







写在最前面:

SLAM特指:特指搭载传感器的主体,在没有环境先验的信息情况下,在运动过程中建立环境模型,通过估计自己的运动。
SLAM的目的是解决两个问题:1、定位 2、地图构建
也就是说,要一边估计出传感器自身的位置,一边要建立周围环境的模型
最终的目标:实时地,在没有先验知识的情况下进行定位和地图重建。
当相机作为传感器的时候,我们要做的就是根据一张张连续运动的图像,从中估计出相机的运动以及周围环境中的情况
需要大体了解的书籍:
1、概率机器人
2、计算机视觉中的多视图几何
3、机器人学中的状态估计
需要用的Eigen、Opencv、PCL、g2o、Ceres
安装Kdevelop
http://blog.163.com/beichen2012@126/blog/static/16793820820122224332943/
一些常见的传感器



单目(Monocular)、双目(Stereo)、深度相机(RGB-D)
深度相机能够读取每个像素离相机的距离
单目相机 只使用一个摄像头进行SLAM的做法叫做单目SLAM(Monocular SLAM),结构简单,成本低。
照片拍照的本质,就是在相机平面的一个投影,在这个过程当中丢失了这个场景的一个维度,就是深度(距离信息)

单目SLAM 估计的轨迹和地图,与真实的轨迹和地图之间相差一个因子,这就是所谓的尺度(scale)由于,单目SLAM无法凭借图像来确定真实的尺度,又称为尺度不确定
单目SLAM 的缺点:1、只有平移后才能计算深度 2、无法确定真实的尺度。
双目相机:

双目相机和深度相机的目的是,通过某种手段测量物体离我们之间的距离。如果知道这个距离,场景的三维结构就可以通过这个单个图像恢复出来,消除了尺度不确定性。
双目相机是由于两个单目相机组成,这两个相机之间的距离叫做基线(baseline)这个基线的值是已知的,我们通过这个基线的来估计每个像素的空间位置(就像是人通过左右眼的图像的差异,来判断物体的远近)
但是计算机双目相机需要大量的计算才能估计出每个像素点的深度。双目相机的测量到的深度范围与基线相关,基线的距离越大,能够检测到的距离就越远。双目的相机的缺点是:配置和标定都比较复杂,其深度测量和精度受到双目的基线和分辨率的限制,而且视差的计算非常消耗计算机的资源。因此在现有的条件下,计算量大是双目相机的主要问题之一。
深度相机是2010年左右开始兴起的一种相机,他的最大的特点就是采用红外结构光或者(Time-of-Flight)ToF原理,像激光传感器那样,主动向物体发射光并且接受返回的光,测量出物体离相机的距离。这部分并不像双目那样通过计算机计算来解决,而是通过物理测量的手段,可以节省大量的计算量。目前RGBD相机主要包括KinectV1/V2, Xtion live pro,Realsense,目前大多数的RGBD相机还存在测量范围小,噪声大,视野小,易受到日光干扰,无法测量透射材质等诸多问题。
经典视觉SLAM框架
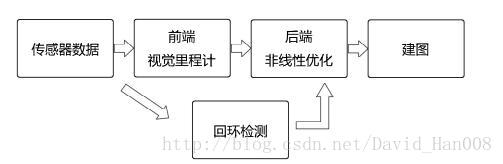
视觉slam的路程分成以下几步:
1、传感器信息的读取。
2、视觉里程计(Visual Odometry,VO)视觉里程计的任务是,估算相邻图像之间相机的运动,以及局部地图。VO也称为前端(Front End).
3、后端优化(Optimization)后端是接受不同时刻视觉里程计测量的相机位姿,以及回环检测的信息。(Back End)
4、回环检测(loop Closing)。回环检测是判断机器人是否或者曾经到达过先前的位置。如果检测到回环,它会吧信息提供给后端进行处理
5、建图(Mapping),他根据估计出的轨迹,建立与任务要求的对应的地图。
视觉里程计
视觉里程计关心的是,相邻图像之间相机的移动,最简单的情况就是计算两张图像之间的运动关系。
为了定量的估计相机的运动,必须了解相机与空间点的几何关系。
如果仅仅用视觉里程计来轨迹轨迹,将不可避免的出现累计漂移,注意,这个地方说的是累计漂移,
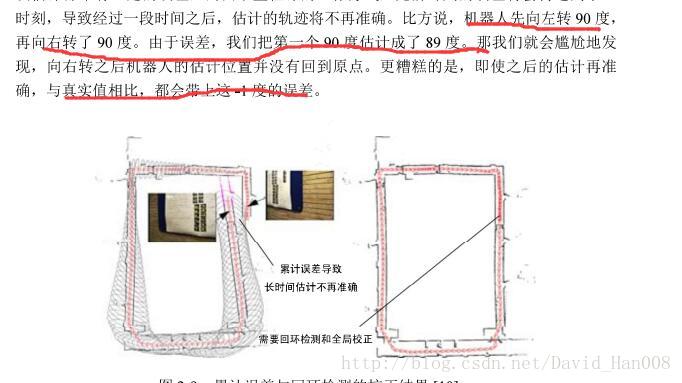
为了解决漂移问题。我们还需要两种检测技术:后端优化和回环检测的。回环检测负责吧“”机器人回到原来的位置“”这件事情给检测出来。而后端优化则是根据这个信息,优化整个轨迹形状
后端优化
后端优化主要是指在处理SLAM噪声问题,虽然我希望所有的数据都是准确的,但是在现实当中,再精确的传感器也是有一定噪声的。后端只要的考虑的问题,就是如何从带有噪声的数据中,估计出整个系统的状态,以及这个状态估计的不确定性有多大(最大后验概率(MAP))
视觉里程计(前端)给后端提供待优化的数据。
后端负责整体的优化过程,后端面对的只有数据,并不关系数据到底是来自哪个传感器。
在视觉SLAM当中,前端和计算机视觉领域更为相关,例如:图像的特征提取与匹配。后端只要是滤波和非线性优化算法。
回环检测
回环检测(闭环检测(Loop Closure Detection))主要是解决位置估计随时间漂移的问题。为了实现回环检测,我们需要让机器人具有识别曾经到达过场景的能力。通过判断图像之间的相似性,来完成回环检测。如果回环检测成功,可以显著地减小累计误差。所以视觉回环检测,实际上是一种计算图像数据相似性的算法。
建图
建图(Mapping)是指构建地图的过程。地图是对环境的描述,但是这个描述并不是固定。(如果是激光雷达的地图,就是一个二维的地图,如果是其他视觉slam 三维的点云图)
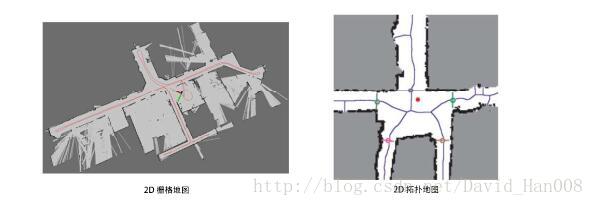
地图可以分成度量地图和拓扑地图两种。
1、度量地图(Metric Map)
度量地图强调的是精确表示出地图中物体的位置关系,通常我们用稀疏(Sparse)与稠密(Dense)对他们进行分类。稀疏地图进行了一定程度的抽象,并不需要表达所有物体。例如:我们需要一部分有代表意义的东西(简称为路标landmark),
这里的稀疏地图,就是又路标组成的地图。
相对于稀疏地图而言,稠密地图将建模所看到的所有的东西

对于定位而言:稀疏的路标地图就足够了。而要用于导航,我们往往需要稠密地图。
稠密地图通常按照分辨率,由许多个小块组成。二维的度量地图是许多小格子(Grid),三维则是许多小方块(Voxel)。一般而言,一个小方块,有占据,空闲,未知三种状态,来表达这个格子内是不是有物体。
一些用于视觉导航的算法 A*, D*,算法这种算法需要地图能够存储每个格点的状态,浪费了大量的存储空间。而且大多数情况下,地图的很多细节是无用的。另外,大规模度量地图有的时候回出现一致性问题。很小的一点转向误差,可能会导致两间屋子之间的墙出现重叠,使得地图失效。
2、拓扑地图(Topological Map)
相比于度量地图的精准性,拓扑地图则更强调了地图元素之间的关系。拓扑地图是一个图。这个图是由节点和边组成,只考虑节点间的连通性。它放松了地图对精确位置的需要,去掉了地图的细节问题,是一种更为紧凑的表达方式。
如何在拓扑图中,进行分割形成结点和边,如何使用拓扑地图进行导航和路径规划。
slam 的数学表述
通常机器人会携带一个测量自身运动的传感器,比如说码盘,或者惯性传感器。运动方程可以表示为:
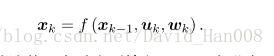

