







节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学.
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
我们已经进入了一个大规模使用大型语言模型(LLM)的年代。无论是简单的搜索引擎还是功能广泛的聊天机器人,LLM都在满足各类业务需求方面发挥了重要作用。
企业经常需要的一种工具是问答(QA)机器人。这是一种由AI驱动的工具,能够快速回答用户输入的问题。
在本文中,我们将开发一种结合RAG和文本转语音(TTS)功能的QA-LLM机器人。
我们该如何实现呢?让我们一探究竟。
项目结构
在这个项目中,我们将遵循以下结构。

项目将遵循以下步骤:
- 使用 Docker 部署开源的 Weaviate 向量数据库。
- 阅读《保险手册》PDF 文件,并使用 HuggingFace 公共托管的嵌入模型对数据进行嵌入。
- 将嵌入存储到 Weaviate 向量存储(知识库)中。
- 使用 HuggingFace 公共托管的嵌入模型和生成模型开发 RAG 系统。
- 使用 ElevenLabs 的文本转语音模型将 RAG 输出转换为音频。
- 使用 Streamlit 创建前端。
总体来说,我们将遵循这 6 个步骤来创建带有 RAG 和 TTS 的问答工具。
现在开始吧。
准备工作
在开始之前,我们需要准备一些包含所有需求的 Python 文件,以确保我们的应用程序能够正常运行。
首先,我们需要 HuggingFace API 访问令牌,因为我们将使用托管在那里的模型。如果你已经在 HuggingFace 注册,可以在令牌页面获取它们。
此外,我们将使用 ElevenLabs 的文本转语音模型。因此,请注册他们的免费帐户并获取 API 密钥。
拿到这两个 API 密钥后,你需要创建一个 .env 文件来存储这些密钥。将以下代码填入该文件:
ELEVENLABS_API_KEY= 'Your-ElevenLabs-API'
HUGGINGFACEHUB_API_TOKEN = 'Your-HuggingFace-API'
接下来,我们将通过安装所有必要的包来设置环境:
pip install langchain langchain-community langchain-core weaviate-client elevenlabs streamlit python-dotenv huggingface_hub sentence-transformers
准备工作完成后,让我们开始创建应用程序。
部署 Weaviate 向量数据库
对于本教程,你需要安装 Docker Desktop。如果还没有安装,可以在 Docker 网站上下载安装程序。
为了轻松部署 Weaviate 向量数据库,我们将遵循 Weaviate 的设置建议。在部署过程中,我们将使用 docker-compose 进行部署,你可以在下面的代码中看到:
version: '3.4'
services:
weaviate:
command:
- --host
- 0.0.0.0
- --port
- '8081'
- --scheme
- http
image: cr.weaviate.io/semitechnologies/weaviate:1.24.10
ports:
- 8081:8081
- 50051:50051
volumes:
- weaviate_data:/var/lib/weaviate
restart: on-failure:0
environment:
QUERY_DEFAULTS_LIMIT: 25
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
DEFAULT_VECTORIZER_MODULE: 'none'
ENABLE_MODULES: 'text2vec-cohere,text2vec-huggingface,text2vec-palm,text2vec-openai,generative-openai,generative-cohere,generative-palm,ref2vec-centroid,reranker-cohere,qna-openai'
CLUSTER_HOSTNAME: 'node1'
volumes:
weaviate_data:
在你选择的环境中,创建一个名为 docker-compose.yml 的文件,并复制上述代码。上述代码将从 Weaviate 拉取镜像,并包含所有相关模块。这段代码还将通过 PERSISTENCE_DATA_PATH 提供数据持久化。Weaviate 向量存储也会暴露在端口 8081。
一切准备就绪后,在终端中运行以下代码:
docker-compose up

