







ANN是一个非线性大规模并行处理系统
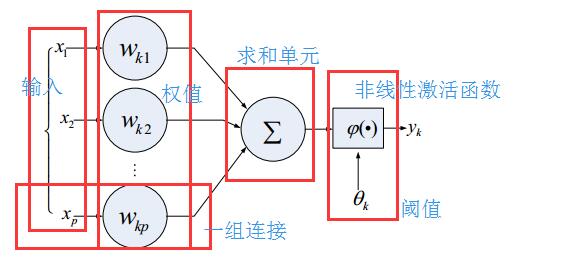
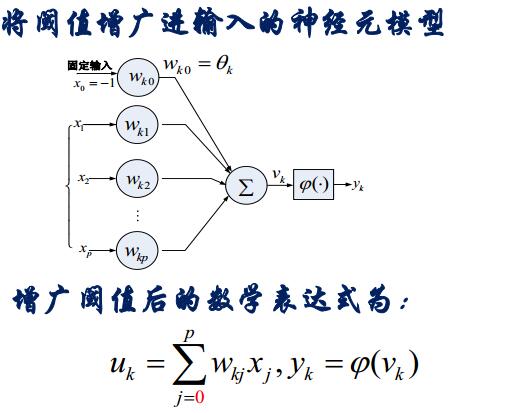
1.1人工神经元的一般模型
神经元的具有的三个基本要素
1、一组连接,连接的强度由个连接上的权值表示,若为正,则表示是激活,为负,表示,抑制
2、一个求和单元:用于求各个输入信号的加权和
3、一个非线性激活函数:起到非线性映射的作用,并将神经元输出幅度限制在一定的范围内,一般限制在(0,1)或者(-1,1)之间
此外还有一个阈值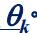
求和部分
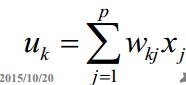
总和减去阈值
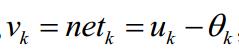
减去后的值经过线性激活函数
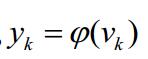
得到输出Yk
将上面这个过程进行简化:
激活函数的种类
1.1.1阈值函数(M-P模型)
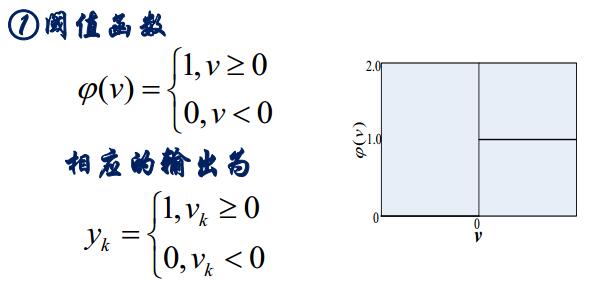
分段线性函数
例如

sigmoid函数

1.1.2网络的拓扑结构
前馈型网络:各神经元接收前一层的输入并且输出给下一层
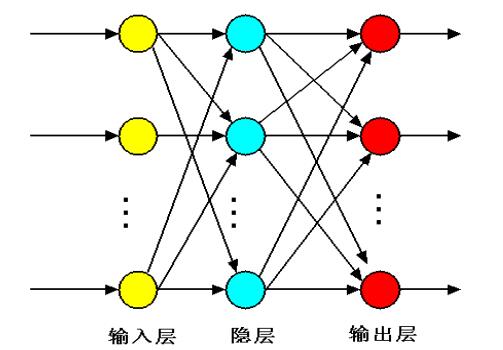
反馈型神经网络:
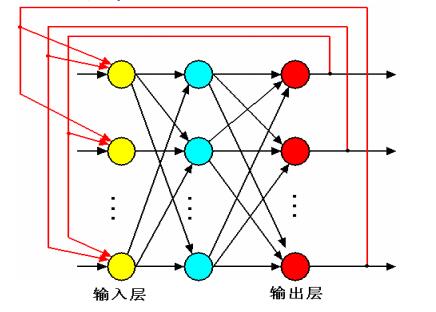
人工神经网络的工作过程
1、学习期:此时各个计算单元额状态不变, 各连接线上的权值可以通过学习来修改(改变的是权值)
2、工作期:此时各个连接权固定,计算单元状态的变化,以达到某种稳定状态。(改变的输出)
2.1感知器及其学习算法
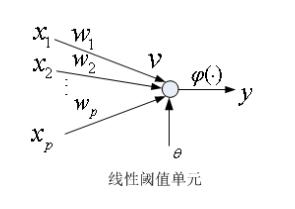
2.1.1线性阈值单元
线性阈值单元也叫做LTU,包括一个神经元和一组可调节的权值,神经元采用M-P模型(也就是激活函数是阈值函数)
线性阈值单元可实现,与或非,与非等逻辑函数
异或逻辑是线性不可分的
2.1.2感知器
感知器是单层前馈神经网络,只有两层,即输入层和中间层
感知器只能解决线性可分问题,不 能解决异或问题
感知器的学习算法:


