







 本文详细介绍了MATLAB在数学建模中的应用,包括数据导入、统计分析、图形绘制、数据处理和机器学习等方面。作者分享了MATLAB与ROS的通信,以及在处理大量数据时的技巧,如使用importdata、load、cell数组和正则表达式。文章还探讨了概率分布、假设检验、卡方检测和核密度估计等统计方法,并提供了MATLAB代码示例。此外,作者还讨论了数据可视化,如箱线图、直方图和核密度函数的绘制。文章最后提到了MATLAB在随机森林和决策树等机器学习算法中的应用。
本文详细介绍了MATLAB在数学建模中的应用,包括数据导入、统计分析、图形绘制、数据处理和机器学习等方面。作者分享了MATLAB与ROS的通信,以及在处理大量数据时的技巧,如使用importdata、load、cell数组和正则表达式。文章还探讨了概率分布、假设检验、卡方检测和核密度估计等统计方法,并提供了MATLAB代码示例。此外,作者还讨论了数据可视化,如箱线图、直方图和核密度函数的绘制。文章最后提到了MATLAB在随机森林和决策树等机器学习算法中的应用。
现在ros都可以与MATLAB进行通信了。
https://github.com/talregev/ROS_Matlab
看了大神的github
真的太有收获了
https://github.com/kintzhao?page=2&tab=repositories
matlab安装教程:
https://jingyan.baidu.com/article/456c463b22527e0a58314402.html
顺便自己打算把一些好的作图的东西也粘的这个里面。
如何批量导入dat信息。
参考博客:
http://blog.csdn.net/txlsddd/article/details/52601011?locationNum=1&fps=1
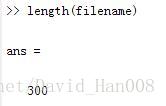
在matlab当中,我们用ls来导入文件的名字,
filename=ls('C:\Users\Administrator\Desktop\gene_info\*.dat');
然后我们这个里面的所有的文件进行循环
在matlab当中importdata和load的区别在于:load一般只针对于matlab特有的格式。例如.mat文件。importdata支持的格式一般是针对于文本文件。
这条语句是用来进行导入文件的名字,将文件名做成一个字符串数组方便调用
str=['C:\Users\Administrator\Desktop\gene_info\',filename(i,:)];然后将文件名str 进行importdata(str),随后给了data_cell这个一个元祖
matlab当中的元胞数组是什么概念?

