







参考:
http://blog.csdn.net/zz_1215/article/details/44138823
http://www.cnblogs.com/jerrylead/archive/2011/05/13/2045309.html
https://www.cnblogs.com/pinard/p/9426283.html
在系统学习机器学习之增强学习(一)--模型基础中,我们讲到了强化学习模型的8个基本要素。但是仅凭这些要素还是无法使用强化学习来帮助我们解决问题的, 在讲到模型训练前,模型的简化也很重要,这一篇主要就是讲如何利用马尔科夫决策过程(Markov Decision Process,以下简称MDP)来简化强化学习的建模。
MDP这一篇对应Sutton书的第三章和UCL强化学习课程的第二讲。
强化学习引入MDP的原因
强化学习的8个要素我们在第一节已经讲了。其中的第七个是环境的状态转化模型,它可以表示为一个概率模型,即在状态s下采取动作a,转到下一个状态s′的概率,表示为Pass′。
如果按照真实的环境转化过程看,转化到下一个状态s′的概率既与上一个状态s有关,还与上上个状态,以及上上上个状态有关。这一会导致我们的环境转化模型非常复杂,复杂到难以建模。因此我们需要对强化学习的环境转化模型进行简化。简化的方法就是假设状态转化的马尔科夫性,也就是假设转化到下一个状态s′的概率仅与上一个状态s有关,与之前的状态无关。用公式表示就是:
Pass′=?(St+1=s′|St=s,At=a)
除了对于环境的状态转化模型这个因素做马尔科夫假设外,我们还对强化学习第四个要素个体的策略(policy)π也做了马尔科夫假设。即在状态s时采取动作a的概率仅与当前状态s有关,与其他的要素无关。用公式表示就是
π(a|s)=P(At=a|St=s)
对于第五个要素,价值函数vπ(s)也是一样, vπ(s)现在仅仅依赖于当前状态了,那么现在价值函数vπ(s)表示为:
vπ(s)=?π(Gt|St=s)=?π(Rt+1+γRt+2+γ2Rt+3+...|St=s)
其中,Gt代表收获(return), 是一个MDP中从某一个状态St开始采样直到终止状态时所有奖励的有衰减的之和。
马尔可夫模型的几类子模型
大家应该还记得马尔科夫链(Markov Chain),了解机器学习的也都知道隐马尔可夫模型(Hidden Markov Model,HMM)。它们具有的一个共同性质就是马尔可夫性(无后效性),也就是指系统的下个状态只与当前状态信息有关,而与更早之前的状态无关。
马尔可夫决策过程(Markov Decision Process, MDP)也具有马尔可夫性,与上面不同的是MDP考虑了动作,即系统下个状态不仅和当前的状态有关,也和当前采取的动作有关。还是举下棋的例子,当我们在某个局面(状态s)走了一步(动作a),这时对手的选择(导致下个状态s’)我们是不能确定的,但是他的选择只和s和a有关,而不用考虑更早之前的状态和动作,即s’是根据s和a随机生成的。
我们用一个二维表格表示一下,各种马尔可夫子模型的关系就很清楚了:
| 不考虑动作 | 考虑动作 | |
| 状态完全可见 | 马尔科夫链(MC) | 马尔可夫决策过程(MDP) |
| 状态不完全可见 | 隐马尔可夫模型(HMM) | 不完全可观察马尔可夫决策过程(POMDP) |
接下来,先介绍一下马尔科夫决策过程(MDP,Markov decision processes)。
1. 马尔科夫决策过程
一个马尔科夫决策过程由一个五元组构成![]()
* S表示状态集(states)。(比如,在自动直升机系统中,直升机当前位置坐标组成状态集)
* A表示一组动作(actions)。(比如,使用控制杆操纵的直升机飞行方向,让其向前,向后等)
* ![]() 是状态转移概率。S中的一个状态到另一个状态的转变,需要A来参与。
是状态转移概率。S中的一个状态到另一个状态的转变,需要A来参与。![]() 表示的是在当前
