







一.迭代思想
这里要写的其实跟主题梯度下降是没有关系的。但是它能够让非常新的新手体会循环往复的迭代修改一个或者多个值到最优的思想。所以这里把这个列到最开始,随便看看体会一下就行了。
假设我们现在要来求解一个线性方程组,
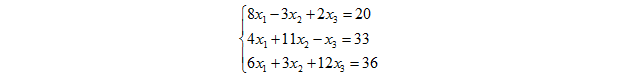
这个方程组很容易,可以用各种方法来解.精确的解容易求出来为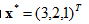
现在我们把原来的方程记为另外一种形式:
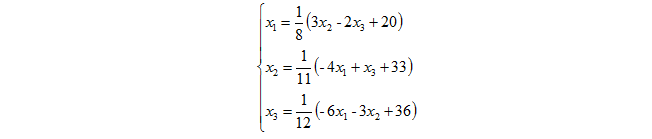
写为向量形式为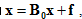
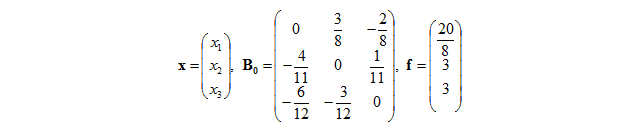
现在任意取初始值,比如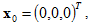
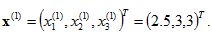
在这里,迭代其实就是
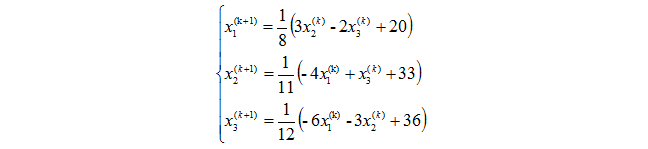
即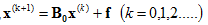
迭代10次之后得到:

下面用Python直观的验证一下
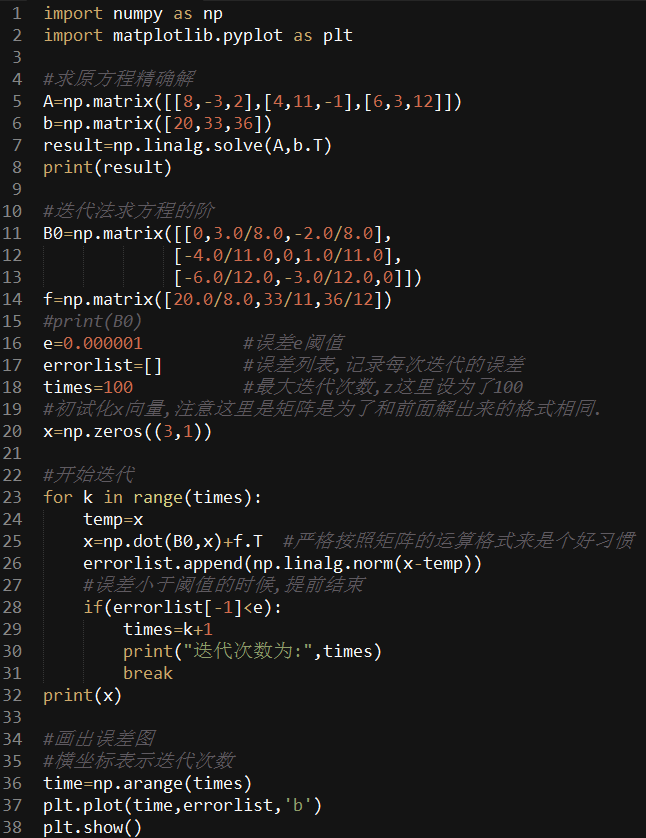
结果为
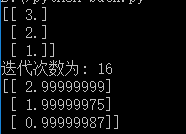
结果逼近于精确的结果.得到的误差曲线为
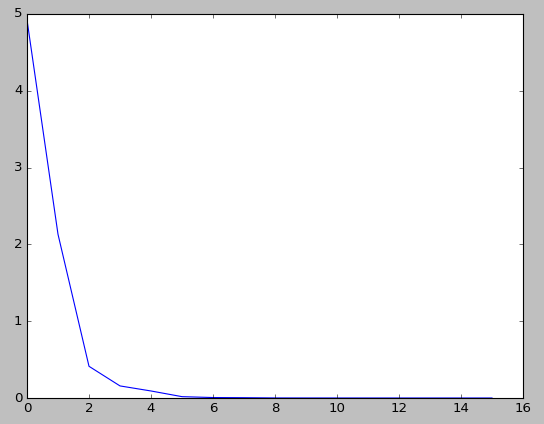
可以看出,在第三次迭代之后误差就已经很小了.