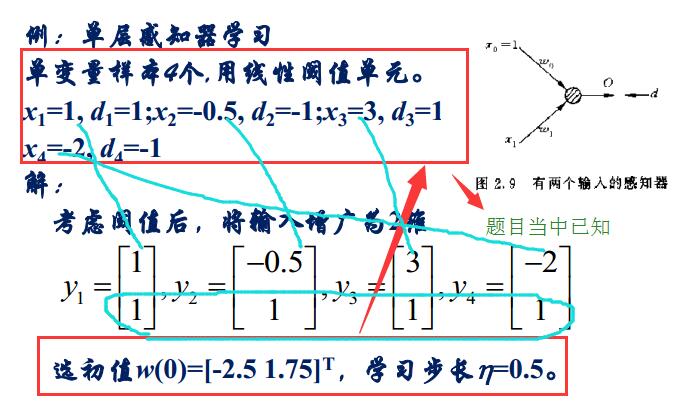
对于感知器的学习就是去求他的权值
然后再通过:
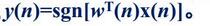
求出感知的输出
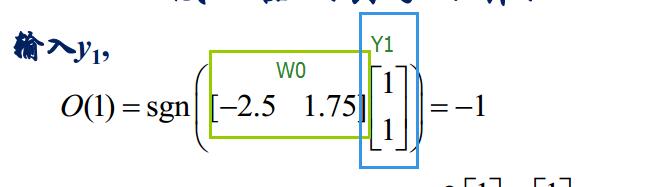
接下来要求调节权系数:
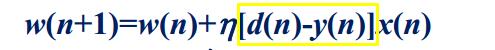
于是我们先求黄色框当中的式子,令e(n)=d(n)-y(n)(其中d(n)已知)
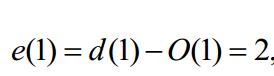
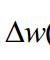
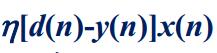
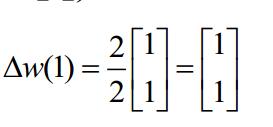
就可以求出下一秒的权值
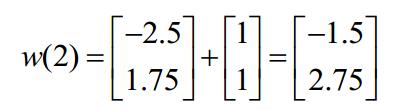