与运动方程相互对应的观测方程。

假设机器人在平面中运动,他的位姿由两个位置和一个转角来描述,也就是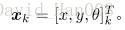
同时如果运动传感器能够检测到机器人每两个时间间隔位置和转角的变换量
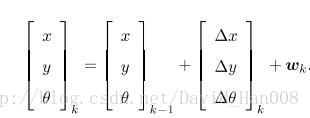
这是比较理想的状态下。现实是,并不是所有的传感器都可以直接测量出位置和角度的变化。
假如机器人携带的是一个二维的激光雷达。我们知道激光传感器观测一个2D路标是时候,能够测量到两个量,一个是路标边到机器人之间的距离r 另一个是夹角
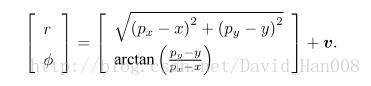
在考虑视觉SLAM时候,观测方程就是“对路标点拍摄后,得到了图像中的像素”的过程。
针对不同的传感器,这两个方程有不同的参数化。如果我们保持通用性,吧他们们抽象成通用的抽象形式,那么SLAM过程可总结为两个基本过程:

将SLAM问题建模成一个状态估计问题。状态估计问题的求解,与这个两个方程的具体的形式有关,以及噪声服从那种分布有关。我们按照运动和观测方程是否为线性,噪声是否服从高斯分布,分成线性/非线性和高斯/非高斯系统。其中线性高斯系统(Line Gaussian,LG系统)是最简单的,他的无偏的最优估计可以由卡尔曼滤波器给出。而在非线性,非高斯的系统中,我们会使用扩展卡尔曼滤波器(EKF)和非线性优化两大类方法求解它。直到21世纪早期,以EKF为主,占据了SLAM的主导地位。到今天视觉SLAM主要都是以图优化来进行状态估计
机器人一般都是6自由度,三维空间的运动由三个轴以及绕这个三个轴的旋转量组成。一共有6个自由度。
CMakeLists.txt
#“#”表示注释
#声明要求cmake的最低的版本
cmake_minimum_required(VERSION 2.8)
#声明一个工程
project(HelloSlam)
#添加一个可执行文件
#语法第三讲 三维空间的刚体运动