到这里,你应该对于迭代有一个感性的认识了。循环往复不停迭代而已。
二.梯度下降法
梯度下降法应该是你在机器学习里面经常听说的名词了,那么怎么理解梯度下降法呢?
首先先讲讲抽象的理论上的东西。
Ⅰ.实值函数相对于实向量的梯度
定义:以n×1实向量x为变量的实标量函数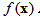
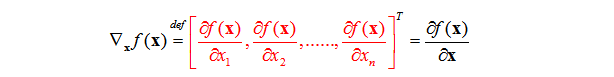
从定义可以看出来
(1)一个以向量为变量的标量函数的梯度也是一个向量。
(2)梯度的每个分量给出了标量函数在该分量方向上面的变化率。
Ⅱ.理论理解梯度下降法
假设我们有一个函数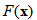
首先,给定一个初试猜测值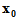
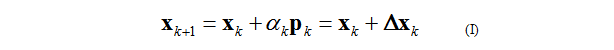
或者
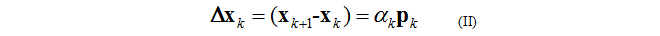
逐步修改我们的猜测.
其中:
是一个向量,代表一个搜索方向.
大于零的标量α表示学习速度(确定学习步长)
当使用上面的Ⅰ式进行最优点迭代的时候,函数应该在每次迭代后都减小.
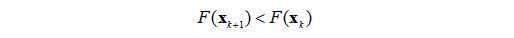
在知道了学习速度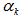
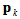
首先把函数一阶泰勒展开.
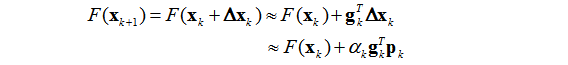
其中
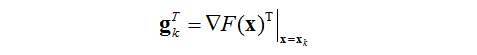
为在旧猜测值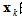
又必须使得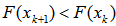
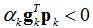
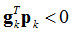
满足上式的任意一个向量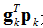
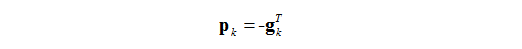
然后就可以代到上面的(I)式,得到
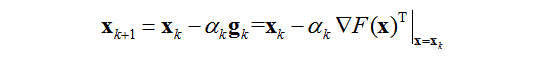
这个就是最速下降法的表达式了.
