










解决下载(或叫:爬取)到的网页乱码问题
使用的系统:Windows 10 64位
Python 语言版本:Python 2.7.10 V
使用的编程 Python 的集成开发环境:PyCharm 2016 04
我使用的 urllib 的版本:urllib2
注意: 我没这里使用的是 Python2 ,而不是Python3
上一节,我介绍了如何下载网页。这样节我们来讲:如果我们下载一个带有中文的网站,或者日文的网站,终止就是不全是英文的网站,解决乱码问题。
一 . 解释乱码原因
Q: 为什么会出现乱码问题?
A: 编码方式不匹配导致的。
Q: 请具体说明一下?
A: 好的。
我先将上一节 编写的download() 函数的代码贴出来:
import urllib2
def download(url, user_agent='wswp', num_retries=2):
print 'Downloading: ', url
headers = {'User-agent' : user_agent}
request = urllib2.Request(url, headers=headers)
try:
html = urllib2.urlopen(request).read()
except urllib2.URLError as e:
print 'Download error', e.reason
html = None
if num_retries > 0:
if num_retries > 0:
if hasattr(e, 'code') and 500 <= e.code < 600:
# recursively retry 5xx HTTP errors
return download(url, user_agent, num_retries-1)
return html在 download()函数 里面,我们使用 html = urllib2.urlopen(request).read() 这句代码得到网页的源代码(str数据)。那么得到的源代码是使用什么编码方式编码的str字符串呢?是使用网页源代码中 charset属性设定的编码方式编码的str字符串。
比如:我们就来爬取本博客的源代码。我们可以在浏览器上查看到 本网页的编码方式是 utf-8 。所以,当你执行:html = download('xxx') 命令后,html 里面存储的就是一个以utf-8编码方式编码的字符串。
接着,我们就使用 print html 命令将其打印到终端上。PyCharm软件上有两个终端,一个是PyCharm软件自带的终端窗口:Run窗口;另一个就是Terminal窗口,Terminal窗口不是PyCharm软件自带的,它就是 Windows系统的DOS窗口。(如果是Linux系统,这个Terminal窗口就是 Console窗口)。
在 Run 窗口 :
打开 Setting 。
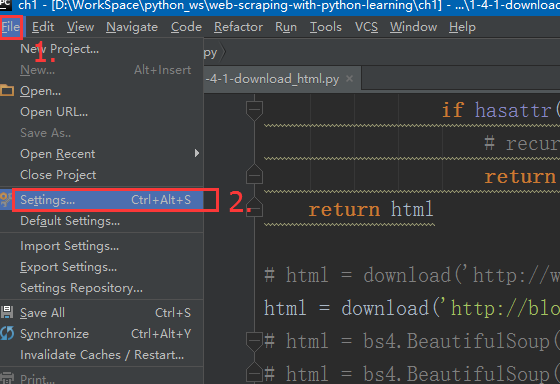
选择 Editor -> Code Style -> File Encodings ,将 Project Encoding 项设置为:UTF-8。
这样,我Run 窗口里面打印的内容都会按照UTF-8 编码的方式进行编码,然后显示在Run窗口里。
我们的代码中的 print html 这句话可以正常的将 html字符串里面的内容正常的打印到 Run 窗口里,不会有乱码的问题。
在 Terminal 窗口 :
假设,我们现在在 Terminal窗口里使用命令 运行这个 Python脚本。那么 print html 这段代码,会在Terminal窗口里面打印html 这个被utf-8编码方式编码的str字符串里面的内容。如果Terminal窗口显示字符串的编码方式也是 utf-8 的话,那么就不会有乱码的情况发生。
但是,你要知道:我们安装 Windows 系统的时候,设置的是 简体中文(默认),所以DOS窗口(命令提示符窗口)里显示的内容是被使用 gb2312 编码方式进行编码的。所以如果我们要显示 UTF-8 字符就会乱码。
在DOS窗口(或者 PyCharm软件中的Terminal窗口)中执行下面的命令来查看现在Windows系统使用的编码方式:
chcp输出:(936 就是 gb2312编码的编号。)
活动代码页: 936你可以到这个网站里进行查表。
Windows系统使用的是 ANSI编码方式,ANSI 不是一个编码,它是一个总称。如果你在安装Windows系统的时候,选择 简体中文(默认),那么 ANSI 在你的电脑里指的就是gb2321编码。Windows系统中所有的文件都是会被 gb2321 编码方式进行编码,所以,你在Windows上新建的
txt文件都是gb2321编码文件。
那么这个时候如果我有一个 其他编码的文件,比如UTF-8文件,你要是在 DOS窗口中使用type filename.txt命令打开它,你所看到的就是一堆乱码。
那么这个时候我们怎么办?怎样在 Terminal窗口 中显示正确的 html 字符串里面正确的内容呢?我们只需要改写 print html 这句代码就可以,将其修改为:print html.decode('utf-8').encode('GB18030')。
我来解释一下这句代码:代码中的 .decode('utf-8') 的意思是:将 html 字符串(str)通过 utf-8 编码方式解码为Unicode字节(Bytes);接着 .encode('GB18030') 的意思是:将 解码得到的 Unicode字节(Bytes) 使用 GB18030编码方式 再编码成 Str字符串 (str)。
通过这样的转换,在 Terminal窗口中,就可以正常的被 gb2312编码方式正确的解析,并显示出来。(但是现在的代码,在 Run窗口上运行,就会是乱码了。你应该知道为什么。我不讲了。)
Q: 为什么要使用
GB18030编码方式,不是要使用gb2312吗?