然后依次这样求解下去
感知器的局限性:
1、只能用来解决简单问题
2、感知器仅能够线性地将输入的矢量进行分类
3、当输入的一个数据比另外一个数据大或者小的时候,可能收敛比较慢。
3.1多层前馈神经网络
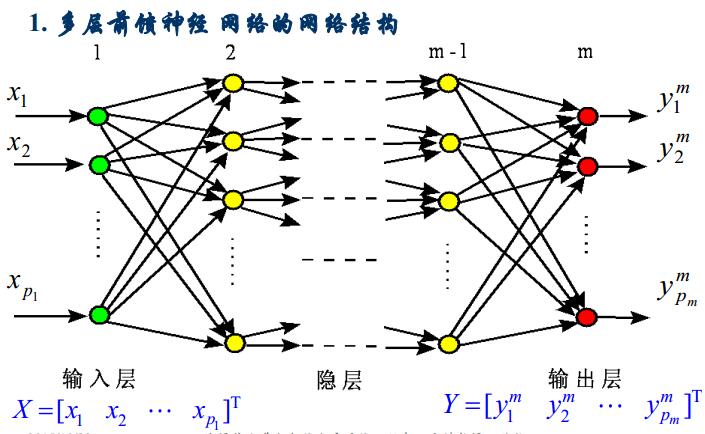
学习算法:
正向传播:输入信息由输入层传递到隐层,最终在输出层输出。(改变的是输出)
反向传播:修改各层神经元之间的权值,使得误差信号最小.(改变的的权值)
BP神经网络也叫反向传播学习算法

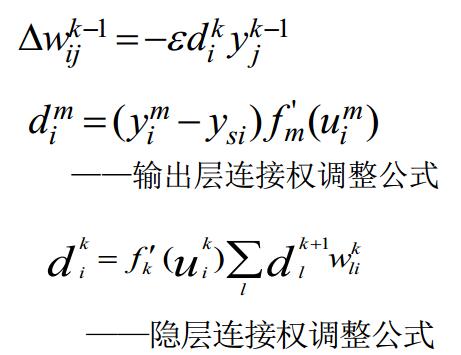
当激活函数采用sigmoid函数的时候,上面的公式可以写为:
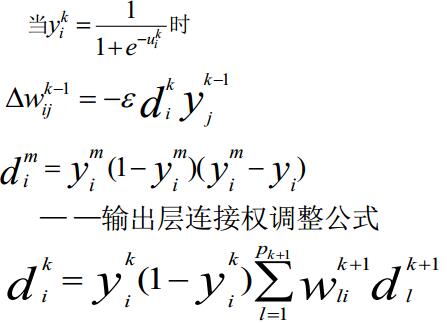
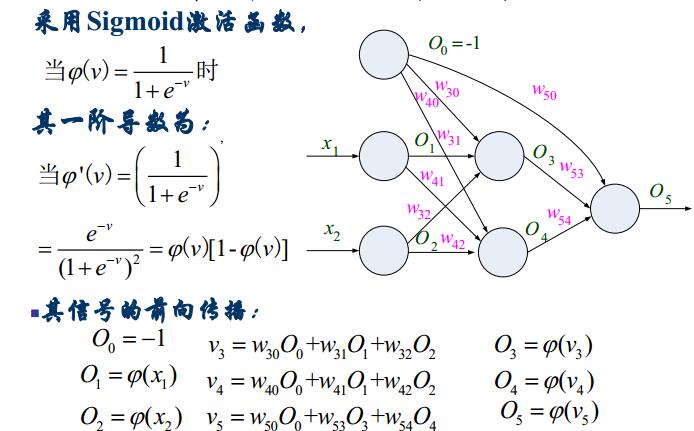
求输出的正向的,求每个权值的误差的反向的
BP的优点:
1、有很好的逼近
2、较强的泛化能力
3、较好的容错性
存在的主要问题:
1、收敛速度慢
2、目标函数存在局部极小点
3、难以确定隐层和隐层结点的数目
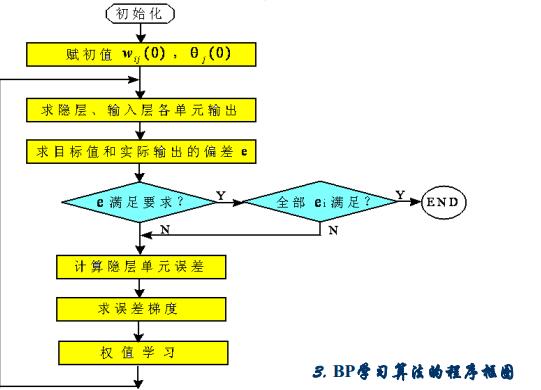
反向传播学习算法的一般步骤
1、初始化
选定合适的网络,设置所有可调节的参数(权值和阈值)
2、求连接权的权值和修正量
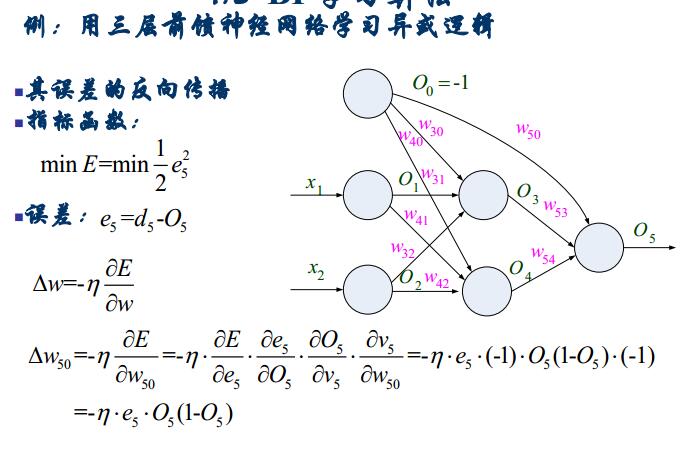