Ⅲ.形象的例子
理论上面弄了那么久,很抽象很容易晕。那么看几个形象例子来加强一下理解。
首先考虑一个变量的情况。
假如你现在有一个凸目标函数J(x)如下图,你想要求它的最小值。
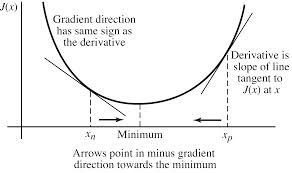
假如你是在左边那个点上面(画出了切线和函数相交的那个点),你要往最小值的那个地方跑,你肯定不能够往上面跑对吧。要是你高中学过物理的话,你就会知道,你必须完全把速度用到切线的方向上面你才能够最快的到最小值。为什么呢?因为要是你的速度在其他的方向,最后算是你往下的速度只是你一开始速度的一个分量。那么肯定就没有那么大的速度往最小值走了对吧。
我们又知道,在一个点的切线方向就是导数的方向。你从上面的图来看的话,在最小值点处的导数是0,然后最小值左边的导数都小于0,最小值右边的导数都大于0.(这里别问我为什么)。
对于左边那个点的横坐标,是应该加上该点导数的值还是应该减去该点导数的值才能够往最小值的横坐标移动呢?如果x值要往右边移动,需要加上一个正的数,又因为这里的导数是小于0的,那么就需要减去导数值。最终对于左边这个点来说是要减去导数的值才能够向最小值移动。
对于右边那个点,想去最小值那么x需要往左边移动,因为该点的导数是大于0的,那么往左边移动需要减去导数的值。那么还是需要减去导数的值。
那么再举两个变量的情况
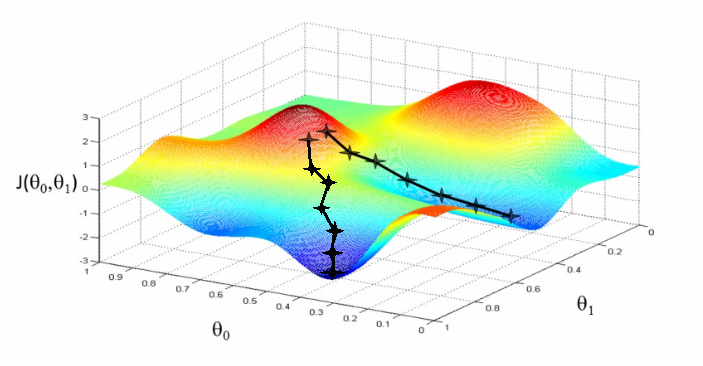
参考之前对于梯度的定义,一个梯度本质上面是一个向量,向量意味着自带方向。梯度的方向你可以理解为在该点变化最快的方向。形象一点来说,你想快点下山的话,是走那种缓慢的盘山公路还是走最剧烈的地方?假如你有10000条命…..
有了形象的思维,就很容易推广到多个变量巴拉巴拉上面去了。无非是求出梯度,然后用带点的坐标加上负梯度就行了。
三.梯度下降和随机梯度下降
前面已经说过了梯度下降的形式。我们需要的一个待优化的函数,能够求出他的梯度,然后按照他的方式去更新就行了。
为了方便理解,这里就用上节的线性回归为例子,上节的线性回归更多的是数学推导。这节用讲非常重要的用梯度下降的方法来“学习”到上节的参数w和b。而不是通过推导出未知参数的方式来得到。
上节的例子已经讲过背景了。
这里重新设置一般的线性方程为:
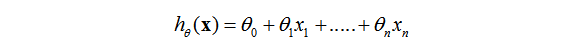
这里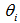
令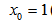
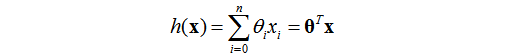
还记得上节定义的怎么找到最合适的参数的那个“评估函数”吗?我们把它写为这个样子:
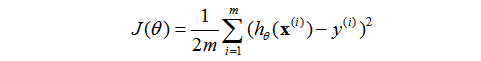
本质和之前的那个是一模一样的,只是系数和一些符号变了而已。这里的m表示的样本的数量,m个样本(m个输入向量)。加了一个系数2是为了接下来的求偏导消掉,这样更加简洁。至于加了一个2有影响吗?肯定是没有的。
