






Direct3D 10系统(一)
译注:这篇文章是MS在SIGGraph 2006上发表的论文,点击这里下载原文
摘要
本文描述了第四代PC平台上图形图像单元(GPU)的系统构架。与上一代图形管道相比,新的管道有了重大改变,引入了一个新的可编程阶段(stage)用于生产额外的图元,并把图元流保存到内存中;扩展了所有可编程阶段的功能,涉及到顶点、图片内存资源,以及新的储存格式。此外,我们还描述了API、运行时以及实现新管道的着色语言的结构性改变。解决当前系统中的缺陷,是我们设计的基本思想。文章不但描述了重要设计抉择背后的原理,同时也描述了那些最终被否决的方案。
1.前言
过去10年,OpenGL和Direct3D所依赖的渲染管道构架已经取得了重大发展。最近5年中,随着从固定管道到可编程管道的过渡,发生了许多戏剧性的变化。虽然变化的进程很快,但每一步都反映出了设计者在通用性、性能以及成本上所做出的妥协。
我们一直在努力了解以及构建一个系统,来解决许多程序中对图形加速器的需求(呈现图形、CAD、多媒体处理,等等)。但是,我们更想把注意力集中在交互式娱乐应用中。这些程序需要管理数十亿字节的艺术品,包括几何体、纹理、动画数据以及着色程序,占用大量系统资源(CPU、内存、带宽),以可交互的速率渲染丰富的、充满细节的图片。在处理海量数据的同时,保证渲染的灵活性,是对设计者的重大挑战之一。在系统设计的方方面面,都可以反映出我们对这个问题的解决方案。
与上个版本的Direct3D一样,Direct3D 10同样是在应用程序开发者、硬件设计师以及API/运行时构架师三方的合作下设计的。在三年多的设计过程中,合作者之间详细的交流是无价的,让我们更深入了软硬件部署的代价,以及在大量不同硬件进行权衡。在开发Direct3D 10的过程中,调查显示应用程序开发者通常受以下限制的困扰,以及用来缓解这些问题的策略:
1. 状态(state)改变的代价过高。 改变任何类型的状态(顶点格式、纹理、shader、shader参数、混合模式,等等)都会付出很大代价。优化方法通常是通过查询对象状态来排序,减少API状态改变次数;减少外观的改变;或者使用基于shader的技术,使用shader来决定状态。对于后者,例子之一就是把多张纹理打包为一张纹理地图(texture map)(也称为纹理地图集),通过纹理坐标变换,来索引相应的子纹理。
2. 硬件加速器性能变化太多。 应用程序不得不编写一系列分支语句,以保证在不同硬件上都能正常运行。这些问题会影响到程序的特性设置,资源管理,算法精度,以及储存格式。
3. CPU和GPU之间频繁的同步。传统的图形管道允许有限制的重新使用管道当前产生的数据,作为下一个处理步骤的输入数据。Render-to-texture就是这种机制的最好例子之一,所渲染的图片接下来能被当作纹理使用,最小化CPU的干涉。但是,产生新顶点数据,或者创建立方贴图就需要CPU与GPU进行更多的协调和通信,降低了效率。
4. 指令以及数据类型的限制。通常都以精度和所支持的流程控制指令来衡量vertex shader,同样的方法也用来衡量pixel shader,但是,无论是pixel还是vertex shader都不支持整数指令。此外,出于对pixel shader精确性的要求,还指定了浮点算法。应用程序要么不使用这些额外的功能,要么模仿他们的使用。基于表格功能的计算就是例子之一。
5. 资源限制。 纹理读取的次数、纹理范围、程序指令,等等,都受到限制。应用程序不得不压缩算法,或者把它们分为多个shader pass。因此,还出现了对自动划分shader程序的研究。
2.背景
我们的系统建立于PC,工作站以及游戏机平台上的应用程序可编程渲染管道。当前的图形管道分为两个编程阶段,一个用于处理顶点数据(vertex shader),一个用来处理像素或片断(fragment or pixel shader)。在Lindholm2001里描述了设计早期vertex shader的思想和折中。除了细小的差别以外,pixel shader也是按这样的轨迹来设计的。可以把顶点以及像素着色器的发展分为4代(包括Direct3D 10),如表一所示:
通过挖掘顶点和像素片断之间的独立性,硬件管道实现了很高的处理吞吐量。大多数顶点和像素着色器都是以并行的状态来处理相互独立的顶点和像素片断。典型的硬件实现中pixel shader的数量要比vertex shader多很多,反映出典型的渲染过程中,像素处理的工作量要比顶点多很多。与vertex shader相比,这种特性将影响pixel shader的性能,因为pixel shader被过多的复制了。
可编程管道直接使用了较低的抽象层,比如OpenGL或Direct3D。这些抽象层隐藏了不同硬件管道实现之间的差别,提供了一个方便的接口。对特定的平台来说,比如游戏机,它的硬件管道与PC平台相比是不同的,底层细节也是由这些抽象层来暴露。
我们把这些抽象层称为运行时(runtime),并且通过它所提供的API对他进行控制。运行时为设备提供了独立的资源管理(分配内存,控制生存期,初始化,虚拟技术,等等),所有纹理贴图,顶点缓冲,状态改变以及和硬件加速器的通信都通过特定设备的驱动程序来完成。对可变成管道来说,运行时还加入了对照色程序的抽象和管理任务。
由于早期可编程处理器对指令储存空间的限制,为了在有限资源内,最大化对硬件的控制,不得不使用类似于汇编的语言来编写照色程序。但是,随着硬件功能的增加,需要一种高级的编程抽象来提高程序员的生产力。一种与C类似,并且添加了对潜在渲染管道进行定制的编程语言满足了这种需求。此外,还发展出了一些其他的语言,利用浮点处理器和GPU内存带宽来完成渲染以外的一些计算,但是,我们不打算在这篇文章里对这些应用进行讨论。
虽然新的编程语言有必要与CPU编程语言(特别是C)类似,但我们还是进行了一些重要的修饰。举例来说,硬件结构和编译模型更像是一台虚拟机,汇编着色语言扮演了独立于硬件的中间语言(IL),而不是特定的机器语言。在离线环境下,Microsoft HLSL之类的高级语言被编译为IL,在程序运行时,通过驱动程序内建的翻译器,实时转换为目标硬件的指令。需要注意的是,OpenGL shading language使用了一种不同的方法来完成运行时的编译过程。
另一个重要的区别是,着色程序并不是孤立的程序,通过一个运行在CPU上的程序来协调渲染管道,它们通常是共同(in concert)执行的。 此外CPU程序还以纹理或填充寄存器常量的方式,为着色程序提供参数。
虽然本文没有具体描述特定硬件新图形管道的构架,但图形管道的设计很大程度上都是根据硬件实用性以及多硬件并行处理来设计的。此外,当前硬件实现的结构体系也将延续或者影响我们的设计。
3.图形管道
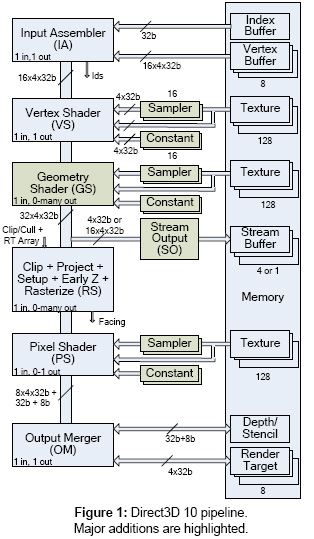
Direct3D保留了通用硬件加速器的3D管道结构。我们添加了两个新的阶段,并对其他的阶段进行了简化或者进一步归纳(generalized)。基本的图形管道如图1所示。为了保证文章的连续性,我们将讨论图形管道的每一个阶段,而不是只讨论新增的两个阶段。为了和以前的术语一致,使用了通用的术语,比如 顶点(vertex),纹理(texture)以及像素(pixel),但需要注意,这些术语只表示普通用法中的某些特定含义。
Input Assembler(IA)从附加到顶点缓冲上的8个输入流中接收1D的顶点数据,并且把数据项转换为规范的格式(比如,float32)。可以为每个流指定独立的顶点结构,每种结构最多包含16个域(也称为元素,element)。每种元素可以由1到4个基本数据项组成(比如,float32s)。通过读取当前的有效流来装配(assembled)顶点。一般来说,将会连续的从顶点缓冲中读取顶点数据,但是,如果指定了索引缓冲,那么每个流将使用共享的索引来计算每个顶点缓冲中顶点数据的偏移值。指定索引可以带来额外的性能优化,顶点处理器将根据索引值计算结果,通过用索引值作索引的结果缓存,可以避免使用相同索引重新计结果(译注:这里的结果因该是指顶点数据序列)。
此外,IA还提供了一种机制,允许IA高效的复制对象n次。这种机制是实现instancing的解决方案,把包含k个顶点的数据块(block)复制n次。同时,将使用当前的实体(instance),图元(primitive),以及顶点id对图元数据进行“标记(tagged)”,在可编程阶段,可以访问这些id,以便计算变换,材质等参数。
Vertex Shader(VS) 通常用来把顶点从模型空间变换到裁剪空间。VS读取一个顶点,输出一个顶点。VS与其它可编程阶段一样,有一些共同的特性,包括支持扩展的浮点、整数、控制类型,可以访问128块内存缓冲(纹理)以及16个参数(常量)冲。我们会在第四节详细讨论这些通用核心(common core)。