在 Docker Desktop 中,你应该会看到类似上面的容器。这样,我们已经设置好了开源向量数据库。
构建保险手册知识库
项目的下一部分是使用 LangChain、HuggingFace 和 Weaviate 构建知识库。此部分的目标是构建一个向量数据库,该数据库包含来自《保险手册》的嵌入结果,可以从应用程序中访问。
首先,我们将设置 Weaviate 客户端和嵌入模型。可以使用以下代码进行设置:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Weaviate
import weaviate
client = weaviate.Client(
url="http://localhost:8081",
)
model_name = "sentence-transformers/all-mpnet-base-v2"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': False}
hf = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
在上面的代码中,我们通过连接到 localhost:8081 来设置 Weaviate 客户端,并使用简单的 mpnet 句子转换模型设置 HuggingFace 嵌入模型。
接下来,我们将使用 LangChain 读取《保险手册》PDF 并将文本数据分割成一定的块。
loader = PyPDFLoader("Insurance_Handbook_20103.pdf")
pages = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=50,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.split_documents(pages)
full_texts = [i.page_content for i in texts]
分割文本数据非常重要,因为它有助于处理模型的文本大小限制,并确保每个文本段都是有意义且上下文完整的。如果觉得结果不好,可以尝试调整 chunk_size 和 chunk_overlap 参数。
最后,我们将嵌入的文本数据存储在 Weaviate 向量数据库中,使用以下代码:
vector_db = Weaviate.from_texts(
full_texts, hf, client=client, by_text=False,
index_name='BookOfInsurance', text_key='intro'
)
这样,我们已经构建好了知识库。如果你想测试数据库,可以使用以下代码进行相似性搜索:
print(vector_db.similarity_search("What is expense ratio?", k=3))
最后,记得关闭 Weaviate 客户端:
client.close()
开发基于 RAG 和文本转语音 (TTS) 的 QA-LLM 工具
在创建工具之前,我们需要设置一些实用文件。
实用文件设置
首先,我们将设置 LLM 生成模型与 LangChain 和 HuggingFace 的连接。写这篇文章时,连接过程中存在一个 bug,因此我们需要开发一个惰性连接以避免使用 HuggingFace 令牌登录。
我们会将以下代码保存到 utils 文件夹中的 hf_lazyclass.py 文件中:
from langchain_community.llms.huggingface_endpoint import HuggingFaceEndpoint
from langchain_core.pydantic_v1 import root_validator
from langchain_core.utils import get_from_dict_or_env
class LazyHuggingFaceEndpoint(HuggingFaceEndpoint):
"""LazyHuggingFaceEndpoint"""
@root_validator()
def validate_environment(cls, values):
"""Validate that package is installed; SKIP API token validation."""
try:
from huggingface_hub import AsyncInferenceClient, InferenceClient
except ImportError:
msg = (
"Could not import huggingface_hub python package. "
"Please install it with `pip install huggingface_hub`."
)
raise ImportError(msg) # noqa: B904
huggingfacehub_api_token = get_from_dict_or_env(
values, "huggingfacehub_api_token", "HUGGINGFACEHUB_API_TOKEN"
)
values["client"] = InferenceClient(
model=values["model"],
timeout=values["timeout"],
token=huggingfacehub_api_token,
**values["server_kwargs"],
)
values["async_client"] = AsyncInferenceClient(
model=values["model"],
timeout=values["timeout"],
token=huggingfacehub_api_token,
**values["server_kwargs"],
)
return values
接下来,我们将创建文本转语音类文件,命名为 tts_speech.py,内容如下:
import os
import uuid
from elevenlabs import VoiceSettings
from elevenlabs.client import ElevenLabs
ELEVENLABS_API_KEY = os.getenv("ELEVENLABS_API_KEY")
client = ElevenLabs(
api_key=ELEVENLABS_API_KEY,
)
def text_to_speech_file(text: str) -> str:
# Calling the text_to_speech conversion API with detailed parameters
response = client.text_to_speech.convert(
voice_id="pNInz6obpgDQGcFmaJgB", # Adam pre-made voice
optimize_streaming_latency="0",
output_format="mp3_22050_32",
text=text,
model_id="eleven_turbo_v2", # use the turbo model for low latency, for other languages use the `eleven_multilingual_v2`
