







 本文详细解读了《Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks》论文,介绍了MTCNN框架,包括P-Net、N-Net和O-Net三个阶段的级联检测与特征点定位,以及在线硬样本挖掘和bounding box regression等关键算法。实验证明,该方法在保持高精度的同时,具备快速检测速度,适合于移动设备应用。
本文详细解读了《Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks》论文,介绍了MTCNN框架,包括P-Net、N-Net和O-Net三个阶段的级联检测与特征点定位,以及在线硬样本挖掘和bounding box regression等关键算法。实验证明,该方法在保持高精度的同时,具备快速检测速度,适合于移动设备应用。
《Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks》论文解读。
本文来自于中国科学院深圳先进技术研究院,目前发表在arXiv上,是2016年4月份的文章,算是比较新的文章。
论文地址:
概述
相比于R-CNN系列通用检测方法,本文更加针对人脸检测这一专门的任务,速度和精度都有足够的提升。R-CNN,Fast R-CNN,FasterR-CNN这一系列的方法不是一篇博客能讲清楚的,有兴趣可以找相关论文阅读。类似于TCDCN,本文提出了一种Multi-task的人脸检测框架,将人脸检测和人脸特征点检测同时进行。论文使用3个CNN级联的方式,和Viola-Jones类似,实现了coarse-to-fine的算法结构。
框架
算法流程
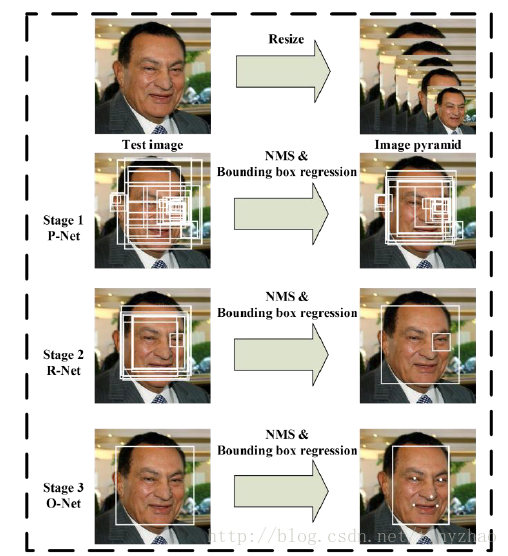
当给定一张照片的时候,将其缩放到不同尺度形成图像金字塔,以达到尺度不变。
Stage 1:使用P-Net是一个全卷积网络,用来生成候选窗和边框回归向量(bounding box regression vectors)。使用Bounding box regression的方法来校正这些候选窗,使用非极大值抑制(NMS)合并重叠的候选框。全卷积网络和Faster R-CNN中的RPN一脉相承。
Stage 2:使用N-Net改善候选窗。将通过P-Net的候选窗输入R-Net中,拒绝掉大部分false的窗口,继续使用Bounding box regression和NMS合并。
Stage 3:最后使用O-Net输出最终的人脸框和特征点位置。和第二步类似,但是不同的是生成5个特征点位置。
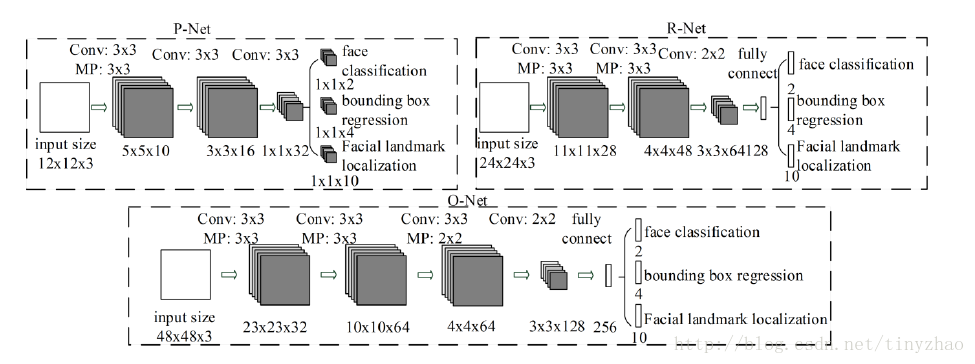
CNN结构
本文使用三个CNN,结构如图:
训练
这个算法需要实现三个任务的学习:人脸非人脸的分类,bounding box regression和人脸特征点定位。
(1)人脸检测
这就是一个分类任务,使用交叉熵损失函数即可:
(2)Bounding box regression
这是一个回归问题,使用平方和损失函数:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