matlab当中的元胞数组http://blog.163.com/zmbetty7891@126/blog/static/162476718201092524859556/
https://jingyan.baidu.com/article/20095761997932cb0721b485.html
将所有的文件都放到一个元祖当中当中,就是上面的这个图。
(将来不管是什么数据,首先要想到的就是把这些数据导入到一个元素当中)
这个就是在第一行表示行数,就是给每个元祖进行了一下编号
data=[1:length(data_cell)]; 这里data是2是因为他们从第2个开始。
for j=1:length(data_cell)
data(2,j)=length(data_cell{
1,j});
for k=1:length(data_cell{
1,j})
numstr=regexprep(data_cell{
1,j}(k,1),'rs','');
data(k+2,j)=str2num(numstr{
1,1});
end
end把字符转出相应的数字 将2翻译成two->to
str2num把数字转出成相应的数据
num2str regexprep 用于对字符串进行查找并且替换相比于其他:regexp和regexpi。regexp用于对字符进行查找,大小写敏感。regexpi大小写不敏感。
{
}我们用这个括号来表示元祖()用这个来对元素进行地进行定位data(k+2)这里+2因为在上面的得到的这些数组
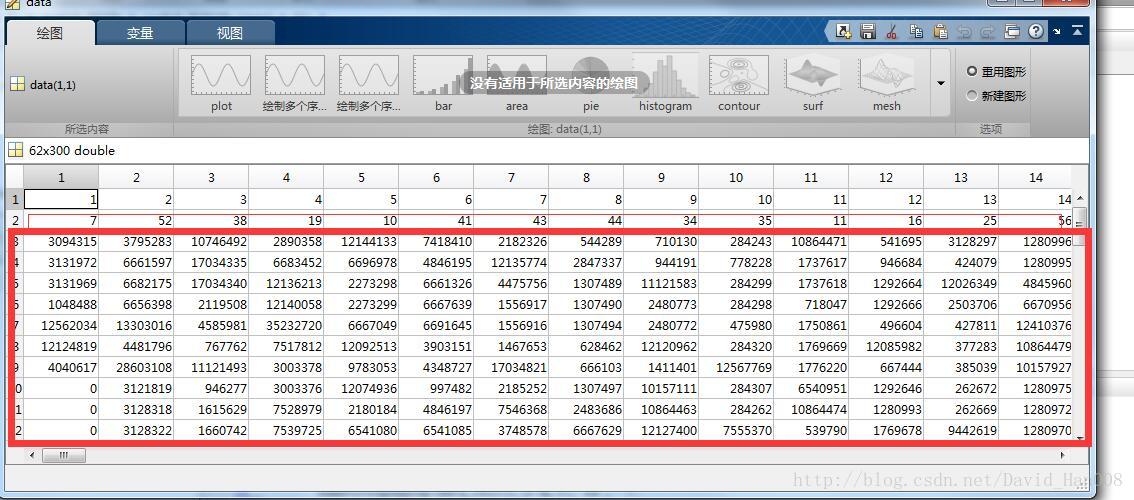
第一行表示的序列
第二行表示的长度
从第三行后面的表示数组的长度,我觉得应该吧这个好的模板记住,以后有类型的事情,就用这个套路进行处理。
filename=ls('C:\Users\Administrator\Desktop\gene_info\*.dat');
for i=1:length(filename)
str=['C:\Users\Administrator\Desktop\gene_info\',filename(i,:)];
data_cell{
1,i}=importdata(str);
end
data=[1:length(data_cell)];
for j=1:length(data_cell)
data(2,j)=length(data_cell{1,j});
for k=1:length(data_cell{
1,j})
numstr=regexprep(data_cell{
1,j}(k,1),'rs','');
data(k+2,j)=str2num(numstr{1,1});
end
endmatlab单步调试就是 F10
matlab注释就是%,以及按ctrl+R
如果是大量的数据就用importdata(‘文件的目录’)
str2=['C:\Users\Administrator\Desktop\2016试题\B\B题附件\genotype.dat'];
data_cell2=importdata(str2);
numstr=regexprep(data_cell2(1,1),'rs','');这个后面的地方data_cell2(1,1)是提取出第一个细胞元组当中所有的数据

细胞数组是 matlab当中的一类特殊的数组
http://www.fx114.net/qa-111-87603.aspx

cell生成细胞数组
cellplot用图形方式显示细胞数组
细胞数组的生成,先用cell函数预分配数组,然后再对每个元素赋值。
B=cell(3,4) 创建一个3*4的细胞矩阵。
MATLAB取消多行注释
所以说用strcmp函数去比较两个字符是可取的,就是当检测到第一个字符不对,就走了
导致的结果就是整个data里面有很多
百度了一下还是用正则表达式去做。