A: gb2312、GBK、GB18030 这三个编码方式其实可以看做是等价的关系。但是它们里面的编码的汉字数量不用,从少到多排序为:gb2312 < GBK < GB18030。有的网页虽然它的源代码中的charset属性写的是gb2312或者,GBK ,我们还是使用 GB18030编码最保险,使用其他的两个可能不会成功。
总结:
我们使用的是 Windows 系统上的 PyCharm 软件 做为我们开发的继承开发环境。
所谓:工欲善其事,必先利其器。PyCharm 软件上可以运行程序的有两个窗口:Run窗口 和 Terminal窗口。
我们应该统一 Run窗口 和 Terminal窗口 的编码方式,既然设置不了 Terminal 窗口的编码方式,那我们以后让 Run窗口 和 Terminal窗口 的编码方式都统一为 GBK 编码。这样,我们的程序就可以在这两个窗口里运用出同样的结果。(以后都使用 print html.decode('网页源代码的charset属性').encode('GB18030') 这样的代码打印信息。)
将 Pycharm软件的 Project Encoding 项设置为:GBK 即可统一Run窗口 和 Terminal窗口的编码方式。
二 . 扩展:如何使用程序获取网页的编码方式
获取网页的编码方式,即网页源代码中 charset 属性的值:
使用 Python 第三方库:chardet。
下载:(在DOS窗口中执行下面的命令)
C:\Python27\Scritp\pip.exe install chardet使用:
html = download('http://blog.csdn.net/github_35160620/article/details/52203682')
import chardet
charset = chardet.detect(html)['encoding']
print charset运行输出:
utf-8注意: 之前有的地方给写错了。现在已经修改正确。
2016-12-27 09:58:23
贤贤加油这为朋友的提醒:
- chardet 是我们使用的第三方库。
charset是网页源代码里面存放编码方式的变量。
三 . 练习
题目:爬取目标网站:http://www.dytt8.net/
分析:目标网站的源代码中,charset 属性值为:gb2312
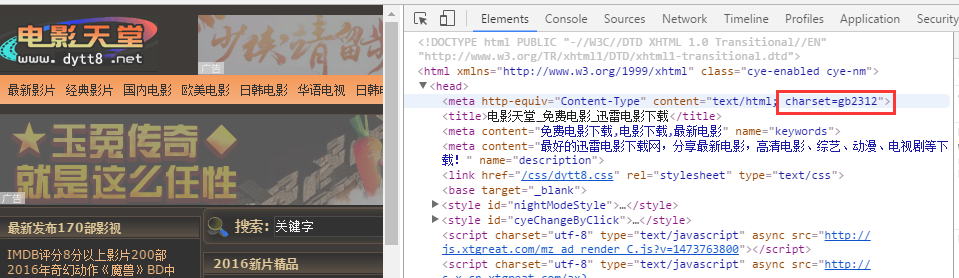
所以,爬虫代码是:
html = download('http://www.dytt8.net/')
print html 其中 print html 这段代码也可以写成:print html.decode('GBK').encode('GB18030')
运行:现在,不管是 Run窗口,还是Terminal窗口,还是Windows 的 DOS窗口,显示都是正常的,没有乱码。
现在,我已经知道了为什么会出现乱码,也知道了如何解决乱码问题,现在我们就可以修改 download() 函数,将其变成一个永远都不会出现乱码问题的函数。
四 . 最终的 download() 函数的程序:
#-*- coding:utf-8 -*-
import urllib2
import chardet
def download(url, user_agent='wswp', num_retries=2):
print 'Downloading: ', url
headers = {'User-agent' : user_agent}
request = urllib2.Request(url, headers=headers)
try:
html = urllib2.urlopen(request).read()
charset = chardet.detect(html)['encoding']
if charset == 'GB2312' or charset == 'gb2312':
html = html.decode('GBK').encode('GB18030')
else:
html = html.decode(charset).encode('GB18030')
except urllib2.URLError as e:
print 'Download error', e.reason
html = None
if num_retries > 0:
if num_retries > 0:
if hasattr(e, 'code') and 500 <= e.code < 600:
# recursively retry 5xx HTTP errors
return download(url, user_agent, num_retries-1)
return html
这样,对于任何目标网页,我需要执行下面的代码,就可以在输出窗口中打印出没有乱码的目标网页源代码。
html = download('网页的网站')
print html搞定
对了,我在说说这个 #-*- coding:utf-8 -*- 这段注释的用处:
如果你的.py 文件中有中文注释,会在非英文的注释,你就必须在Python脚本 的最前面加上这句注释。否则程序运行时会报错:
SyntaxError: Non-ASCII character '\xe9' in file filename.py on line 6, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details总结:
这样,我们在的download() 函数就完美了。
这个 download() 现在是一个灵活的下载程序,该函数能够捕获异常,并且可以自动尝试重新下载,并且我们设置了自定义的用户代理(user_agent),并且还解决了中文或其他非英文语言的乱码问题。
下一节,我介绍 下载一个站点里所有网页的方法1 — 使用网站地图 来下载一个站点里所有包含的网页源代码。

















 1595
1595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









