利用 TensorCore。以下是一个使用 cuBLAS 库进行矩阵乘法的示例:
#include <cublas_v2.h>
#include <cuda_runtime.h>
// Kernel to initialize matrices
__global__ void init_matrices(float *A, float *B, int N) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N * N) {
A[idx] = static_cast<float>(idx);
B[idx] = static_cast<float>(idx);
}
}
int main() {
const int N = 1024;
const float alpha = 1.0f;
const float beta = 0.0f;
float *d_A, *d_B, *d_C;
// Allocate device memory
cudaMalloc((void**)&d_A, N * N * sizeof(float));
cudaMalloc((void**)&d_B, N * N * sizeof(float));
cudaMalloc((void**)&d_C, N * N * sizeof(float));
// Initialize matrices
init_matrices<<<(N * N + 255) / 256, 256>>>(d_A, d_B, N);
// Create cuBLAS handle
cublasHandle_t handle;
cublasCreate(&handle);
// Perform matrix multiplication using TensorCore
cublasSetMathMode(handle, CUBLAS_TENSOR_OP_MATH);
cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, N, N, N, &alpha, d_A, N, d_B, N, &beta, d_C, N);
// Cleanup
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
cublasDestroy(handle);
return 0;
}
初始化矩阵:使用 CUDA 核函数 init_matrices 初始化两个矩阵 A 和 B。
分配设备内存:使用 cudaMalloc 分配设备内存。
创建 cuBLAS 句柄:使用 cublasCreate 创建 cuBLAS 句柄。
设置 TensorCore 数学模式:通过 cublasSetMathMode 将 cuBLAS 数学模式设置为 CUBLAS_TENSOR_OP_MATH,以启用 TensorCore 指令。
矩阵乘法:使用 cublasSgemm 函数执行矩阵乘法。
清理资源:释放设备内存和销毁 cuBLAS 句柄。
TensorCore 指令介绍
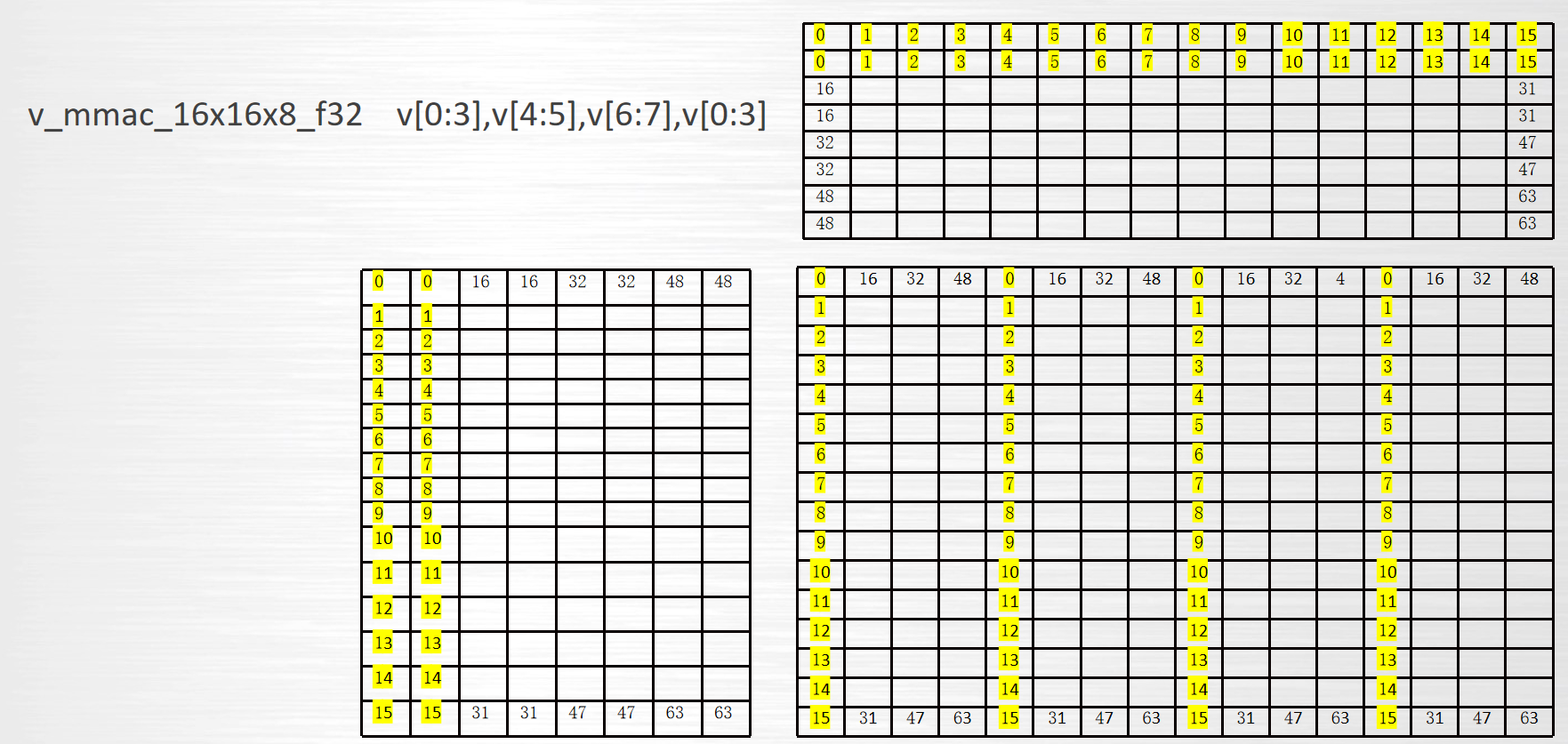
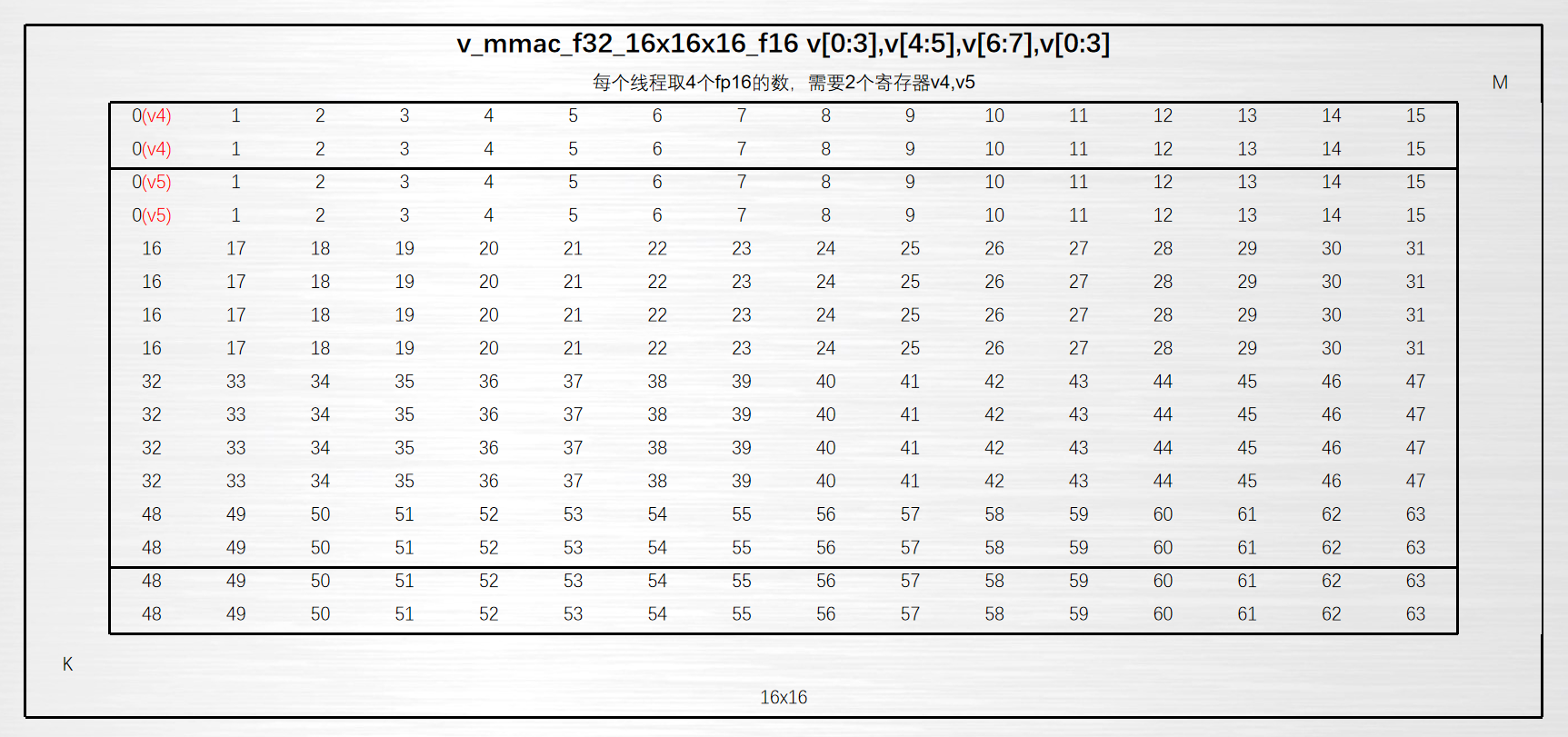
汇编编程
汇编语言是比较底层的语言,使用汇编是为了对代码进行优化,因为用汇编代码来优化,可以人为的来控制指令的延时,使代码性能达到最优。但是纯汇编代码开发难度大,维护成本高,因此,可以使用c代码开发程序,其中比较消耗性能的一小部分代码,可以用内嵌汇编来实现。
