




 本文介绍了自然语言处理中CNN模型的Max Pooling操作,包括Max Pooling Over Time、K-Max Pooling和Chunk-Max Pooling。Max Pooling虽能减少模型参数,但会丢失位置信息;K-Max Pooling和Chunk-Max Pooling则在一定程度上保留了特征的相对顺序和强度信息,适合关注位置信息的任务。
本文介绍了自然语言处理中CNN模型的Max Pooling操作,包括Max Pooling Over Time、K-Max Pooling和Chunk-Max Pooling。Max Pooling虽能减少模型参数,但会丢失位置信息;K-Max Pooling和Chunk-Max Pooling则在一定程度上保留了特征的相对顺序和强度信息,适合关注位置信息的任务。
/* 版权声明:可以任意转载,转载时请标明文章原始出处和作者信息 .*/
author: 张俊林
(想更系统地学习深度学习知识?请参考:深度学习枕边书)
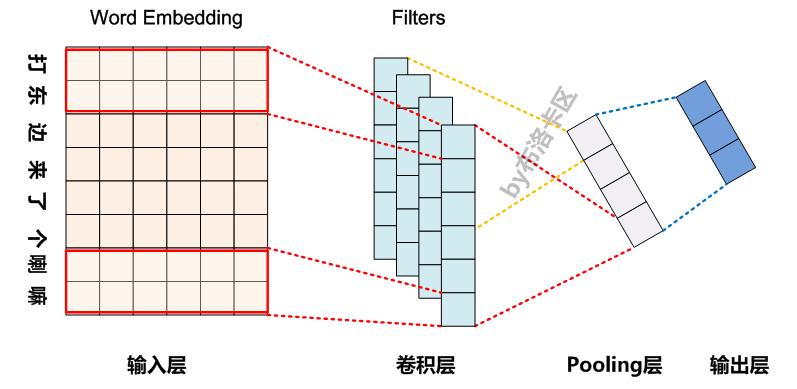
CNN是目前自然语言处理中和RNN并驾齐驱的两种最常见的深度学习模型。图1展示了在NLP任务中使用CNN模型的典型网络结构。一般而言,输入的字或者词用Word Embedding的方式表达,这样本来一维的文本信息输入就转换成了二维的输入结构,假设输入X包含m个字符,而每个字符的Word Embedding的长度为d,那么输入就是m*d的二维向量。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 772
772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









