







 S3FD是一种改进版的SSD,专注于解决人脸尺度问题。它通过设计等效感受野和补偿匹配策略提升小尺度人脸检测性能,同时减少误检。在FDDB上表现出色。
S3FD是一种改进版的SSD,专注于解决人脸尺度问题。它通过设计等效感受野和补偿匹配策略提升小尺度人脸检测性能,同时减少误检。在FDDB上表现出色。
一篇同样着重处理人脸尺度问题的检测文章。
方法可以看作是对SSD的改进与完善,速度较慢(36FPS with Titan X & VGA)。
文章链接: 《S3FD: Single Shot Scale-invariant Face Detector》
code will be available at https://github.com/sfzhang15/SFD
1. 方法介绍
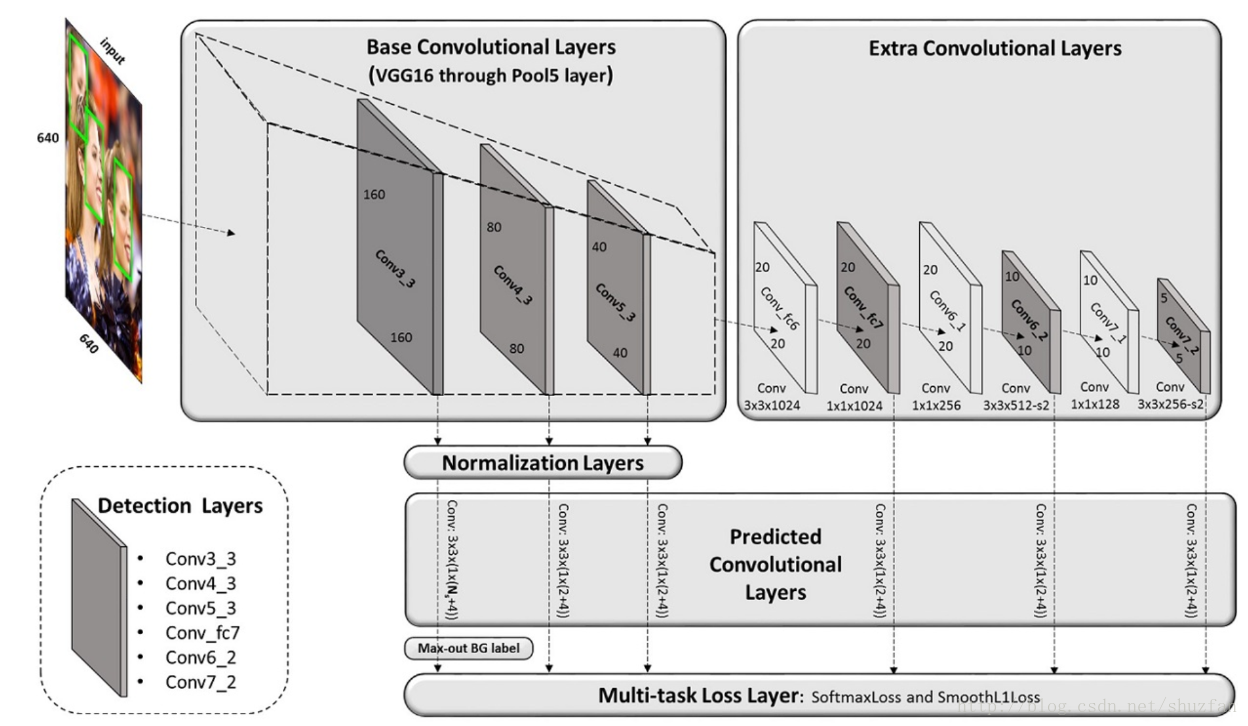
如上图,整体方法结构和SSD一致,在不同层使用不同尺度的anchor预测目标。
2. 要点介绍
(1)Reasons behind the problem of anchor-based methods
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 363
363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