表示的是在当前![]() 状态下,经过
状态下,经过![]() 作用后,会转移到的其他状态的概率分布情况(当前状态执行a后可能跳转到很多状态)。
作用后,会转移到的其他状态的概率分布情况(当前状态执行a后可能跳转到很多状态)。
* ![]() 是阻尼系数(discount factor)
是阻尼系数(discount factor)
* ![]() ,R是回报函数(reward function),回报函数经常写作S的函数(只与S有关),这样的话,R重新写作
,R是回报函数(reward function),回报函数经常写作S的函数(只与S有关),这样的话,R重新写作![]() 。
。
MDP的动态过程如下:某个agent的初始状态为![]() ,然后从A中挑选一个动作
,然后从A中挑选一个动作![]() 执行,执行后,agent按
执行,执行后,agent按![]() 概率随机转移到了下一个
概率随机转移到了下一个![]() 状态,
状态,![]() 。然后再执行一个动作
。然后再执行一个动作![]() ,就转移到了
,就转移到了![]() ,接下来再执行
,接下来再执行![]() …,我们可以用下面的图表示整个过程
…,我们可以用下面的图表示整个过程
![]()
如果对HMM有了解的话,理解起来比较轻松。
我们定义经过上面转移路径后,得到的回报函数之和如下
![]()
如果R只和S有关,那么上式可以写作
![]()
我们的目标是选择一组最佳的action,使得全部的回报加权和期望最大。
![]()
从上式可以发现,在t时刻的回报值被打了![]() 的折扣,是一个逐步衰减的过程,越靠后的状态对回报和影响越小。最大化期望值也就是要将大的
的折扣,是一个逐步衰减的过程,越靠后的状态对回报和影响越小。最大化期望值也就是要将大的![]() 尽量放到前面,小的尽量放到后面。
尽量放到前面,小的尽量放到后面。
已经处于某个状态s时,我们会以一定策略![]() 来选择下一个动作a执行,然后转换到另一个状态s’。我们将这个动作的选择过程称为策略(policy),每一个policy其实就是一个状态到动作的映射函数
来选择下一个动作a执行,然后转换到另一个状态s’。我们将这个动作的选择过程称为策略(policy),每一个policy其实就是一个状态到动作的映射函数![]() 。给定
。给定![]() 也就给定了
也就给定了![]() ,也就是说,知道了
,也就是说,知道了![]() 就知道了每个状态下一步应该执行的动作。
就知道了每个状态下一步应该执行的动作。
我们为了区分不同![]() 的好坏,并定义在当前状态下,执行某个策略
的好坏,并定义在当前状态下,执行某个策略![]() 后,出现的结果的好坏,需要定义值函数(value function)也叫折算累积回报(discounted cumulative reward)
后,出现的结果的好坏,需要定义值函数(value function)也叫折算累积回报(discounted cumulative reward)
![]()
可以看到,在当前状态s下,选择好policy后,值函数是回报加权和期望。这个其实很容易理解,给定![]() 也就给定了一条未来的行动方案,这个行动方案会经过一个个的状态,而到达每个状态都会有一定回报值,距离当前状态越近的其他状态对方案的影响越大,权重越高。这和下象棋差不多,在当前棋局
也就给定了一条未来的行动方案,这个行动方案会经过一个个的状态,而到达每个状态都会有一定回报值,距离当前状态越近的其他状态对方案的影响越大,权重越高。这和下象棋差不多,在当前棋局![]() 下,不同的走子方案是
下,不同的走子方案是![]() ,我们评价每个方案依靠对未来局势(
,我们评价每个方案依靠对未来局势(![]() ,
,![]() ,…)的判断。一般情况下,我们会在头脑中多考虑几步,但是我们会更看重下一步的局势。
,…)的判断。一般情况下,我们会在头脑中多考虑几步,但是我们会更看重下一步的局势。
