









2016年9月14日,山世光老师开源其人脸识别的一套模型,SeetaFace,并且带着源码,包括人脸检测,人脸对齐,人脸识别,三个模块,算是把人脸这一套的都有了。github的星星也转眼间就上了百,为此本屌丝也在工作之余对其性能进行了测试。
Face Detection:
检测部分速度有点慢,继续开了openmp也没感觉有啥能感觉到的提速。实际效果如下:

Face Alignment:
对齐部分对偏转角度太大的就会出现漂移现象,总体来看,不如SDM给力。

Face Identification:
其自带的feats.dat的测试结果:
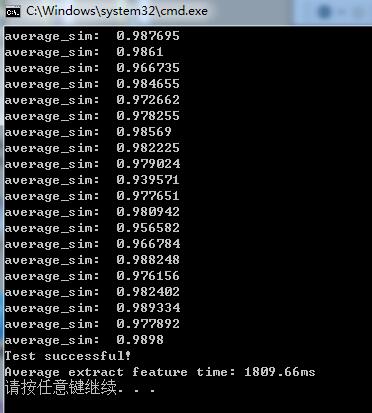
从上面的结果来看,比对的分数感觉还是蛮高的,感觉很靠谱的样子。但是这个,作者只给了其自己找的相似的图片的特征文件,并没有给出原始图片。那么到底这个原始图像和实际作者提供的图像有度相似呢?这个大家就都不知道了。
带着这个疑问,本屌丝对原始程序进行了修改,并实际找了Adience里面的几个图片进行了测试。

上图为本人的处理后(进行了crop和alignment,并归一化到了256*256),也就是说和作者的训练模型保持了一致性。比对为基数和偶数的图像进行比对。实际比对分数如下:
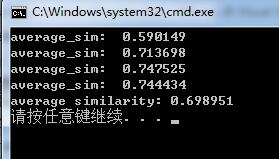
这个分数和作者自己的分数一对比,差距还是蛮大的。算法的折扣也就降低了不少。
个人疑问:
(1)作者只给出了feats.dat,但是大家都不知道其图片和提供的图片到底有多相似,本屌丝实际测试的结果是,2个一模一样的图片给出事1分的相似度,我自己找的图片测试的是在0.7徘徊。简单的说,0.9和0.7的分数是2个区别很大的算法和模型,直接就定义出了好坏。
(2)作者自己提供的模型,读取进来单步看的是256*256,但是作者提供的crop图像是128*128的,这个我也不理解。
总体:
检测部分,速度有点慢,误检率小,漏检率稍微大
对齐部分,还是可以的,但是效果肯定不会有SDM好
识别部分,按我自己的测试结果,对于变化比较大的2个同样的人,0.7的徘徊分数,不是一个可以实际产品话的算法,个人认为不如DeepID好。
其实,这些都不重要,开源精神最值得钦佩。
本人改好的程序:
tips:强烈建议下载本人所改的识别程序,因为,
(1)里面进行了大的改动,对Blob模块进行了Mat格式的封装,加入了保存对齐的crop图像的功能(表情识别,性别,年龄,眼镜等都用得到,相当于一个对齐工具,并附带源码)。
( 2 )本人将检测,对齐,识别, 3 个模块集成到 1 个函数,随便输入 2 个自己的图片,就可以自动扣出图中的人脸进行比对识别,非常方便。
另外,感谢热心网友,小四掰,对我的博文提出的疑问,这次进行了更正与改进。如有疑问,欢迎大家留言或私信,本人将本着实事求是的原则,相互学习,共同进步。
官方下载链接:https://github.com/seetaface/SeetaFaceEngine
本人改好的链接:
检测:http://download.csdn.net/detail/qq_14845119/9639840
对齐:http://download.csdn.net/detail/qq_14845119/9639841
识别:http://download.csdn.net/detail/qq_14845119/9642948
Reference:http://www.weixinla.com/document/58132439.html















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