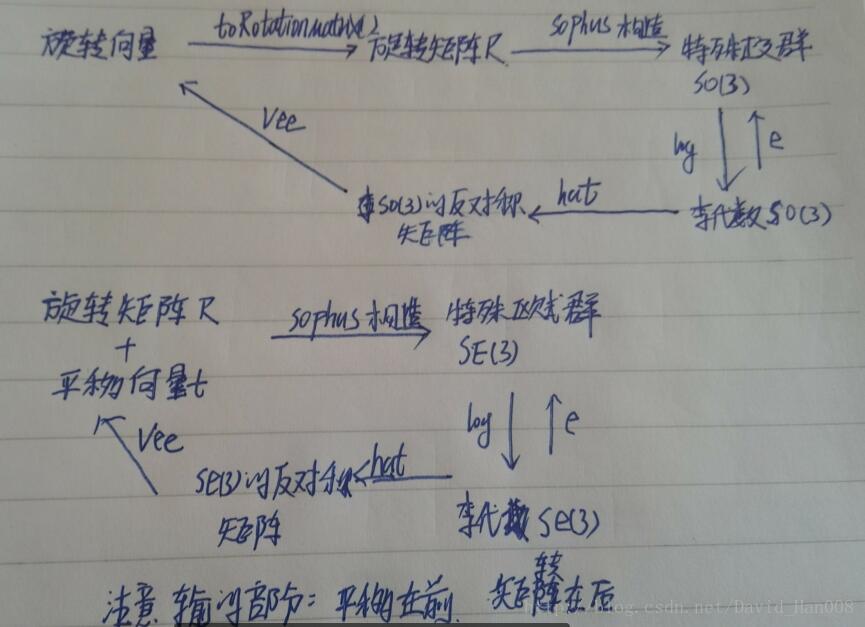
什么叫旋转向量:使用一个向量,他的方向和旋转轴一致,长度等于旋转角。(任意的一个旋转,都可以用旋转轴和旋转角来表示)这就是轴角Axis-Angle
Eigen::Matrix3d R = Eigen::AngleAxisd(M_PI/2, Eigen::Vector3d(0,0,1)).toRotationMatrix();任意的旋转都可以使用角轴来描述,那么前面的这个参数表示的旋转的角度,后面的这个参数旋转向量
然后我们现在已知了旋转矩阵,通过
在代码中是这样写的
Sophus::SO3 SO3_R(R); // Sophus::SO(3)可以直接从旋转矩阵构造 由旋转矩阵得到的当然还有以下几种写法
Sophus::SO3 SO3_R(R); // Sophus::SO(3)可以直接从旋转矩阵构造 由旋转矩阵得到的
Sophus::SO3 SO3_v( 0, 0, M_PI/2 ); // 亦可从旋转向量构造
Eigen::Quaterniond q(R); // 或者四元数 这里是将R变成一个四元数
Sophus::SO3 SO3_q( q );如何输出一个四元数
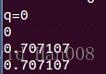
cout<<"q="<<q.coeffs()<<endl;这里coeffs输出的顺序是(x,y,z,w)前面的x,y,z为虚部 w是实部
Eigen::Vector3d t(1,0,0); // 沿X轴平移1
Sophus::SE3 SE3_Rt(R, t); // 从R,t构造SE(3)
Sophus::SE3 SE3_qt(q,t); // 从q,t构造SE(3)
cout<<"SE3 from R,t= "<<endl<<SE3_Rt<<endl;
cout<<"SE3 from q,t= "<<endl<<SE3_qt<<endl;
cout<<"se3 hat = "<<endl<<Sophus::SE3::hat(se3)<<endl;
cout<<"se3 hat vee = "<<Sophus::SE3::vee( Sophus::SE3::hat(se3) ).transpose()<<endl;总结:
一个刚体在三维空间中的运动是如何描述的。
平移是比较好描述的,旋转这件事比较困难。如何来描述旋转,我们使用:旋转矩阵、四元数、欧拉角
刚体:有位置信息,还需要有自身的姿态(姿态:就是相机的朝向)
结合起来:相机为与空间上(0,0,0)处,面朝正前方
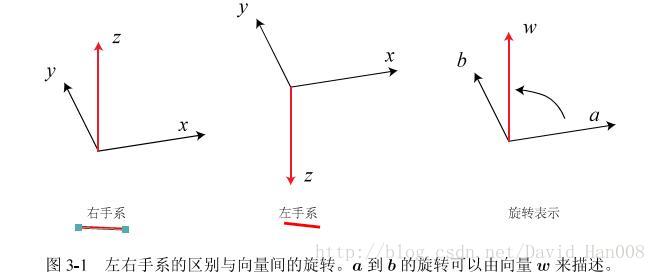
这是关于坐标系,我们通过坐标系来描述一个向量。
外积就是将外积表达式拆开成为第2个式子,然后再a拆开,b表示列向量就变成a^b
a^表示把a这个向量变成一个矩阵,这个矩阵是a的反对称矩阵,
反对称矩阵就是 矩阵a的转置等于-a
这里a与b的外积是一个行列式,
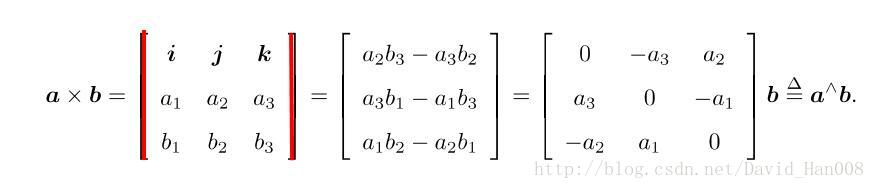
外积的物理意义是a和b组成的平行四边形的的面积
现在存在一个问题,同一个向量在不同的坐标系里面坐标该怎么表示?
在机器人运动过程中,我们设定的是惯性坐标系(世界坐标系),可以认为它是固定不动的
ZW,XW,YW是世界坐标系,ZC,XC,YC是相机的坐标系,P在相机坐标系中的坐标是PC,在世界坐标系中的坐标是PW,首先我们得到在相机坐标系中的 pc 然后通过变换矩阵T 来变换到PW
正交矩阵就是逆等于转置
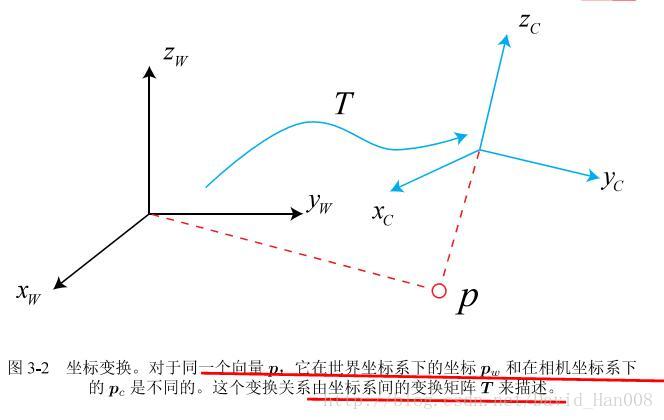
什么叫欧式变换?就是说同一个向量,在各个坐标系下的长度和夹角都不会发生改变。
欧式变换由一个旋转和一个平移两个部分组成(前提是刚体)
可以用旋转矩阵,来描述相机的旋转,旋转矩阵是一个行列式为1的正交矩阵。我们可以吧所有的旋转矩阵的集合定义如下:
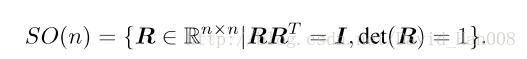
SO(n)是特殊正交群,这个集合由n维空间旋转矩阵组成,其中SO(3)就是三维空间的旋转,根据正交矩阵的性质,正交矩阵的逆和转置是一样的。
因此欧式空间的坐标变换可以写成:(一次旋转+一次平移)
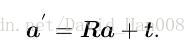
但是这个表达式是非线性的,因此我们需要重写
1、引入齐次坐标(也是用4个数来表达三维向量的做法)
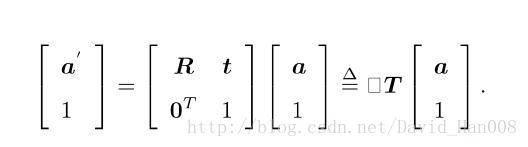
在三维向量的末尾添加1,成为4维向量,称为齐次坐标
这里要区分特殊欧式群和特殊正交群