我们把这个函数叫做损失函数(loss function),还有的地方叫做其他的函数目标函数什么的,都是一个意思。我们的目标就是是这个函数最小化,达到最优,即
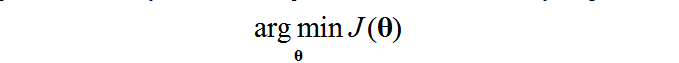
有根据梯度下降的思想,求最小值有
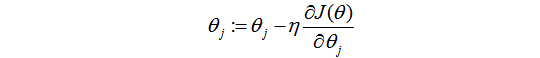
那么我需要把每个参数的偏导求出来,那么带进去迭代就能够得到最终的未知参数值了,这里直接推导:
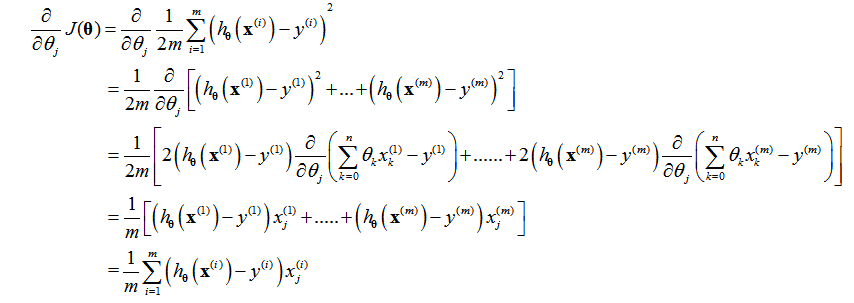
这里就求出了未知参数上面的偏导,是不是非常的简洁?从公式里面看出,如果我们自定义的参数模型和y的差别很小,那么这次“学习”迭代可以改进的范围就很小。要是差别很大,那么改进的范围也会变大。这是很符合人的逻辑思维的。
那么这个问题最终的梯度下降形式如下:
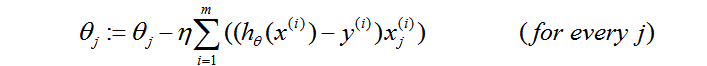
那么到底梯度下降和随机梯度下降有什么区别呢?
区别就在最后那一步对于样本的选择。
Ⅰ.梯度下降
原始的梯度下降就是把上面得到的不加修改的拿过来。算法可以写成这个样子。
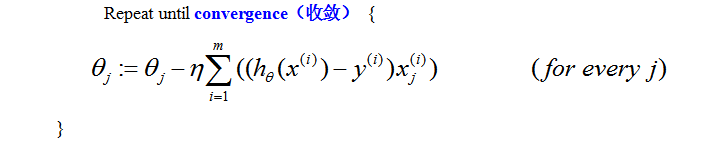
也就是说,这个算法一次性把所有的样本都拿过来进行梯度下降的迭代了。
举例子能够更加形象一点看清楚每个细节。还是上节那个奥运会的数据,直接拿过来。

我把100m时间作为y,年份作为x.虽然这里x只有一个维度,但是还是会按照很扩展的方式写代码。方便高维的推广。
代码:
Ⅱ.随机梯度下降法
原始的梯度下降法有一个缺点,那就是需要把所有的样本全部都加起来,一次性修改梯度。好处就是简单粗暴,直观容易理解。
但是假如要训练的样本很多很多呢?当样本非常非常大量的时候,这样是很耗内存的。肯定不是一个非常好的方法。
所以,我们想到了从样本中随机选择一小部分样本用同样的方式来估计得到剃度值,这里我们假设损失函数为C,样本为X,下面的这个式子就用来估计梯度。
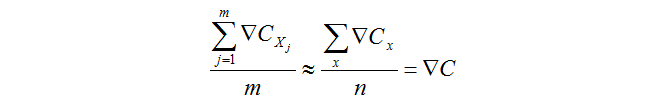
这个公式的意思就是,我们从样本中随机选择m个样本,然后他的梯度的平均值约等于所有样本算出来的梯度的平均值,就用这个式子来计算梯度。那么随机梯度下降可以写为下面的形式:
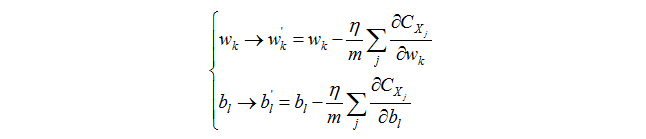
假设一个数据集有N个样本,我们首先随机选择其中的m1个样本训练,然后从其其余的样本中随机选择m2个样本训练,直到最后剩下m个样本选完(N=m1+m2+….+m)。这样一个过程成为一个epoch(我不知道怎么翻译)。然后在进行下一轮epoch,一直到训练完成。
这就是随机梯度下降的思想啦。














 864
864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