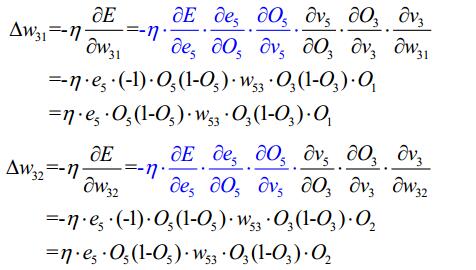
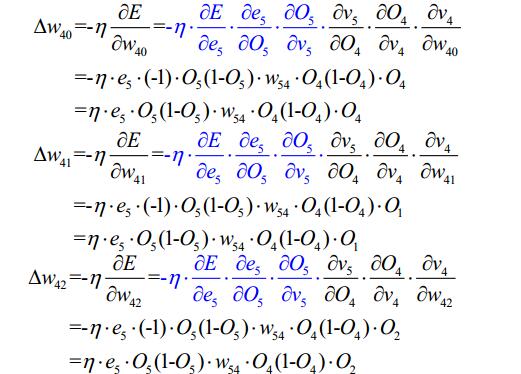
3.2BP算法的设计流程图



4.1径向基函数
对于高维的数值分析,我们选择一种空间和函数作为基底。一般而言,在处理多元函数的问题的基时候
选用:

径向基函数 定义:
选择N个基函数,每个基函数对应一个训练数据,各基函数的形式为:
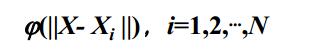
其中Xi是函数的中心,
最常用的径向基函数是高斯核函数,高斯核函数的表示形式为:
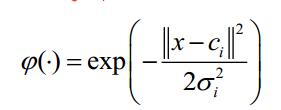
其中Ci 为核函数中心,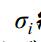
径向基函数的网络一般包括三层,包含一个有输入层,一个隐层和一个线性输出层。隐层最常用的是高斯径向基函数,而输出层最常用的是线性激活函数。RBF网络的权值训练是一层一层进行的,对径向基层的权值训练可采用无导师训练,在输出层的权值设计可采用误差纠正算法,也就是有导师训练
RBF的优点
RBF比多层前馈神经网络相比,规模大、但学习速度快、函数逼近、模式识别和分类能力都优于BP网络。
RBF神经元模型
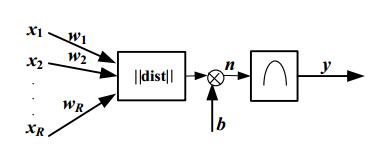
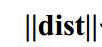
高斯函数表示式为:
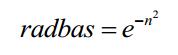
RBF网络有三组可调参数:隐含层基函数中心、方差和隐含层单元到输出单元的权值。
如何确定这三个参数,主要是有两个方法:
1、根据经验和聚类方法选择中心和方差,当选定中心和方差后,由于输出是线性单元,他的权值可以采用迭代的最小二乘法直接计算出来。
2、通过训练样本,用误差纠正算法进行监督学习,逐步修正以上3个参数,也就是计算总的输出误差对各参数的梯度。再用梯度下降法修正待学习的参数。
一种采用K均值的聚类算法确定各基函数的额中心,以及其方差,用局部梯度下降法修正网络权值的算法如下:


广义RBF网络(GRNN)
Cover定理:将复杂的模式分类问题非线性地投射到高维空间,将比投射到低维空间更可能是线性可分的。
在RBF网络中,将输入空间的模式(点)非线性地映射到一个高维空间的方式是:
设置一个隐层,令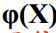
如果M足够大,则在隐层空间输入时线性可分的。
广义RBF网络(GRNN)
正规化RBF网络的隐层结点个数和输入样本个数相等,但是样本很大。
为了解决计算量很大的现象:
解决的方式:减少隐节点的个数,使得N<M<P
GRNN的基本思想:用径向基函数做为隐单元的”基”,构成隐含层空间。隐含层对输入向量进行变换,将低维空间的模式变换到高维空间内,使得低维空间内地线性不可分问题在高维空间内变得线性可分。
GRNN相比于RBF的特点:
1、M不等于N(M是隐层结点,N是输入节点)常远小于P(P是样本个数)
2、径向基函数的中心不再限制在数据点上,由训练算法确定
3、扩展常数不再统一,由训练算法确定
4、输出函数的线性中包括阈值参数,以补偿样本的平均值与目标平均值间的差别
5、GRNN多用于函数逼近问题。
概率神经网络(PNN)
特点:1、网络隐层神经元的个数Q等于输入矢量样本个数;输出神经元的个数等于训练样本拘束的种类个数(k)
2、输出层是竞争层,每个神经元对应于一类。
这种网络得到的分类结果能达到最大的正确概率。用于解决分类问题,当样本足够多的时候,收敛于一个贝叶斯分类器。
如何求一个矩阵和一个向量的范数
1、向量范数

2、矩阵范数



经验风险最小化和结构风险最小化
对于未知的概率分布,最小化风险函数,只有样本信息可以利用,这导致了定义的预测期望风险是无法直接计算和最小化的。
经验风险最小化原则(ERM)原则:使用对参数W求经验风险R的最小值 来 代替求期望风险Rw的最小值。
统计学习理论的核心内容
是小样本统计估计和预测学习的基本理论,从理论上系统地研究了经验风险最小化原则的条件,有限样本条件下,经验风险与期望风险的关系,以及如何应用改理论找到新的学习原则与方法等问题。
核心内容:
1、在经验风险最小话的原则下、统计学习的一致性条件
2、在这些条件下关于统计学习推广性的界的结论
3、在这些界的基础上,建立小样本归纳和推理原理
4、实现这些新的原则的实际算法
学习理论的关键定理
如果损失函数有界,则经验风险最小化学习一致的充要条件是

无免费午餐定理
不存在使适用于任何条件下的好方法,如果用推广能力来衡量方法的好坏,对人和算法,如果没有限制条件,其效果不会好于随机猜。
丑小鸭定理
如果不给出分类的目的,则世界上所有事物的相似程度是一样的。
神经网络的构造过程
先确定网络的结构:网络的层数、每层节点数,相当于VC维的确定和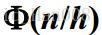
通过训练确定最优权值,相当于最小化
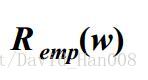
结构风险最小化(SRM)
SVM支持向量机就是在结构风险最小化上应用的
总结(推广能力,模型复杂度和样本量)
在有限样本的前提下:
1、经验风险最小,并不一定意味期望风险最小
2、机器学习的复杂性不但与所研究的系统有关,而且要和有限的学习样本想适应
3、用模型所含参数的多少作为模型复杂度的度量,这有的时候是不合理的
4、学习精度(深度)和推广能力似乎是一种不可调和的矛盾,采用复杂的机器学习使得误差很小,但是往往会丧失推广能力。
推广能力(泛化能力):机器对未来输出进行正确的预测的能力
在某些情况下,训练的误差过小,反而会导致推广能力下降(这就是过学习问题)
神经网络的过学习问题就是经验风险最小化准则失败的一个典型例子