存储矩阵用()
存储cell用{}

在data_num当中产生200-1000个43个随机数
for i=1:43
data_num(i)=rand(1)*(1000-200)+200;
endmatlab当中关于点除的东西。其实 就不是矩阵的乘法运算。
产生一列数据
x_i(1,[1:43])=0;新建一个矩阵,这个矩阵是一列,然后我们分号进行分开。
data=[x_i;data_ai;data_bi;data_num];然后通过提取第i个数组进行赋值
x0=data(:,i);并且进行转置
x0=x0';将最后的结果的数据进行存储
result(i)=fval;采用模拟算法
[x fval] = simulannealbnd(@fun1,x0,Aeq, beq);一些比较基础但是很有用函数
floor函数是进行向下取整floor(1.5)=1
ceil函数是进行向上取整ceil(1.5)=2
round函数,是取最接近的整数 可以理解为四舍五入函数
对于细胞数组cell使用的是{ }
同样,也可以对一个cell进行转置。
matlab如何进行读写操作。fopen()用来读入数据 fprintf()用来写入数据按照某种特定的格式。
使用doc命令进行查找某个函数的功能,例如doc fopen
利用fopen打开文件 也可以选择默认的按时,默认方式就是只读的方式进行打开。fileID=fopen('test.txt')等效于:fileID=fopen('test.txt','r');
在matlab当中进行查找和替换的的strrep函数
在 str1 中找到str2 ,替换成str3
str1 = 'This is a good example.';
str2 = 'good';
str3 = 'great';
str = strrep(str1, str2,str3)
str =
This is a great example.从论文算法的角度来看的话,感觉需要用的卡方检测,卡方检测就是统计样本实际的观测量与理论推断之间的偏离程度。实际观测与理论推断之间的偏离程度决定了卡方值的大小,卡方值越小,说明偏差越小,越符合。如果两个数值完全相等,卡方值位0,表明理论值与实际值完全符合。在这里说一个查专业资料,尽量去维基百科,英语查。哪里的资料要把百度更多一些。matlab当中的关于卡方检测的两个函数有crosstab和chi2gof函数。大神博客的链接:个人认为还是很详细的http://blog.sina.com.cn/s/blog_7054a1960102wizu.html。
由于对matlab当中的统计分析的工具箱不太熟悉,现在想测试一下
1、概率分布
随机变量的统计行为,就是他的概率分布。分别是
概率密度函数 pdf 表示的连续分布,每个点在这个范围的可能性。
累积分布函数(cdf)是概率密度函数的积分。
逆累积分布函数 (icdf))
随机数产生器
均值和方差函数
一般的概率密度函数
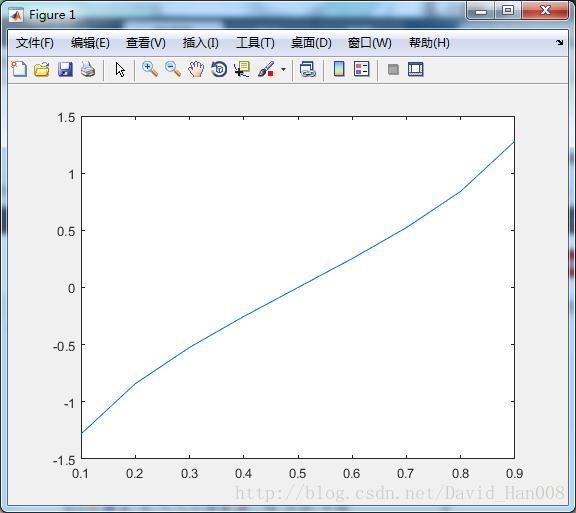
x=[-1:0.1:1];
f=normpdf(x,0,1);
plot(x,f)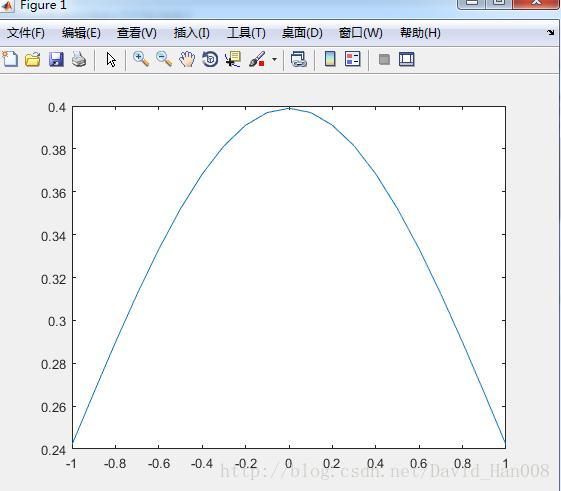
但是感觉不是太靠谱。这个为什么产生的一条直线。
产生标准正态分布
x=[-1:0.01:9];
f=pdf('Normal',x,1,1);
plot(x,f)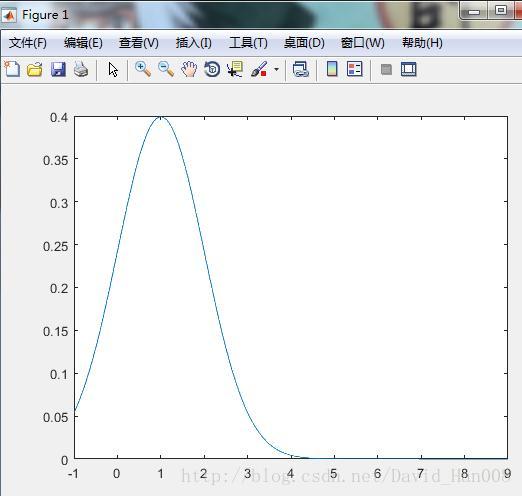
关于pdf(‘name’,x,a1,a2);
当表示的一个二维的随机变量的时候。name表示分布的类型,例如normal.x表示取值的范围。a1表示的均值,a2表示的方差。a3如果有高纬的分布的话,反正就是以此表示他们的参数。例如
x=[-1:0.1:1];
f=pdf('Poisson',x,1);
plot(x,f)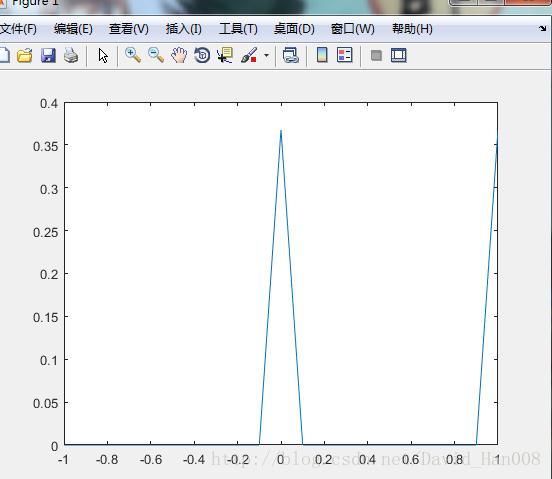
累积分布函数
x=[-1:0.1:5];
f=cdf('Normal',x,0,1);%f=icdf('Normal',x,0,1);
plot(x,f);这是cdf函数
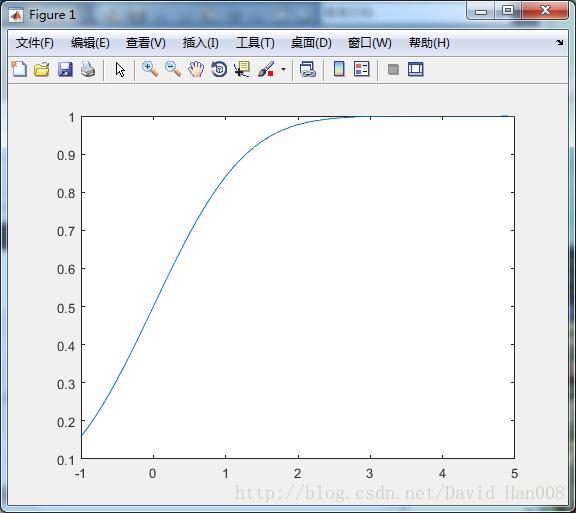
这是icdf函数
随机数产生器
random函数
y=random('Normal',0,1);输出的结果是是一个随机数。
计算均值和方差
[m,n]=normstat(0,0.3)返回的m,n分别是均值和方差 输入的两个参数 分别是 mu和 sigma
举例说明:数学公式如何和matlab相互对应起来