asm volatile("v_add_f32_dpp %0 , %1, %1 row_shl:8": "=v"(fsum) : "v"(value));
asm volatile("s_waitcnt lgkmcnt(0)\n s_barrier");
%0 --- 代表的是fsum
%1 --- 代表的是value
LDS读写
将寄存器的数据写入到LDS中:
ds_write_b32 v[vgprLocalAddress], v[0], offset:0
ds_write_b64 v[vgprLocalAddress], v[0:1], offset:0
ds_write_b128 v[vgprLocalAddress], v[0:3], offset:0
ds_write_b16 v[vgprLocalAddress], v[0], offset:0
ds_write_b16_d16_hi v[vgprLocalAddress], v[0], offset:0
将LDS中的数据读出到寄存器中:
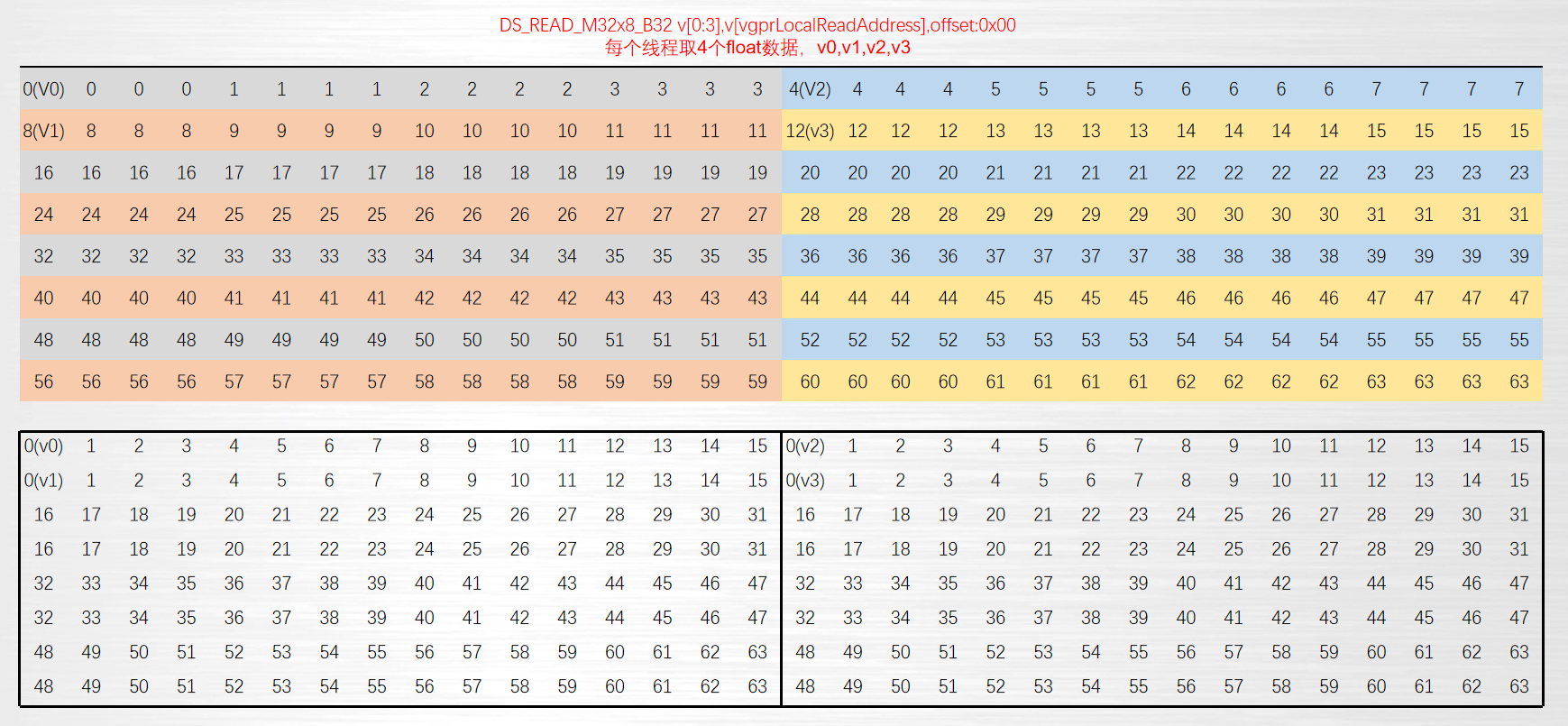
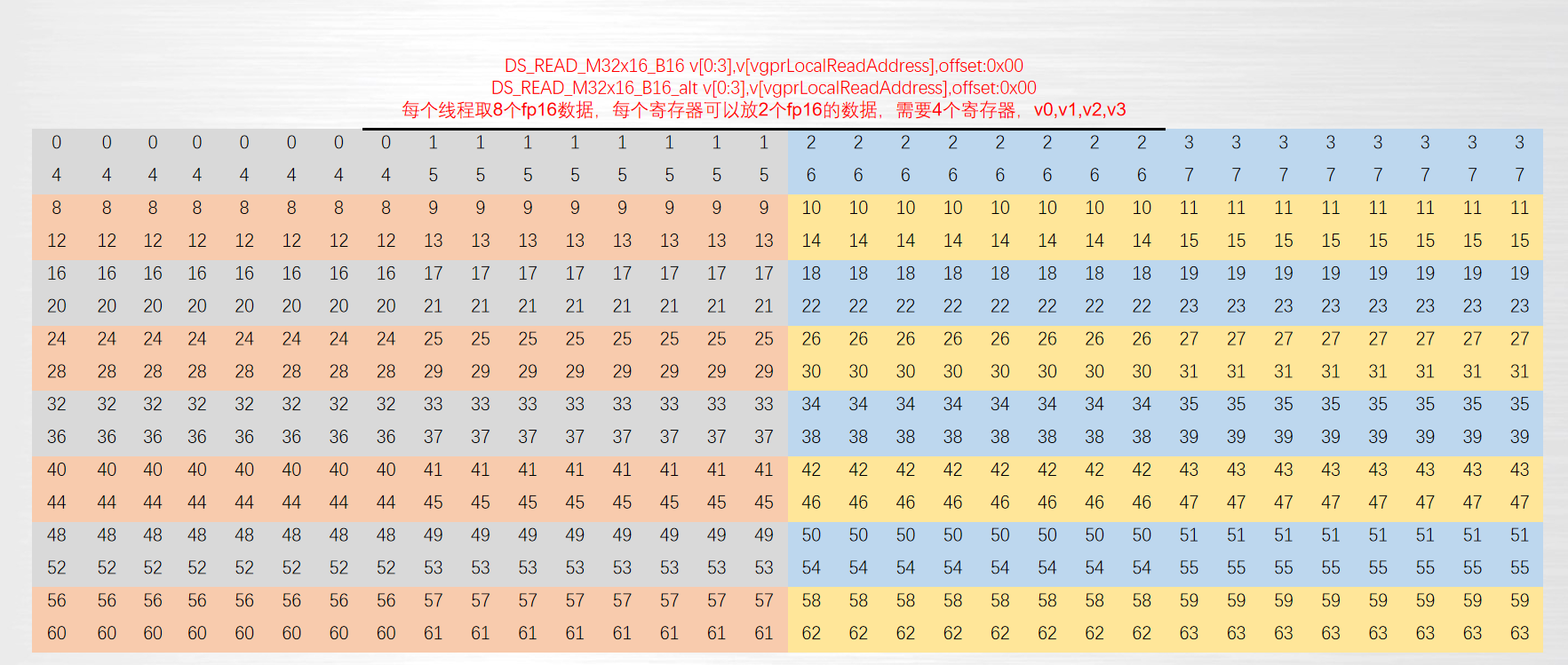
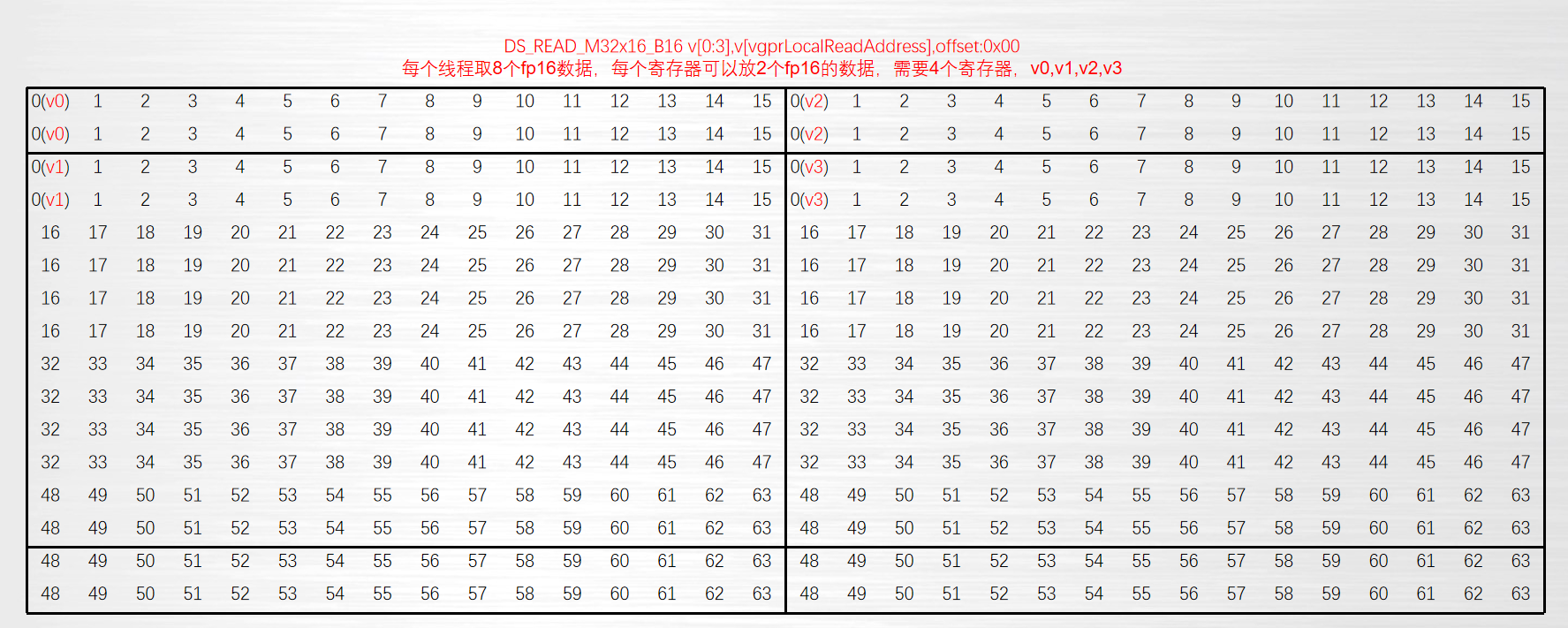
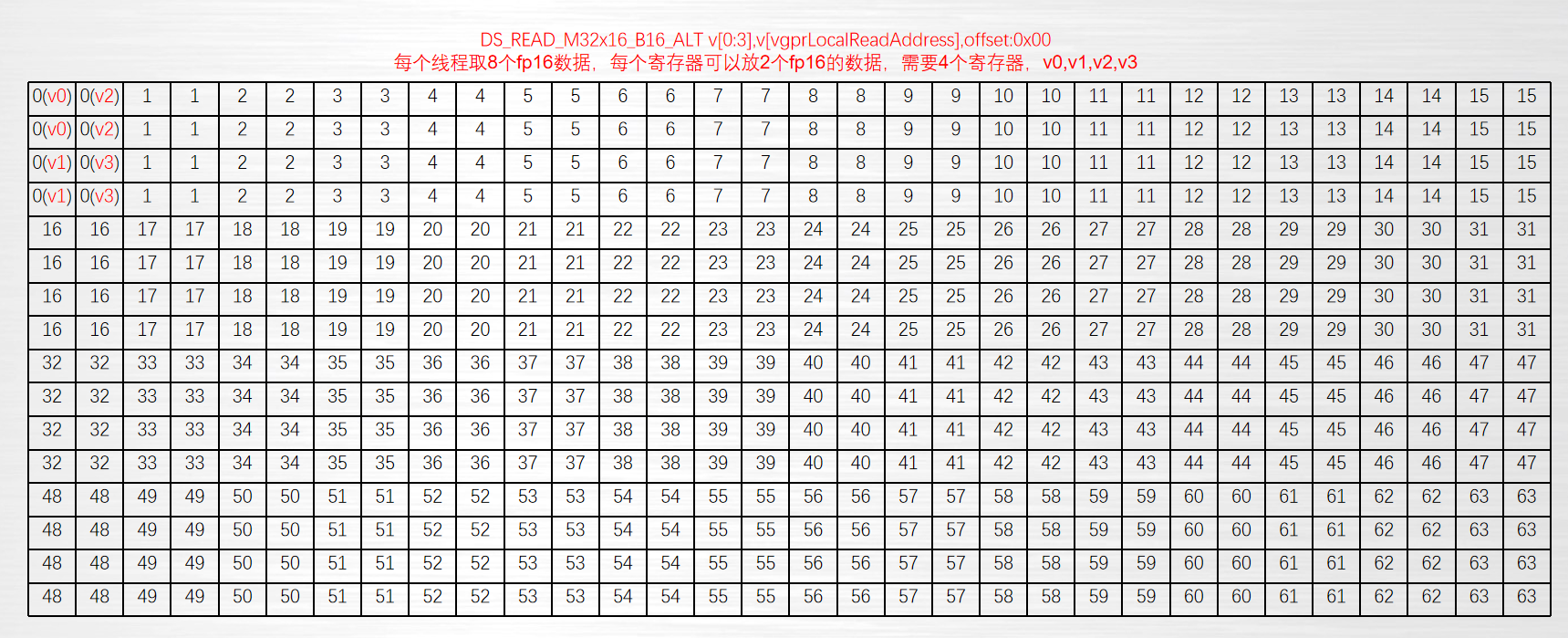
ds_read_b32 v[0],v[vgprLocalAddress], offset:0
ds_read_b64 v[0:1],v[vgprLocalAddress], offset:0
ds_read_b128 v[0:3],v[vgprLocalAddress], offset:0
ds_read_u16 v[0],v[vgprLocalAddress], offset:0
ds_read_u16_d16 v[0],v[vgprLocalAddress], offset:0
ds_read_u16_d16_hi v[0],v[vgprLocalAddress], offset:0
计算指令
单精度乘累加指令:
v_fma_f32 v2,v0,v1,v2
V2.f = V0.f * V1.f + V2.f
混合精度乘累加指令:
v_dot2_f32_f16 v2,v0,v1,v2
V2.f32 = V0.f16[0] * V1.f16[0] + V0.f16[1] * V1.f16[1] + V2.f32
延时与同步
s_waitcnt lgkmcnt(n) --- 控制ds指令延时。n=0,表示全部指令执行完成
s_waitcnt vmcnt(n) --- 控制buffer延时。 n!=0, 表示除了n条指令外,其他指令全部执行完成
__syncthreads(); ---所有线程同步,在操作数据时,要对线程进行同步,确保数据的准确性。
可以通过 dccobjdump --inputs=demo 来生成汇编文件,查看所写demo的汇编代码。还有其他指令可以自行学习选择使用,具体参考:https://llvm.org/docs/AMDGPU/AMDGPUAsmGFX9.html
















 5446
5446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