Hopfield神经网络
联想存储器
记忆(存储)是生物系统一个独特而重要的功能;联想存储器(AM)是人脑记忆的一个重要形式
联想记忆有两个突出的特点:1、信息的存取是通过信息本身的额内容实验的
2、信息是分布存储的
离散型Hopfield神经网络


离散型Hopfield神经网络
稳定性定义:
若从某一时刻开始,网络中所有的神经元的状态不再发生改变,则称改网络是稳定的。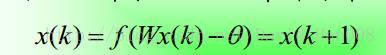
Hopfield神经网络是高维非线性系统,有许多个稳态。从任何初始状态开始运动,总可以到某个稳定状态,这些稳定的可以通过改变网络参数得到
稳定性定理:
串行稳定性–W:对称且对角元素非负
并行稳定性–W:对称,则总要收敛到一个稳定点或者是一个长度为2的震荡环
W:反对称且对角元素为0,在一定条件下,网络将收敛于一个长度为4的环


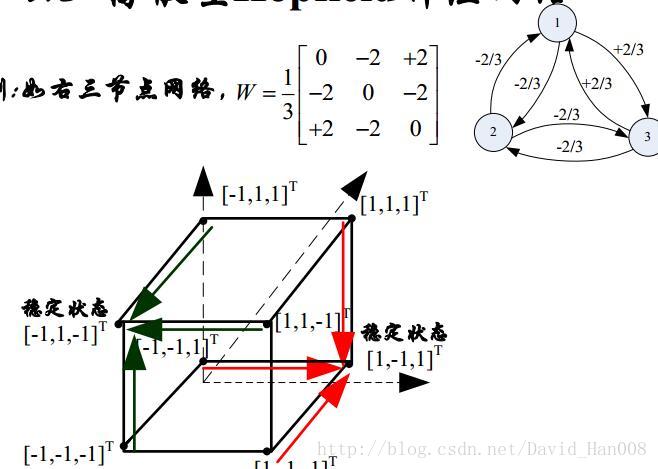
联想存储器的两个性质:


随机神经网络(模拟退火算法)
模拟退火算法(SA)

模拟退火算法最大的贡献在于,能以较大的概率求解复杂优化问题的全局解。SA算法可以分解为解空间,目标函数和初始解三部分。
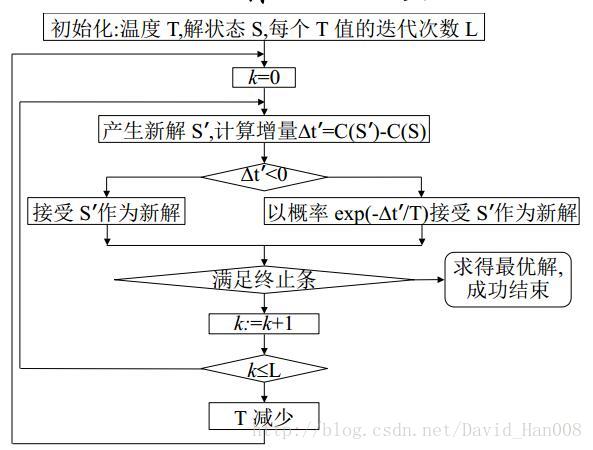




状态接受函数的引入是SA算法实现全局搜索的最关键因素

模拟退火算法的优势;

模拟退火算法的不足:

SA算法参数的控制问题



自组织系统 Hebb学习
自组织是指:其特定的结构和功能形成的,不是按照某种指令来完成的,而是由于系统内部要素彼此之间具有协调,相干或自发的默契行为,那么这种形式特定结构与功能的过程就是自组织。