voice_settings=VoiceSettings(
stability=0.0,
similarity_boost=1.0,
style=0.0,
use_speaker_boost=True,
),
)
save_file_path = f"{uuid.uuid4()}.mp3"
# Writing the audio to a file
with open(save_file_path, "wb") as f:
for chunk in response:
if chunk:
f.write(chunk)
print(f"{save_file_path}: A new audio file was saved successfully!")
return save_file_path
以上代码中,我们使用了预设的声音,你可以在 ElevenLabs 的 Voice Lab 中找到适合工具的声音。
开发工具
这一部分将结合所有内容,通过 Streamlit 前端展示 RAG 和 TTS 模型。
首先,设置生成模型和 Weaviate 向量数据库连接:
import streamlit as st
import weaviate
from langchain_community.vectorstores import Weaviate
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain.chains import RetrievalQA
from dotenv import load_dotenv
import os
from utils.hf_lazyclass import LazyHuggingFaceEndpoint
from utils.tts_speech import text_to_speech_file
load_dotenv()
hf_token = os.getenv("HUGGINGFACEHUB_API_TOKEN")
client = weaviate.Client(
url="http://localhost:8081",
)
repo_id = "mistralai/Mistral-7B-Instruct-v0.2"
llm = LazyHuggingFaceEndpoint(
repo_id=repo_id, max_new_tokens=128, temperature=0.5, huggingfacehub_api_token=hf_token
)
model_name = "sentence-transformers/all-mpnet-base-v2"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': False}
hf = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
以上代码中,我们初始化了 Weaviate 客户端、生成 LLM 模型和 HuggingFace 嵌入模型。在这个例子中,我使用 Mistral Instruct LLM 模型作为生成 LLM 模型。
接下来,使用以下代码设置 RAG 系统:
response = client.schema.get()
weaviate_vectorstore = Weaviate(client=client,
index_name=response['classes'][0]['class'],
text_key="intro", by_text=False, embedding=hf)
retriever = weaviate_vectorstore.as_retriever()
qa_chain = RetrievalQA.from_chain_type(
llm=llm, chain_type="stuff", retriever=retriever
)
最后,我们使用以下代码设置了 Streamlit 文件,使其能够接受文本输入并提供音频输出。
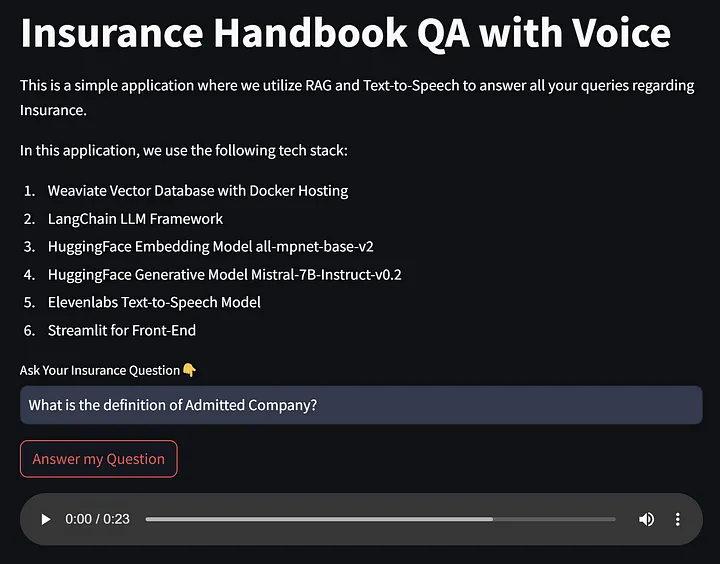
st.title('Insurance Handbook QA with Voice')
st.write("""
这是一个简单的应用程序,我们利用 RAG 和文本转语音来回答您关于保险的所有问题。
在这个应用程序中,我们使用以下技术栈:
1. Weaviate 向量数据库与 Docker 主机
2. LangChain LLM 框架
3. HuggingFace 嵌入模型 all-mpnet-base-v2
4. HuggingFace 生成模型 Mistral-7B-Instruct-v0.2
5. Elevenlabs 文本转语音模型
6. Streamlit 用于前端
""")
if 'prompt' not in st.session_state:
st.session_state.prompt = ''
if 'audiofile' not in st.session_state:
st.session_state.audiofile = ''
query = st.text_input("请输入您的保险问题👇", "")
if st.button("回答我的问题"):
st.session_state.prompt = query
response = qa_chain.invoke(query)
st.session_state.audiofile = text_to_speech_file(response['result'])
st.audio(st.session_state.audiofile, format="audio/mpeg", loop = False)
如果一切顺利,让我们运行这个 Streamlit 文件。您应该会看到页面和下面的图像类似。

好的,请把音频文件上传,我会帮你处理翻译。如果需要,我也可以提供文字翻译。请告诉我你的具体需求。
这就是全部。你可以调整模型、语音和前端页面,使其更加有趣。你还可以为你所需的领域构建自己的知识库。
结论
我们已经探索了如何使用RAG(检索增强生成)和文本转语音技术来构建我们的问答工具。通过结合开源工具和模型,我们可以构建一个企业所需要的高级工具。
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了算法岗技术与面试交流群, 想要获取最新面试题、了解最新面试动态的、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2040。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2040,备注:技术交流
用通俗易懂方式讲解系列
参考链接:https://pub.towardsai.net/crafting-qa-tool-with-reading-abilities-using-rag-and-text-to-speech-d4208330a1e4
















 671
671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









