






作者 | 进击的Killua 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/671312675
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
概要介绍
TensorCore 是从Nvidia Volta 架构GPU开始支持的重要特性,使CUDA开发者能够使用混合精度来获得更高的吞吐量,而不牺牲精度。TensorCore已经在许多深度学习框架(包括Tensorflow、PyTorch、MXNet和Caffe2)中支持深度学习训练。本文将展示如何使用CUDA库在自己的应用程序中使用张量核,以及如何在CUDA C++设备代码中直接编程。
TensorCore
TensorCore是可编程的矩阵乘法和累加单元,可以提供多达125 Tensor tflop的训练和推理应用。TensorCore及其相关的数据路径是定制的,以显著提高浮点计算吞吐量。每个TensorCore提供一个4x4x4矩阵处理数组,它执行操作D=A* B+C,其中A、B、C和D是4×4矩阵,如下图所示。矩阵乘法输入A和B是FP16矩阵,而累积矩阵C和D可以是FP16或FP32矩阵。
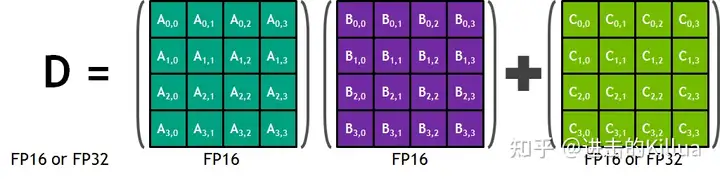
每个TensorCore每个时钟周期可以执行64个浮点FMA混合精度操作,而在一个SM中有8个TensorCore,所以一个SM中每个时钟可以执行1024(8x64x2)个浮点操作。TensorCore对FP16输入数据进行运算,使用FP32累加。如图下图所示,对于4x4x4矩阵乘法,FP16乘法的结果是一个完整精度的值,该值在进行4x4x4矩阵乘法的点积运算中与其他乘积一起累积在FP32操作中。
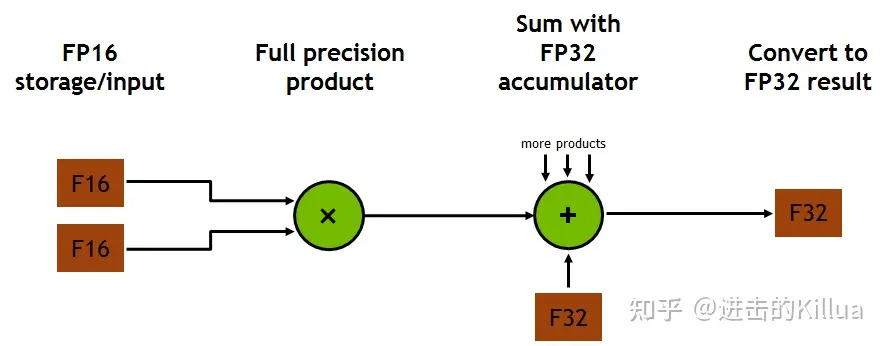
对一般用户来说,可以通过使用cuBLAS和cuDNN这两个CUDA库来间接使用Tensor Cores。cuBLAS利用Tensor Cores加速GEMM计算(GEMM是BLAS中矩阵乘法的术语);cuDNN则利用Tensor Cores加速卷积和循环神经网络(RNNs)的计算。
cuBLAS中使用TensorCore
可以通过对现有的cuBLAS代码进行一些更改来充分利用Tensor Cores。这些更改是对cuBLAS API的使用进行的小修改。以下示例代码应用了一些简单的规则,以指示cuBLAS应该使用Tensor Cores。
// First, create a cuBLAS handle:
cublasStatus_t cublasStat = cublasCreate(&handle);
// Set the math mode to allow cuBLAS to use Tensor Cores:
cublasStat = cublasSetMathMode(handle, CUBLAS_TENSOR_OP_MATH);
// Allocate and initialize your matrices (only the A matrix is shown):
size_t matrixSizeA = (size_t)rowsA * colsA;
T_ELEM_IN **devPtrA = 0;
cudaMalloc((void**)&devPtrA[0], matrixSizeA * sizeof(devPtrA[0][0]));
T_ELEM_IN A = (T_ELEM_IN *)malloc(matrixSizeA * sizeof(A[0]));
memset( A, 0xFF, matrixSizeA* sizeof(A[0]));
status1 = cublasSetMatrix(rowsA, colsA, sizeof(A[0]), A, rowsA, devPtrA[i], rowsA);
// ... allocate and initialize B and C matrices (not shown) ...