竞争:竞争就是系统间或系统内个要素或各子系统间相互竞争,力图取得支配和主导地位的活动
协同:是指的系统中许多系统的联合作用,各要素之间或各子系统之间在演化过程中存在着联接,合作,协调和同步行为
自组织学习的必要前提:
只有当输入数据中存在冗余性时,非监督学习才得以进行,如果没有这种冗余性,非监督学习也无法发现数据中的重要特征或者模式。从这个意义上可以理解为:冗余性提供了知识。这种知识是自组织学习的必要前提。
主成分分析
主成分分析是一种通过降维技术吧多个变量化为少数几个主成分的统计分析方法。这些主成分能够反映原始变量的绝大部分信息。他们通常表示为原始变量的某种线性组合。
主成分分析的一般目的:1、变量降维。2、主成分的解释
主成分分析的计算例子:


竞争学习
竞争学习:网络的输出神经元之间相互竞争以求彼此激活,结果在每一时刻只有一个输出神经元激活。这个被激活的神经元称为竞争获胜神经元,而其他神经元被抑制,称为Winner Talk All.


自组织映射神经网络(SOM)
SOM网共有2层,输入层模拟感知外界输入信息的视网膜,输出层模拟做出相应的大脑皮层

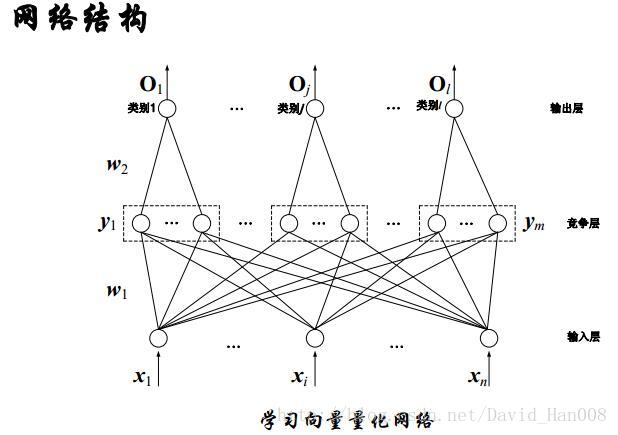
学习向量量化网络(LVQ)
向量量化(VO)是标量量化的扩展。他是把高维的数据离散化,邻近的区域作为同一量化等级,用其中心来代表。这种算法类似于逐次聚类算法,聚类中心是该类的代表,(中心称之为码本)。
组成:输入层神经元、竞争层神经元和输出层神经元。
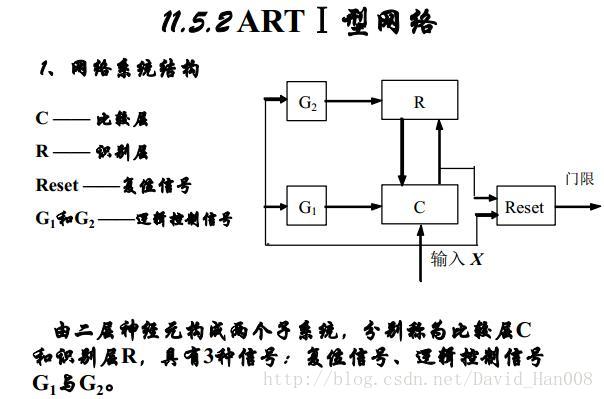
自适应共振理论(ART)

