







 本文探讨了端到端记忆网络(End-to-End Memory Networks)如何解决AI研究中的多步计算和长距离依赖问题。通过介绍模型结构,包括输入记忆表示、注意力机制和支持记忆,以及多层模型的构建方式,阐述了其在问答任务中的应用。文章还讨论了模型细节,如句子记忆表示的不同方式,并提供了相关资源和数据集信息。
本文探讨了端到端记忆网络(End-to-End Memory Networks)如何解决AI研究中的多步计算和长距离依赖问题。通过介绍模型结构,包括输入记忆表示、注意力机制和支持记忆,以及多层模型的构建方式,阐述了其在问答任务中的应用。文章还讨论了模型细节,如句子记忆表示的不同方式,并提供了相关资源和数据集信息。
关键词
End2End, Memory Networks, Multiple hops
来源
arXiv 2015.03.31 (published at NIPS 2015)
问题
当前 AI 研究面临两大问题:
- 如何在回答问题时实现多个计算步骤
- 如何描述序列数据的长距离依赖性
本文尝试从 Memory Networks 入手,解决这两个问题。
文章思路
模型介绍 在单层模型中模型将 document 中的每一个 word 保存为一个 memory mi ,每个memory 本质上就是一个向量,这一点与 embedding 是一回事,只是换了一个名词。另外每个 word 还与一个输出向量 ci 相关联。可以理解为每个 word 表示为两组不同的 embedding A 和 C。同样的道理,query 中的每个单词可以用一个向量来表示,即对应着另一个 embedding B。
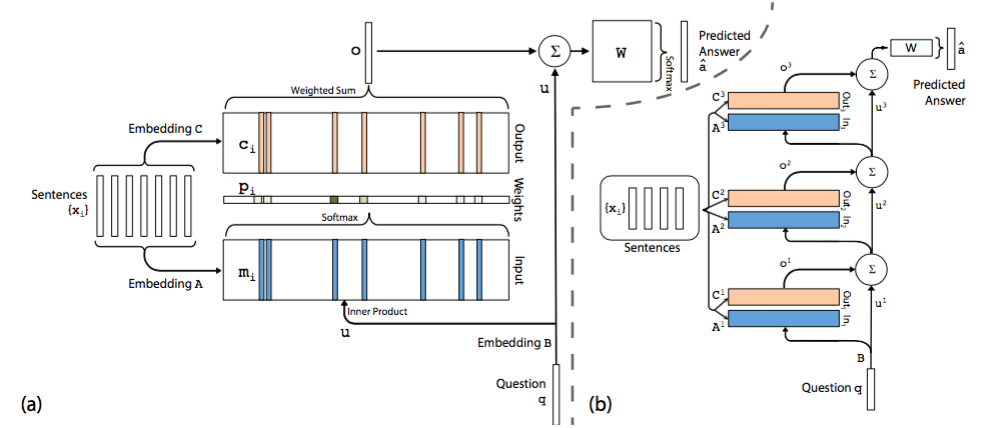
在 Input memory 表示层,用 query 向量与 document 中每个单词的 mi 作内积,再用 softmax 归一化得到一组权重,这组权重就是 attention,即 query 与 document 中每个 word 的相关度。
接下来,将权重与 document 中的另一组 embedding ci 作加权平均得到 Output memory 的表示。这一步也称作 support memory。
最后,利用 query 的表示和 output memory 的表示去预测answer。
根据单层模型的结构,非常容易构造出多层模型。每一层的 query 表示等于上一层 query 表示与上一层输出 memory 表示的和 (还有很多其他结合方式)。每一层中的 A 和 C embedding 有两种模式:
- 第一种是邻接,即 Ak+1=Ck ,依次递推
- 第二种是类似于 RNN 中共享权重的模式,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 666
666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