实践部分,添加eigen的库
#include_directories("/usr/include/eigen3")不需要加入target_link
声明部分
Eigen只需要关心前面3个参数,分别是:数据类型,行,列
声明一个2行3列的float类型的矩阵
Eigen::Matrix<float,2,3>matrix_23;
声明一个3行1列的向量 这里的d表示double
Eigen::Vector3d v_3d;
声明一个double类型的3*3的矩阵,并且初始化为零
Eigen::Matrix3d matrix_33=Eigen::Matrix3d::zero();
当不确定矩阵的大小的时候,可以申请动态矩阵
Eigen::Matrix<double,Eigen::Dynamic,Eigen::Dynamix> matrix_dynamc;
同样,可以表示为:
Eigen::MatrixXd matrix_x;赋值部分
为矩阵赋值
matrix_23<<1,2,3,4,5,6;
访问矩阵内部存储的数值
for(int i=0;i<2;i++){
for(int j=0;j<3,j++){
cout<<matrix_23(i,j)<<"\t";
}
cout<<endl;
}矩阵的四则运算
v_3d<<3,2,1;
vd_3d<<4,5,6;
矩阵的类型是一样
Eigen::Matrix<double,2,1>result=matrix_23.cast<double>()*v_3d;//输入想要改变矩阵的类型
在一个矩阵的后面 .cast<double>() 将原来的float转化的double类型
Eigen::Matrix<float,2,1>result2=matrix_23*vd_3d;//默认条件下矩阵的类型矩阵的性质
产生随机数矩阵
matrix_33=Eigen::Matrix3d::Random();
求这个矩阵的转置
cout<<matrix_33.transpose()<<endl;
求这个矩阵各个元素的和
cout<<matrix_33.sum()<<endl;
求这个矩阵的迹(主对角线元素之和)
cout<<matrix_33.trace()<<endl;
求这个矩阵的数乘
cout<<matrix_33*10<<endl;
求这个矩阵的逆
cout<<matrix_33.inverse()<<endl;
求这个矩阵的行列式
cout<<matrix_33.determinant()<<endl;
求解特征值和特征向量
Eigen::SelgAdjointEigenSlover<Eigen::Matirx> eigen_solver(matrix_33);
cout<<eigen_solver.eigenvalues()<<endl;
cout<<eigen_solver.eigenvectors()<<endl;
求解方程:例如求解 NN*X=V_Nd 这个方程
首先定义这几个变量
Eigen::Matrix< double, MATRIX_SIZE, MATRIX_SIZE > matrix_NN;
matrix_NN = Eigen::MatrixXd::Random( MATRIX_SIZE, MATRIX_SIZE );
Eigen::Matrix< double, MATRIX_SIZE, 1> v_Nd;
v_Nd = Eigen::MatrixXd::Random( MATRIX_SIZE,1 );
clock_t time_stt=clock();//用来计时
第一种方法:直接求逆
Eigen::Matrix<double,MATRIX_SIZE,1> x = matrix_NN.inverse()*v_Nd;
然后输出计算的时间
cout <<"time use in normal invers is " << 1000* (clock() - time_stt)/(double)CLOCKS_PER_SEC << "ms"<< endl;
第二种方法:使用QR分解来求解
time_stt = clock();
x = matrix_NN.colPivHouseholderQr().solve(v_Nd);
cout <<"time use in Qr compsition is " <<1000* (clock() - time_stt)/(double)CLOCKS_PER_SEC <<"ms" << endl;当矩阵的规模庞大的时候,使用QR分解更加高效
QR分解也叫做正交三角分解,把矩阵分解成一个正交矩阵与一个上三角矩阵的积。通常用来求解线性最小二乘法的问题
QR求解的方法:
- Givens变换求矩阵的QR分解
- Householder变换又称为反射变换或者镜像变换
- Gram-Schmidt正交化
由于旋转矩阵是用9个量来描述旋转的,并且有正交性约束和行列式值约束
我们希望能够一种更加紧凑的方式来系统的描述旋转和平移
因此,我们换了一种方式进行比较,就是需旋转轴和旋转角因此我们使用一个向量,这个向量的方向和旋转轴一致,长度等于旋转角,这种向量,称为旋转向量(或者轴角,Axis-Angle),也可以叫做角轴, 这种方法的优势在于,只需要一个三维的向量,就可以描述旋转。
作为一个承上启下的部分,旋转向量和旋转矩阵是如何转化呢?假设有一个旋转轴为n,角度为A,那么他对应的旋转向量是An,由轴角到旋转矩阵的过程由于罗德里格斯公式表明:

因此 旋转矩阵到轴角的表示方法:


欧拉角
优势:直观
欧拉角使用的三个分离的转角,把一次旋转分解成三次绕不同的轴的旋转
其中较为常用的ZYX轴旋转
欧拉角会出现奇异值(万向锁问题)
- 物体绕Z轴旋转之后得到偏航角yaw
- 绕Y轴之后得到俯仰角pitch
- 绕X轴旋转之后得到滚动角roll
因此我们可以使用[r,p,y]来表示任意的旋转 rpy角的旋转顺序是ZYX
RPY的参考链接:
http://blog.csdn.net/heroacool/article/details/70568858
缺陷:这种方法会碰到万向锁的问题,在俯仰角pitch为+- 90度的时候,第一次旋转和第三次旋转使用的同一个轴,使得系统丢失一个自由度。也成为万向锁
由于这个问题,欧拉角不适合用于插值和迭代,往往只是用于人机交互中,同样也不会在滤波和优化中使用欧拉角来表达旋转(因为具有奇异性)
四元数
旋转矩阵用9个量,来描述3自由度的旋转,具有冗余性,而欧拉角和旋转向量具有奇异性
在工程当中使用的四元数来存储机器人轨迹和旋转
例如,当我们想要用二维的量来表示地球表面的时候,必然会出现奇异性,例如,经纬度在+-90度的地方,毫无意义,因此想要表示三维的刚体的时候,我们就打算用四元数。四元数的优势在于1、紧凑,2、没有奇异性
一个四元数拥有一个实部和3个虚部 本质上是一种扩展复数,描述3维的量,用四元数



如何用四元数来表示三维刚体的旋转
假设,某个旋转是绕单位向量

结论在四元数中,任意旋转都可以有两个互为相反数的四元数来表示。
四元数到旋转矩阵的变换方式

反之,由旋转矩阵到四元数的变换如下:假设矩阵R={mij},其对应的四元数是:

相似、仿射、射影变换
这三种变换都会改变原来物体的外形
相似变换比欧式变换对了一个自由度,它允许物体进行均匀的缩放,其矩阵表示为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3118
3118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