SOM网的结构特点是:输出层神经元可排列成线阵或者面阵
LVQ网络是对SVO网络所获得的聚类中心加以监督学习,以提高识别率。

贝叶斯网络以及其学习算法

贝叶斯分类器是用于分类的贝叶斯网络,改网络中通常包括类节点和一组节点
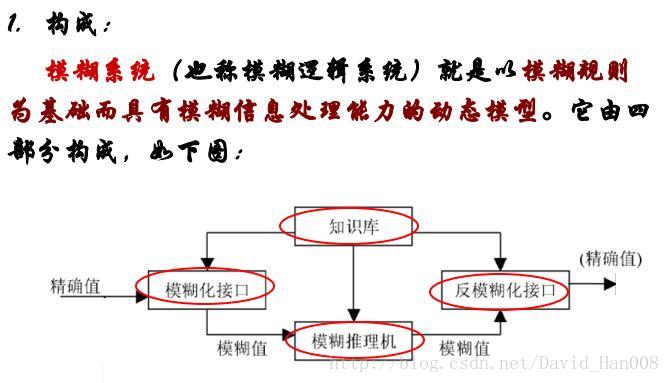
模糊神经网络



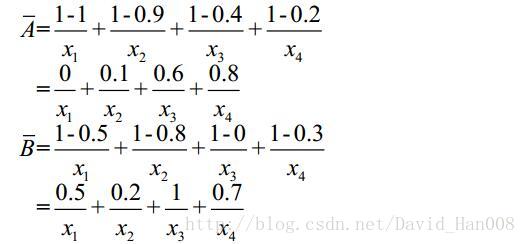



映射关系取最大值
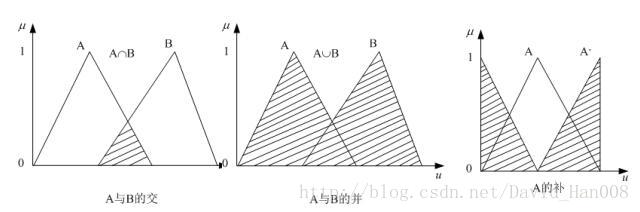
模糊关系的合成运算

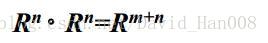
模糊系统和神经网络的区别与联系
1、模糊系统和神经网络都是计算智能和计算方法
2、从知识的表达方式来看
模糊系统可以表达人的经验性知识,便于理解
3、从知识的存储方式来看
模糊系统将知识存在规则集中
神经网络将知识存在权系数当中,具有分布存储的特点
4、从知识的运用方式来看
模糊系统和神经网络都具有并行处理的特点
模糊神经网络同时被激活的规则不多,计算量小
神经网络涉及的神经元很多,计算量大
5、从知识的获取方式来看
模糊系统的规则靠专家提供和设计,难于自动获取
神经网络的圈系数可由输入输出样本中学习,无需人来设置
模糊神经网络FNN

核方法与支持向量机
核函数的作用:平滑(低通滤波)相似性度量


进化计算


遗传算法(GA)



遗传算法包括三个基本操作:选择,交叉和变异


遗传算法五个基本要素:
1、参数编码
2、初始群体的设定
3、适应度函数的设计
4、遗传操作设计
5、控制参数设定
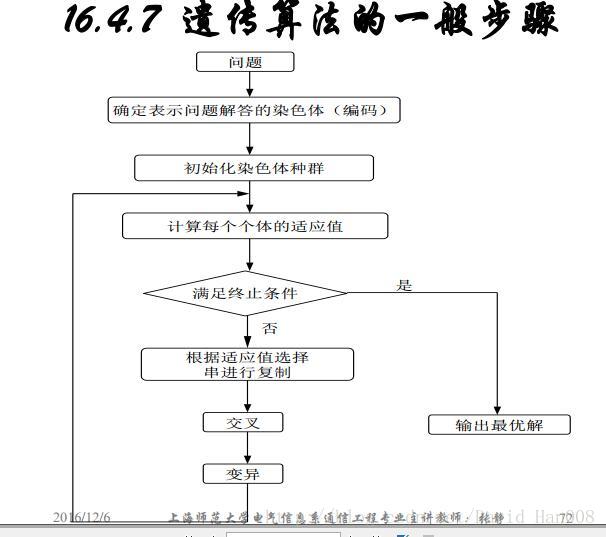

遗传算法的改进算法
1、双倍体遗传算法
2、双种群遗传算法
3、自适应遗传算法

















 816
816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









