







dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。
过拟合是深度神经网(DNN)中的一个常见问题:模型只学会在训练集上分类,这些年提出的许多过拟合问题的解决方案,其中dropout具有简单性而且效果也非常良好。
算法概述
我们知道如果要训练一个大型的网络,而训练数据很少的话,那么很容易引起过拟合,一般情况我们会想到用正则化、或者减小网络规模。然而Hinton在2012年文献:《Improving neural networks by preventing co-adaptation of feature detectors》提出了,在每次训练的时候,随机让一半的特征检测器停过工作,这样可以提高网络的泛化能力,Hinton又把它称之为dropout。
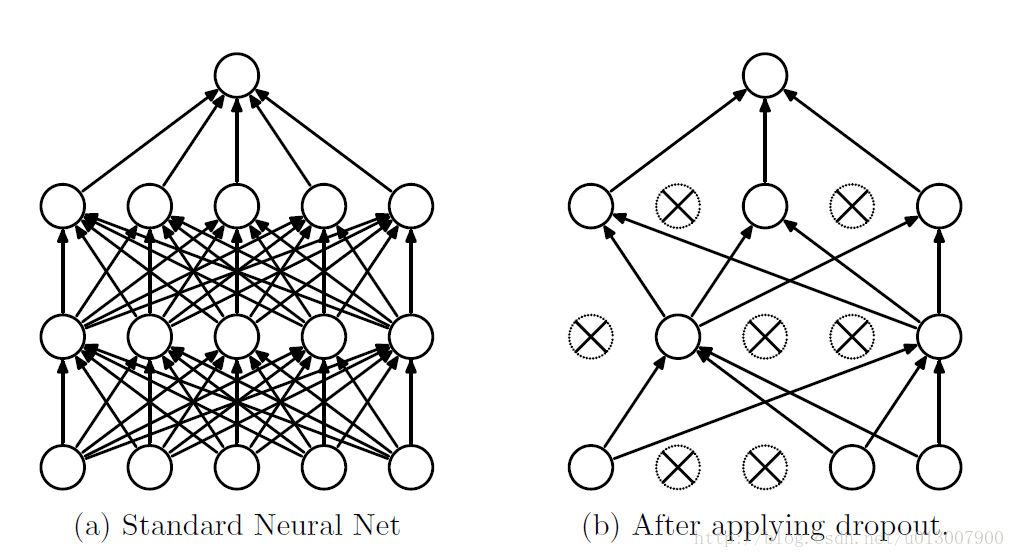
第一种理解方式是,在每次训练的时候使用dropout,每个神经元有百分之50的概率被移除,这样可以使得一个神经元的训练不依赖于另外一个神经元,同样也就使得特征之间的协同作用被减弱。Hinton认为,过拟合可以通过阻止某些特征的协同作用来缓解。
第二种理解方式是,我们可以把dropout当做一种多模型效果平均的方式。对于减少测试集中的错误,我们可以将多个不同神经网络的预测结果取平均,而因为dropout的随机性,我们每次dropout后,网络模型都可以看成是一个不同结构的神经网络,而此时要训练的参数数目却是不变的,这就解脱了训练多个独立的不同神经网络的时耗问题。在测试输出的时候,将输出权重除以二,从而达到类似平均的效果。
需要注意的是如果采用dropout,训练时间大大延长,但是对测试阶段没影响。
带dropout的训练过程
而为了达到ensemble的特性,有了dropout后,神经网络的训练和预测就会发生一些变化。在这里使用的是dropout以 p 的概率舍弃神经元
训练层面
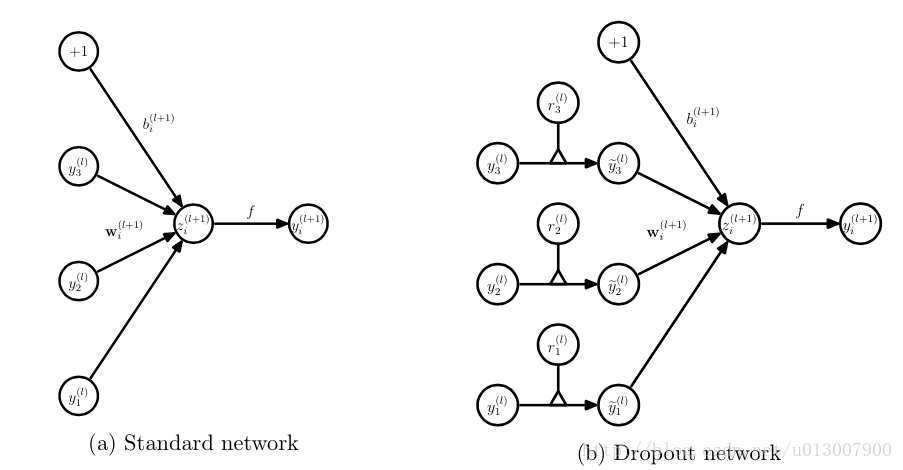
对应的公式变化如下如下:
没有dropout的神经网络
有dropout的神经网络
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 872
872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