计算某个值得概率密度用normcdf ,使用cdf函数能够快速的计算PDF。这就是累积概率分布的作用。
normcdf(2,1,3)如果要求p(x>2)
那么就是1减去上面这个数
如果去要某个一个区间范围p(2<x<4)
mcdf(4,1,3)-normcdf(2,1,3)
描述下性统计
中心位置度量,数据样本的中心度量的目的在于,对数据向本的数据分布线上的中心位置予以定位。
均值是对位置的简单和通常的估计量。但是野值(就会出奇的大或者出奇的小)
对于平均值进行定义
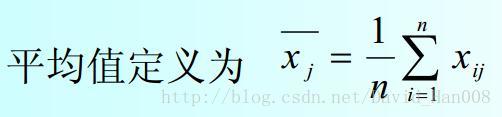
利用随机产生器,产生在0,1,然后100行5列的二维矩阵
x=normrnd(0,1,1000,5);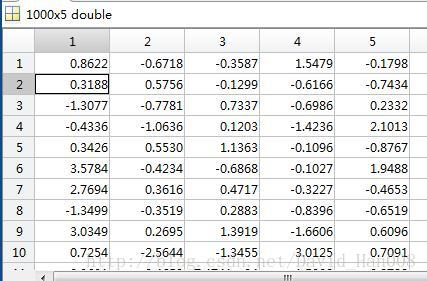
xbar=mean(x);输出的是
几何平均数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3449
3449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