Geometry Shader(GS) 把同一图元的所有顶点作为输入,产生新的顶点或者图元。输入和输出图元的类型不一定要匹配,但对着色程序程序来说是固定的。以发射额外图元对象的方式,GS程序可以增加输入图元的数量,每一次调用(per-invocation)最多产生1024个32-bit的顶点数据。三角形和线段被输出为连续的顶点带。在一次调用中,GS程序可以输出1个以上的图形带,或者删除输入的图元,不进行任何输出。GS程序同样可以在不产生新几何体的情况下,把额外的属性附加到图元上,比如为每个图元计算额外的属性。由于可以访问当前图元的所有顶点,因此,计算三角形平面方程(triangle’s plane equation)之类的几何属性将会容易。
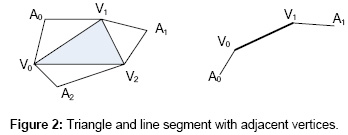
除了输入图元之外,还可以处理三角形和线段的邻接顶点。每个三角形包含三个顶点,以及三个邻接顶点,而每条线段则包含2个顶点以及2个邻接顶点。对于三角形和线段来说,邻接顶点将作为顶点缓冲格式的一部份,当指定(渲染)了带邻接的图元拓扑之后,IA会对提取邻接顶点。
Stream Output(SO)将把GS输出的顶点信息复制为4个连续的输出缓冲子集。理想情况下,SO的输出能力(不带索引)应该和IA(8 streams * 16 elements)的输入能力相匹配,但硬件代价是不合理的。SO只能输出一个1~16元素的流,或者4个单一元素的流。此外, IA可以读取8或者16bit的数据类型,并把他们转换为float32,而SO只能写入原始的32-bit的数据类型。但是,数据类型转换和打包可以在GS程序中轻易实现,减少了固定功能的支持。
Set-up and Rasterization Stage(RS) 是一个功能固定的阶段,用来处理剪切(clipping),剔除(culling),透视划分,观察点变化,图元设置,裁剪(scissoring),深度偏移,以及片断(fragment)生成。现代GPU设计总是包含某种形势的早期深度处理(z-cull,hierarchical-z)。我们将明确讨论这种优化,因为对应用程序开发者来说,它变的不太透明了。RS的输入是单一图元的顶点以及属性,输出一系列像素片断。
Pixel shader程序指定了通过顶点属性插值产生片断属性的方式(no interpolation, non-perspective-corrected interpolation, or perspective-corrected interpolation)。现代GPU通常支持多采样抗锯齿。当一个片断不包含像素的中心时,需要很小心的指定属性赋值行为,因为中心点的值有可能超出范围。通过片断边界,可以使用赋值限定器(质心centroid)来指定所需的值。
Pixel Shader(PS)读取单一像素片断的属性,输出包含1~8个属性(颜色)以及任意深度值的单一片断。每个属性值(元素)要么被分别写入单独的颜色缓冲中(称为渲染目标),要么完全丢弃(不输出片断)。一般情况下,深度和stencil值来自于RS。PS可以可以替些深度值,但无法改变stencil值。无论是丢弃像素还是重写深度值,都有可能影响RS中的深度处理优化(depth-processing optimizations),因为这样做会改变片断的可见性。
Output Merger(OM)接收来自于PS的片断,执行普通的 stencil和深度测试操作,以及渲染目标混合。OM为一个统一的depth / stencil缓冲以及8个其他的渲染目标(属性缓冲)指定了约束点(bind point)。Pixel shader必须分别为每个渲染目标输出单独的值(不支持多点传送)。此外,所有的渲染目标都共享一种混合功能,但是,可以对每个渲染目标独立的激活或者屏蔽混合。
~~~~~~~~~~~~~~~~~~~·未完待续·~~~~~~~~~~~~~~~~~~~~~~~~
难啊,难啊,看的我头晕脑胀。
终于又回到家了,昆明天气还是那么凉快,舒服啊,呵呵。















 2777
2777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