// Invoke the GEMM, ensuring k, lda, ldb, and ldc are all multiples of 8,
// and m is a multiple of 4:
cublasStat = cublasGemmEx(handle, transa, transb, m, n, k, alpha,
A, CUDA_R_16F, lda,
B, CUDA_R_16F, ldb,
beta, C, CUDA_R_16F, ldc, CUDA_R_32F, algo);cuBLAS用户将注意到与现有的cuBLAS GEMM代码相比有一些变化:
例程必须是一个GEMM;目前只有GEMM支持Tensor Core执行。
数学模式必须设置为
CUBLAS_TENSOR_OP_MATH。k、lda、ldb和ldc必须是8的倍数;m必须是4的倍数。Tensor Core数学例程以8个值为一步跨越输入数据,因此矩阵的维度必须是8的倍数。矩阵的输入和输出数据类型必须是半精度或单精度。
不满足上述规则的GEMM将回退到非Tensor Core实现。
cuDNN中使用TensorCore
在cuDNN中使用Tensor Cores也很简单,而且同样只需要对现有代码进行轻微修改。
// Create a cuDNN handle:
checkCudnnErr(cudnnCreate(&handle_));
// Create your tensor descriptors:
checkCudnnErr( cudnnCreateTensorDescriptor( &cudnnIdesc ));
checkCudnnErr( cudnnCreateFilterDescriptor( &cudnnFdesc ));
checkCudnnErr( cudnnCreateTensorDescriptor( &cudnnOdesc ));
checkCudnnErr( cudnnCreateConvolutionDescriptor( &cudnnConvDesc ));
// Set tensor dimensions as multiples of eight (only the input tensor is shown here):
int dimA[] = {1, 8, 32, 32};
int strideA[] = {8192, 1024, 32, 1};
checkCudnnErr( cudnnSetTensorNdDescriptor(cudnnIdesc, getDataType(),
convDim+2, dimA, strideA) );
// Allocate and initialize tensors (again, only the input tensor is shown):
checkCudaErr( cudaMalloc((void**)&(devPtrI), (insize) * sizeof(devPtrI[0]) ));
hostI = (T_ELEM*)calloc (insize, sizeof(hostI[0]) );
initImage(hostI, insize);
checkCudaErr( cudaMemcpy(devPtrI, hostI, sizeof(hostI[0]) * insize, cudaMemcpyHostToDevice));
// Set the compute data type (below as CUDNN_DATA_FLOAT):
checkCudnnErr( cudnnSetConvolutionNdDescriptor(cudnnConvDesc,
convDim,
padA,
convstrideA,
dilationA,
CUDNN_CONVOLUTION,
CUDNN_DATA_FLOAT) );
// Set the math type to allow cuDNN to use Tensor Cores:
checkCudnnErr( cudnnSetConvolutionMathType(cudnnConvDesc, CUDNN_TENSOR_OP_MATH) );
// Choose a supported algorithm:
cudnnConvolutionFwdAlgo_t algo = CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM;
// Allocate your workspace:
checkCudnnErr( cudnnGetConvolutionForwardWorkspaceSize(handle_, cudnnIdesc,
cudnnFdesc, cudnnConvDesc,
cudnnOdesc, algo, &workSpaceSize) );
if (workSpaceSize > 0) {
cudaMalloc(&workSpace, workSpaceSize);
}
// Invoke the convolution:
checkCudnnErr( cudnnConvolutionForward(handle_, (void*)(&alpha), cudnnIdesc, devPtrI,
cudnnFdesc, devPtrF, cudnnConvDesc, algo,
workSpace, workSpaceSize, (void*)(&beta),
cudnnOdesc, devPtrO) );注意一下与常见cuDNN使用的一些变化:
卷积算法必须是
