






在这篇文章中,我们将一起探索如何利用Python的sklearn库来训练和使用一个简单的判别式AI模型。无论你是机器学习的初学者还是希望深入了解sklearn的开发者,这篇文章都将为你提供有价值的信息和实用的示例。
我们将从基础的模型训练开始,逐步学习如何使用训练好的模型进行预测。此外,我还会分享一些模型调优的技巧和如何收集反馈(classification_report)以改进模型质量的方法。
希望通过这篇博客,您能对判别式AI模型有一个全面的理解,并能够在实际项目中灵活运用这些知识。
#概念
生成式AI和判别式AI是机器学习领域中两种不同类型的模型,它们在工作原理、应用场景以及训练方法上存在显著差异。以下是对这两种AI的详细比较:
生成式AI
- 工作原理:生成式AI通过学习数据分布来生成新的样本。它试图捕捉数据的潜在结构,从而能够创建与训练数据相似的新实例。例如,生成对抗网络(GANs)和变分自编码器(VAEs)都是典型的生成式模型。
- 应用场景:生成式AI广泛应用于图像生成、文本创作、音乐和艺术创作等领域。它能够根据给定的条件或随机噪声生成全新的内容。
- 训练方法:生成式AI通常使用无监督学习方法进行训练,因为它不需要标签数据。相反,它依赖于最大化似然估计或最小化某种损失函数来优化模型参数。
判别式AI
- 工作原理:判别式AI通过学习输入数据与标签之间的映射关系来进行分类或回归任务。它直接预测给定输入的输出标签或值。例如,支持向量机(SVM)、逻辑回归和神经网络都属于判别式模型。
- 应用场景:判别式AI广泛应用于分类、回归和异常检测等任务。它在需要明确输出标签的场景中表现尤为出色,如图像识别、语音识别和自然语言处理等。
- 训练方法:判别式AI通常使用有监督学习方法进行训练,因为它需要大量的带标签数据来学习输入与输出之间的关系。常用的训练算法包括梯度下降、反向传播等。
相同点
- 目标一致:无论是生成式AI还是判别式AI,它们的最终目标都是从数据中学习并做出准确的预测或生成。
- 依赖数据:两者都需要大量的数据来进行训练,无论是原始数据还是经过预处理的数据。
- 数学基础:两者都基于统计学和概率论,使用各种数学工具和方法来优化模型性能。
总的来说,生成式AI和判别式AI在机器学习领域扮演着不同的角色,各有其独特的优势和应用场景。理解它们的差异和相同点有助于我们更好地选择合适的模型来解决实际问题。
简而言之,生成式AI是创造出新的文本、图像等,如讯飞星火、文心一言等;而判别式AI是对已有的数据进行筛选、分类或者判断,如人脸识别、光学识别等。
一、模型训练
# 安装所需库
使用pip安装所需库:
pip install scikit-learn pandas jieba1.数据集准备
首先是准备一个足够多的数据集,可以使用生成式AI来生成一些您想要的数据并填充到数据集里(当然还需要一定的人工筛选与调整,才能训练出一个高质量的模型)
如果没有生成式AI,可以看这篇:python调用ollama库详解_ollama python-CSDN博客。
如果硬件能力不够,网上有很多好用的生成式AI,随便找一个就能用了。
如果还是找不到,那就去:讯飞星火大模型-AI大语言模型-星火大模型-科大讯飞 (xfyun.cn)、豆包 - 字节跳动旗下 AI 智能助手 (doubao.com)、
Kimi.ai - 会推理解析,能深度思考的AI助手 (moonshot.cn)、
通义tongyi.ai_你的全能AI助手-通义千问 (aliyun.com)等等。
如果还是不会,那先看下去再说吧!
数据集:

导入数据集:
# 导入数据集到data列表
import pandas
df = pandas.read_excel("train_data_1600x.xlsx") # 改为你的数据集路径
data = []
'''
由于我的xls结构是类型放第一行,数据对应放在每个类型的下面,类似这样:
____________________________________________________________
| xx类型 | xx类型 | xx类型 | ...
|-----------------|------------------|----------------| ...
| xx类型对应的数据 | xx类型对应的数据 | xx类型对应的数据 | ...
|-----------------|------------------|----------------| ...
| ... | ... | ... | ...
所以使用以下的加载方法,如果你的数据集结构不同,请自行更改算法!
'''
# 遍历每一行,将题目和类别添加到结果列表中(加载算法)
for index, row in df.iterrows():
for col in df.columns:
if not pandas.isnull(row[col]):
data.append((row[col], col))
else:
break
#数据集太长了打印出来有些困难,可以使用print(data[:100]打印前100条数据预览)
#print(data)2.分词
直接给出代码:
import jieba
# 分词函数
def tokenize(text):
return ' '.join(jieba.cut(text))
# 准备数据集
texts, labels = zip(*data)
texts = [tokenize(text) for text in texts]3.开始训练
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.externals import joblib # 如果报错就改为直接import joblib
# 特征提取
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(texts)
y = labels
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
print("开始训练模型")
model = MultinomialNB()
model.fit(X_train, y_train)
# 保存模型到文件
joblib.dump(model,'saved_model/model.pkl')4.模型评估
from sklearn.metrics import classification_report, accuracy_score
from sklearn.externals import joblib
# 加载模型
model = joblib.load('saved_model/model.pkl')
# 评估模型
print("模型评估:")
y_pred = model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
print("Classification Report:\n", classification_report(y_test, y_pred))可以看到,模型评估时会输出类似以下内容:
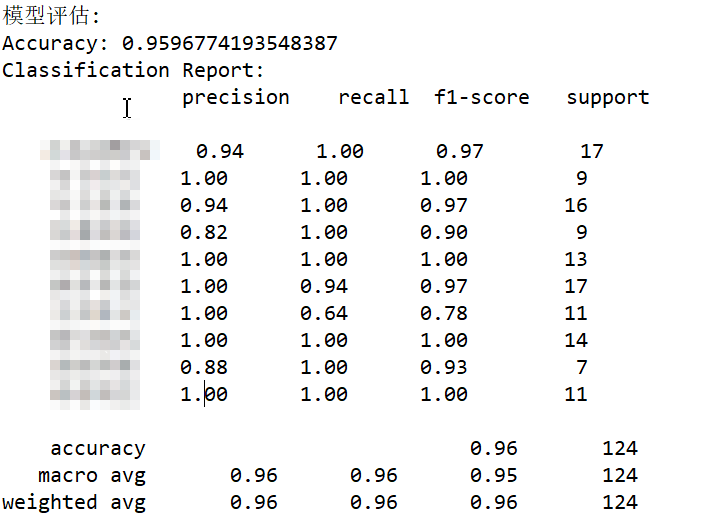
首先,Accuracy(准确率)是指模型正确预测的样本数占总样本数的比例,它是评估分类模型性能的一个基本指标。
在机器学习和数据科学中,准确率是一个广泛使用的指标,用于衡量模型在给定数据集上的整体表现。准确率的计算非常简单,即用模型正确预测的数量除以总的样本数量。然而,尽管准确率易于理解和计算,但它并不总是最佳的评估指标,特别是在处理类别不平衡的数据集时。在这类情况下,即使模型将所有样本都预测为多数类,也可能获得很高的准确率,但这显然不是我们想要的结果。
Classification Report是用于展示分类模型性能的一种详细报告,它包括了精确度(Precision)、召回率(Recall)、F1值(f1-score)和support等关键指标。
| precision | 精度是指模型预测为正样本的实例中,真正为正样本的比例 |
| recall | 召回率是指所有真正的正样本中,被模型预测为正样本的比例 |
| f1-score | F1值是精度和召回率的调和平均数,用于综合评估模型的性能 |
| support | 当前行的类别在测试数据中的样本总量 |
| accuracy | 正确预测的样本数占总样本数的比例 |
| macro average | 宏平均值,所有标签结果的平均值 |
| weighted avg | 加权平均值,所有标签结果的加权平均值 |
Classification Report在机器学习中扮演着重要的角色,特别是在评估分类模型的性能时。它不仅提供了每个类别的详细性能指标,还能给出整体的平均性能,帮助研究者和开发者更好地理解模型在不同方面的表现。通过这种方式,可以更准确地判断模型是否满足实际应用的需求,或者需要进一步的调整和优化。
二、模型使用
非常简单,代码如下:
from sklearn.externals import joblib
model = joblib.load('saved_model/model.pkl')
# 实际使用函数
# 这里需要使用到1.2中的tokenize函数和1.3中的vectorizer函数
def classify_question(question):
question_tokenized = tokenize(question)
question_vectorized = vectorizer.transform([question_tokenized])
prediction = model.predict(question_vectorized)
return prediction[0]
# 测试实际使用函数
new_question = "输入您的问题"
predicted_type = classify_question(new_question)
print(f"The predicted type of the question '{new_question}' is: {predicted_type}")至此,一个简单的基于sklearn的判别式AI模型就完成了!
如果需要深入了解并使用的,可以去找一些更加高深的文章,这里就不再赘述了……
End
制作不易,感谢大家的关注与支持!

















 1774
1774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