从递推的角度上考虑,当期状态s的值函数V,其实可以看作是当前状态的回报R(s)和下一状态的值函数V’之和,也就是将上式变为:
![]()
然而,我们需要注意的是虽然给定![]() 后,在给定状态s下,a是唯一的,但
后,在给定状态s下,a是唯一的,但![]() 可能不是多到一的映射。比如你选择a为向前投掷一个骰子,那么下一个状态可能有6种。再由Bellman等式,从上式得到
可能不是多到一的映射。比如你选择a为向前投掷一个骰子,那么下一个状态可能有6种。再由Bellman等式,从上式得到
![]()
s’表示下一个状态。
前面的R(s)称为立即回报(immediate reward),就是R(当前状态)。第二项也可以写作![]() ,是下一状态值函数的期望值,下一状态s’符合
,是下一状态值函数的期望值,下一状态s’符合![]() 分布。
分布。
可以想象,当状态个数有限时,我们可以通过上式来求出每一个s的V(终结状态没有第二项V(s’))。如果列出线性方程组的话,也就是|S|个方程,|S|个未知数,直接求解即可。
当然,我们求V的目的就是想找到一个当前状态s下,最优的行动策略![]() ,定义最优的V*如下:
,定义最优的V*如下:
![]()
就是从可选的策略![]() 中挑选一个最优的策略(discounted rewards最大)。
中挑选一个最优的策略(discounted rewards最大)。
上式的Bellman等式形式如下:
![]()
第一项与![]() 无关,所以不变。第二项是一个
无关,所以不变。第二项是一个![]() 就决定了每个状态s的下一步动作a,执行a后,s’按概率分布的回报概率和的期望。
就决定了每个状态s的下一步动作a,执行a后,s’按概率分布的回报概率和的期望。
如果上式还不好理解的话,可以参考下图:
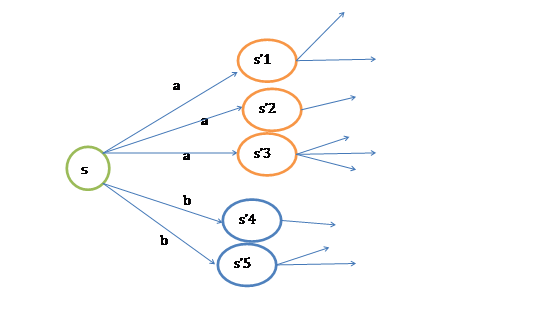
定义了最优的V*,我们再定义最优的策略![]() 如下:
如下:
![]()
选择最优的![]() ,也就确定了每个状态s的下一步最优动作a。
,也就确定了每个状态s的下一步最优动作a。
根据以上式子,我们可以知道
![]()
解释一下就是当前状态的最优的值函数V*,是由采用最优执行策略![]() 的情况下得出的,采用最优执行方案的回报显然要比采用其他的执行策略
的情况下得出的,采用最优执行方案的回报显然要比采用其他的执行策略![]() 要好。
要好。
这里需要注意的是,如果我们能够求得每个s下最优的a,那么从全局来看,![]() 的映射即可生成,而生成的这个映射是最优映射,称为
的映射即可生成,而生成的这个映射是最优映射,称为![]() 。
。![]() 针对全局的s,确定了每一个s的下一个行动a,不会因为初始状态s选取的不同而不同
针对全局的s,确定了每一个s的下一个行动a,不会因为初始状态s选取的不同而不同
补充:
3. 值函数(value function)
上篇我们提到增强学习学到的是一个从环境状态到动作的映射(即行为策略),记为策略π: S→A。而增强学习往往又具有延迟回报的特点: 如果在第n步输掉了棋,那么只有状态sn和动作an获得了立即回报r(sn,an)=-1,前面的所有状态立即回报均为0。所以对于之前的任意状态s和动作a,立即回报函数r(s,a)无法说明策略的好坏。因而需要定义值函数(value function,又叫效用函数)来表明当前状态下策略π的长期影响。
用Vπ(s)表示策略π下,状态s的值函数。ri表示未来第i步的立即回报,常见的值函数有以下三种:
a)
b)
c)
其中:
a)是采用策略π的情况下未来有限h步的期望立即回报总和;
b)是采用策略π的情况下期望的平均回报;
c)是值函数最常见的形式,式中γ∈[0,1]称为折合因子,表明了未来的回报相对于当前回报的重要程度。特别的,γ=0时,相当于只考虑立即不考虑长期回报,γ=1时,将长期回报和立即回报看得同等重要。接下来我们只讨论第三种形式,
现在将值函数的第三种形式展开,其中ri表示未来第i步回报,s'表示下一步状态,则有:

给定策略π和初始状态s,则动作a=π(s),下个时刻将以概率p(s'|s,a)转向下个状态s',那么上式的期望可以拆开,可以重写为:

上面提到的值函数称为状态值函数(state value function),需要注意的是,在Vπ(s)中,π和初始状态s是我们给定的,而初始动作a是由策略π和状态s决定的,即a=π(s)。
定义动作值函数(action value functionQ函数)如下:

给定当前状态s和当前动作a,在未来遵循策略π,那么系统将以概率p(s'|s,a)转向下个状态s',上式可以重写为:

在Qπ(s,a)中,不仅策略π和初始状态s是我们给定的,当前的动作a也是我们给定的,这是Qπ(s,a)和Vπ(a)的主要区别。
知道值函数的概念后,一个MDP的最优策略可以由下式表示:

即我们寻找的是在任意初始条件s下,能够最大化值函数的策略π*。
4. 值函数与Q函数计算的例子
上面的概念可能描述得不够清晰,接下来我们实际计算一下,如图所示是一个格子世界,我们假设agent从左下角的start点出发,右上角为目标位置,称为吸收状态(Absorbing state),对于进入吸收态的动作,我们给予立即回报100,对其他动作则给予0回报,折合因子γ的值我们选择0.9。
为了方便描述,记第i行,第j列的状态为sij, 在每个状态,有四种上下左右四种可选的动作,分别记为au,ad,al,ar。(up,down,left,right首字母),并认为状态按动作a选择的方向转移的概率为1。

1.由于状态转移概率是1,每组(s,a)对应了唯一的s'。回报函数r(s'|s,a)可以简记为r(s,a)
如下所示,每个格子代表一个状态s,箭头则代表动作a,旁边的数字代表立即回报,可以看到只有进入目标位置的动作获得了回报100,其他动作都获得了0回报。 即r(s12,ar) = r(s23,au) =100。

2. 一个策略π如图所示:

3. 值函数Vπ(s)如下所示

根据Vπ的表达式,立即回报,和策略π,有
Vπ(s12) = r(s12,ar) = r(s13|s12,ar) = 100
Vπ(s11)= r(s11,ar)+γ*Vπ(s12) = 0+0.9*100 = 90
Vπ(s23) = r(s23,au) = 100
Vπ(s22)= r(s22,ar)+γ*Vπ(s23) = 90
Vπ(s21)= r(s21,ar)+γ*Vπ(s22) = 81
4. Q(s,a)值如下所示

有了策略π和立即回报函数r(s,a), Qπ(s,a)如何得到的呢?
对s11计算Q函数(用到了上面Vπ的结果)如下:
Qπ(s11,ar)=r(s11,ar)+ γ *Vπ(s12) =0+0.9*100 = 90
Qπ(s11,ad)=r(s11,ad)+ γ *Vπ(s21) = 72
至此我们了解了马尔可夫决策过程的基本概念,知道了增强学习的目标(获得任意初始条件下,使Vπ值最大的策略π*)。
总结
首先我们这里讨论的MDP是非确定的马尔科夫决策过程,也就是回报函数和动作转换函数是有概率的。在状态s下,采取动作a后的转移到的下一状态s’也是有概率的。再次,在增强学习里有一个重要的概念是Q学习,本质是将与状态s有关的V(s)转换为与a有关的Q。强烈推荐Tom Mitchell的《机器学习》最后一章,里面介绍了Q学习和更多的内容。最后,里面提到了Bellman等式,在《算法导论》中有Bellman-Ford的动态规划算法,可以用来求解带负权重的图的最短路径,里面最值得探讨的是收敛性的证明,非常有价值。有学者仔细分析了增强学习和动态规划的关系。















 1365
1365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