ALGO_1(前向传播时为IMPLICIT_PRECOMP_GEMM)。除了ALGO_1之外的其他卷积算法可能会在未来的cuDNN版本中使用Tensor Cores。数学类型必须设置为
CUDNN_TENSOR_OP_MATH,与cuBLAS类似.输入和输出通道的维度都必须是8的倍数。与cuBLAS类似,Tensor Core数学例程以8个值为一步跨越输入数据,因此输入数据的维度必须是8的倍数。
卷积的输入、滤波器和输出数据类型必须是半精度。
不满足上述规则的卷积将回退到非Tensor Core实现。
CUDA C++中使用TensorCore
虽然cuBLAS和cuDNN涵盖了许多Tensor Cores的潜在用途,但用户还可以直接在CUDA C++中编程。Tensor Cores通过nvcuda::wmma命名空间中的一组函数和类型在CUDA 9.0中公开。这些函数和类型允许您将值加载或初始化到张量核心所需的特殊格式中,执行矩阵乘累加(MMA)步骤,并将值存回内存。在程序执行期间,一个完整的warp可以同时使用多个Tensor Cores,这使得warp能够以非常高的吞吐量执行16x16x16的MMA。核心的API如下所示,详细介绍见文档。
template<typename Use, int m, int n, int k, typename T, typename Layout=void> class fragment;
// 等待直到所有warp lanes都到达load_matrix_sync,然后从内存中加载矩阵片段a。
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm);
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm, layout_t layout);
// 等待,直到所有warp lanes都到达store_matrix_sync,然后将矩阵片段a存储到内存中。
void store_matrix_sync(T* mptr, const fragment<...> &a, unsigned ldm, layout_t layout);
// 使用常量值v填充一个矩阵片段。
void fill_fragment(fragment<...> &a, const T& v);
// 等待直到所有warp lanes都到达mma_sync,然后执行warp同步的矩阵乘累加操作D = A * B + C。
void mma_sync(fragment<...> &d, const fragment<...> &a, const fragment<...> &b, const fragment<...> &c, bool satf=false);下面来看个实际的简单例子。
头文件引用
#include <mma.h>
using namespace nvcuda;声明和定义
完整的GEMM规范允许算法在a或b的转置上工作,并且数据步幅可以大于矩阵中的步幅。为简单起见,我们假设a和b都没有被转置,并且内存和矩阵的主导维度相同。我们采用的策略是让一个warp负责输出矩阵的一个16×16的部分。通过使用二维网格和线程块,我们可以有效地在二维输出矩阵上划分warp。
// The only dimensions currently supported by WMMA
const int WMMA_M = 16;
const int WMMA_N = 16;
const int WMMA_K = 16;
__global__ void wmma_example(half *a, half *b, float *c,
int M, int N, int K,
float alpha, float beta)
{
// Leading dimensions. Packed with no transpositions.
int lda = M;
int ldb = K;
int ldc = M;
// Tile using a 2D grid
int warpM = (blockIdx.x * blockDim.x + threadIdx.x) / warpSize;
int warpN = (blockIdx.y * blockDim.y + threadIdx.y);在执行MMA操作之前,操作数矩阵必须表示在GPU的寄存器中。由于MMA是一个warp范围的操作,这些寄存器分布在warp的各个线程之间,每个线程持有整个矩阵的一个fragment。在CUDA中,fragment是一个模板类型,具有描述片段持有的矩阵、整个WMMA操作的形状、数据类型以及A和B矩阵中数据是按行还是按列主序的模板参数。最后一个参数可以用于对A或B矩阵进行转置。这个示例中没有进行转置,所以两个矩阵都是按列主序的,这是GEMM的标准方式。
// Declare the fragments
wmma::fragment<wmma::matrix_a, WMMA_M, WMMA_N, WMMA_K, half, wmma::col_major> a_frag;
wmma::fragment<wmma::matrix_b, WMMA_M, WMMA_N, WMMA_K, half, wmma::col_major> b_frag;
wmma::fragment<wmma::accumulator, WMMA_M, WMMA_N, WMMA_K, float> acc_frag;
wmma::fragment<wmma::accumulator, WMMA_M, WMMA_N, WMMA_K, float> c_frag;
