








关于TensorRT的介绍可以参考: http://blog.csdn.net/fengbingchun/article/details/78469551
以下是参考TensorRT 2.1.2中的sampleMNIST.cpp文件改写的实现对手写数字0-9识别的测试代码,各个文件内容如下:
common.hpp:
#ifndef FBC_TENSORRT_TEST_COMMON_HPP_
#define FBC_TENSORRT_TEST_COMMON_HPP_
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#include <NvInfer.h>
template< typename T >
static inline int check_Cuda(T result, const char * const func, const char * const file, const int line)
{
if (result) {
fprintf(stderr, "Error CUDA: at %s: %d, error code=%d, func: %s\n", file, line, static_cast<unsigned int>(result), func);
cudaDeviceReset(); // Make sure we call CUDA Device Reset before exiting
return -1;
}
}
template< typename T >
static inline int check(T result, const char * const func, const char * const file, const int line)
{
if (result) {
fprintf(stderr, "Error: at %s: %d, error code=%d, func: %s\n", file, line, static_cast<unsigned int>(result), func);
return -1;
}
}
#define checkCudaErrors(val) check_Cuda((val), __FUNCTION__, __FILE__, __LINE__)
#define checkErrors(val) check((val), __FUNCTION__, __FILE__, __LINE__)
#define CHECK(x) { \
if (x) {} \
else { fprintf(stderr, "Check Failed: %s, file: %s, line: %d\n", #x, __FILE__, __LINE__); return -1; } \
}
// Logger for GIE info/warning/errors
class Logger : public nvinfer1::ILogger
{
void log(Severity severity, const char* msg) override
{
// suppress info-level messages
if (severity != Severity::kINFO)
std::cout << msg << std::endl;
}
};
#endif // FBC_TENSORRT_TEST_COMMON_HPP_#include <iostream>
#include <string>
#include <tuple>
#include <cuda_runtime_api.h>
#include <NvInfer.h>
#include <NvCaffeParser.h>
#include <opencv2/opencv.hpp>
#include "common.hpp"
// reference: TensorRT-2.1.2/samples/sampleMNIST/sampleMNIST.cpp
typedef std::tuple<int, int, int, std::string, std::string> DATA_INFO; // intput width, input height, output size, input blob name, output blob name
static int caffeToGIEModel(const std::string& deployFile, // name for caffe prototxt
const std::string& modelFile, // name for model
const std::vector<std::string>& outputs, // network outputs
unsigned int maxBatchSize, // batch size - NB must be at least as large as the batch we want to run with)
nvinfer1::IHostMemory *&gieModelStream, // output buffer for the GIE model
Logger logger)
{
// create the builder
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(logger);
// parse the caffe model to populate the network, then set the outputs
nvinfer1::INetworkDefinition* network = builder->createNetwork();
nvcaffeparser1::ICaffeParser* parser = nvcaffeparser1::createCaffeParser();
const nvcaffeparser1::IBlobNameToTensor* blobNameToTensor = parser->parse(deployFile.c_str(), modelFile.c_str(), *network, nvinfer1::DataType::kFLOAT);
// specify which tensors are outputs
for (auto& s : outputs)
network->markOutput(*blobNameToTensor->find(s.c_str()));
// Build the engine
builder->setMaxBatchSize(maxBatchSize);
builder->setMaxWorkspaceSize(1 << 20);
nvinfer1::ICudaEngine* engine = builder->buildCudaEngine(*network);
CHECK(engine != nullptr);
// we don't need the network any more, and we can destroy the parser
network->destroy();
parser->destroy();
// serialize the engine, then close everything down
gieModelStream = engine->serialize();
engine->destroy();
builder->destroy();
nvcaffeparser1::shutdownProtobufLibrary(); / Note
return 0;
}
static int doInference(nvinfer1::IExecutionContext& context, const float* input, float* output, int batchSize, const DATA_INFO& info)
{
const nvinfer1::ICudaEngine& engine = context.getEngine();
// input and output buffer pointers that we pass to the engine - the engine requires exactly IEngine::getNbBindings(),
// of these, but in this case we know that there is exactly one input and one output.
CHECK(engine.getNbBindings() == 2);
void* buffers[2];
// In order to bind the buffers, we need to know the names of the input and output tensors.
// note that indices are guaranteed to be less than IEngine::getNbBindings()