// set o in accumulator fragment
wmma::fill_fragment(acc_frag, 0.0f);内部循环
我们用于GEMM的策略是每个warp计算输出矩阵的一个tile。为此,我们需要在A矩阵的行和B矩阵的列上进行循环。这沿着这两个矩阵的K维度进行,并生成一个MxN的输出tile。load矩阵函数从内存中获取数据(在这个示例中是全局内存,尽管它可以是任何内存空间),并将其放入一个fragment中。load的第三个参数是矩阵在内存中的“主导维度”;我们加载的16×16 tile在内存中是不连续的,因此函数需要知道连续列(或行,如果这些是按行主序的片段)之间的跨度。MMA调用在原地累积,因此第一个和最后一个参数都是我们之前初始化为零的累加器fragment。
// Loop over the K-dimension
for (int i = 0; i < K; i += WMMA_K) {
int aRow = warpM * WMMA_M;
int aCol = i;
int bRow = i;
int bCol = warpN * WMMA_N;
// Bounds checking
if (aRow < M && aCol < K && bRow < K && bCol < N) {
// Load the inputs
wmma::load_matrix_sync(a_frag, a + aRow + aCol * lda, lda);
wmma::load_matrix_sync(b_frag, b + bRow + bCol * ldb, ldb);
// Perform the matrix multiplication
wmma::mma_sync(acc_frag, a_frag, b_frag, acc_frag);
}
}结果写回
现在,acc_frag根据A和B的乘积持有了这个warp输出tile的结果。完整的GEMM规范允许对这个结果进行缩放,并且可以就地累积到一个矩阵上。进行这种缩放的一种方法是对fragment执行逐元素操作。尽管从矩阵坐标到线程的映射未定义,但逐元素操作不需要知道这种映射,因此仍然可以使用片段执行这些操作。因此,对fragment执行缩放操作或将一个fragment的内容添加到另一个fragment中是合法的,只要这两个fragment具有相同的模板参数。利用这个特性,我们加载了C中的现有数据,并在正确的缩放下将计算结果迄今为止与之累积。
最后,我们将数据存储到内存中。目标指针再次可以是对GPU可见的任何内存空间,并且必须指定内存中的主导维度。还有一个选项可以指定输出是按行还是按列主序写入。
// Load in current value of c, scale by beta, and add to result scaled by alpha
int cRow = warpM * WMMA_M;
int cCol = warpN * WMMA_N;
if (cRow < M && cCol < N) {
wmma::load_matrix_sync(c_frag, c + cRow + cCol * ldc, ldc, wmma::mem_col_major);
for(int i=0; i < c_frag.num_elements; i++) {
c_frag.x[i] = alpha * acc_frag.x[i] + beta * c_frag.x[i];
}
// Store the output
wmma::store_matrix_sync(c + cRow + cCol * ldc, c_frag, ldc, wmma::mem_col_major);
}
}总结
本文介绍了TensorCore和其api wmma api的使用,和常规CUDA C开发不太一样的地方,就是它是warp-level的,这里需要切换下思路,其实可以把它想象成synchronized函数,warp中所有线程都在等待wmma中的流程执行完毕,可以从所有api都有sync结尾来引导出。wmma api运用了线程中的寄存器GPR和TensorCore硬件来加速矩阵运算,绝大多数场景下通过cuBLAS或cuDNN使用即可。
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!
自动驾驶感知:目标检测、语义分割、BEV感知、毫米波雷达视觉融合、激光视觉融合、车道线检测、目标跟踪、Occupancy、深度估计、transformer、大模型、在线地图、点云处理、模型部署、CUDA加速等技术交流群;
多传感器标定:相机在线/离线标定、Lidar-Camera标定、Camera-Radar标定、Camera-IMU标定、多传感器时空同步等技术交流群;
多传感器融合:多传感器后融合技术交流群;
规划控制与预测:规划控制、轨迹预测、避障等技术交流群;
定位建图:视觉SLAM、激光SLAM、多传感器融合SLAM等技术交流群;
三维视觉:三维重建、NeRF、3D Gaussian Splatting技术交流群;
自动驾驶仿真:Carla仿真、Autoware仿真等技术交流群;
自动驾驶开发:自动驾驶开发、ROS等技术交流群;
其它方向:自动标注与数据闭环、产品经理、硬件选型、求职面试、自动驾驶测试等技术交流群;
扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】硬件专场


















 607
607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