int inputIndex = engine.getBindingIndex(std::get<3>(info).c_str()),
outputIndex = engine.getBindingIndex(std::get<4>(info).c_str());
// create GPU buffers and a stream
checkCudaErrors(cudaMalloc(&buffers[inputIndex], batchSize * std::get<1>(info) * std::get<0>(info) * sizeof(float)));
checkCudaErrors(cudaMalloc(&buffers[outputIndex], batchSize * std::get<2>(info) * sizeof(float)));
cudaStream_t stream;
checkCudaErrors(cudaStreamCreate(&stream));
// DMA the input to the GPU, execute the batch asynchronously, and DMA it back:
checkCudaErrors(cudaMemcpyAsync(buffers[inputIndex], input, batchSize * std::get<1>(info) * std::get<0>(info) * sizeof(float), cudaMemcpyHostToDevice, stream));
context.enqueue(batchSize, buffers, stream, nullptr);
checkCudaErrors(cudaMemcpyAsync(output, buffers[outputIndex], batchSize * std::get<2>(info) * sizeof(float), cudaMemcpyDeviceToHost, stream));
cudaStreamSynchronize(stream);
// release the stream and the buffers
cudaStreamDestroy(stream);
checkCudaErrors(cudaFree(buffers[inputIndex]));
checkCudaErrors(cudaFree(buffers[outputIndex]));
return 0;
}
int test_mnist()
{
// stuff we know about the network and the caffe input/output blobs
const DATA_INFO info(28, 28, 10, "data", "prob");
const std::string deploy_file {"models/mnist.prototxt"};
const std::string model_file {"models/mnist.caffemodel"};
const std::string mean_file {"models/mnist_mean.binaryproto"};
const std::vector<std::string> output_blobs_name{std::get<4>(info)};
Logger logger; // multiple instances of IRuntime and/or IBuilder must all use the same logger
// create a GIE model from the caffe model and serialize it to a stream
nvinfer1::IHostMemory* gieModelStream{ nullptr };
caffeToGIEModel(deploy_file, model_file, output_blobs_name, 1, gieModelStream, logger);
// parse the mean file and subtract it from the image
nvcaffeparser1::ICaffeParser* parser = nvcaffeparser1::createCaffeParser();
nvcaffeparser1::IBinaryProtoBlob* meanBlob = parser->parseBinaryProto(mean_file.c_str());
parser->destroy();
// deserialize the engine
nvinfer1::IRuntime* runtime = nvinfer1::createInferRuntime(logger);
nvinfer1::ICudaEngine* engine = runtime->deserializeCudaEngine(gieModelStream->data(), gieModelStream->size(), nullptr);
nvinfer1::IExecutionContext* context = engine->createExecutionContext();
const float* meanData = reinterpret_cast<const float*>(meanBlob->getData());
const std::string image_path{ "images/digit/" };
for (int i = 0; i < 10; ++i) {
const std::string image_name = image_path + std::to_string(i) + ".png";
cv::Mat mat = cv::imread(image_name, 0);
if (!mat.data) {
fprintf(stderr, "read image fail: %s\n", image_name.c_str());
return -1;
}
cv::resize(mat, mat, cv::Size(std::get<0>(info), std::get<1>(info)));
mat.convertTo(mat, CV_32FC1);
float data[std::get<1>(info)*std::get<0>(info)];
const float* p = (float*)mat.data;
for (int j = 0; j < std::get<1>(info)*std::get<0>(info); ++j) {
data[j] = p[j] - meanData[j];
}
// run inference
float prob[std::get<2>(info)];
doInference(*context, data, prob, 1, info);
float val{-1.f};
int idx{-1};
for (int t = 0; t < std::get<2>(info); ++t) {
if (val < prob[t]) {
val = prob[t];
idx = t;
}
}
fprintf(stdout, "expected value: %d, actual value: %d, probability: %f\n", i, idx, val);
}
meanBlob->destroy();
if (gieModelStream) gieModelStream->destroy();
// destroy the engine
context->destroy();
engine->destroy();
runtime->destroy();
return 0;
}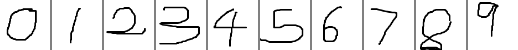

测试代码编译步骤如下(ReadMe.txt):
在Linux下通过CMake编译TensorRT_Test中的测试代码步骤:
1. 将终端定位到CUDA_Test/prj/linux_tensorrt_cmake,依次执行如下命令:
$ mkdir build
$ cd build
$ cmake ..
$ make (生成TensorRT_Test执行文件)
$ ln -s ../../../test_data/models ./ (将models目录软链接到build目录下)
$ ln -s ../../../test_data/images ./ (将images目录软链接到build目录下)
$ ./TensorRT_Test
2. 对于有需要用OpenCV参与的读取图像的操作,需要先将对应文件中的图像路径修改为Linux支持的路径格式













 728
728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









