






本文从应用角度出发,简单解释shap原理和shap图表具体如何分析,不涉及具体计算原理
0 引言
以前的机器学习模型就像个看不懂的“黑盒子”,我们只知道塞进去什么数据、出来什么结果,想知道哪个特征起了好作用还是坏作用,得靠猜或者做复杂的消融实验。

现在,像随机森林和 SVM 这些模型自带了一些“说明书”:
-
随机森林能告诉你,总的来看,哪些特征对所有预测平均来说最重要。
-
SVM(如果是简单直线型的)也能通过看“权重”大概知道哪些特征重要,是正面影响还是负面影响。但遇到复杂类型的 SVM,这招也不灵了。
这些模型自带说明书不够细致:它们只告诉你特征整体上重不重要,却说不清为什么模型对 这一次具体 的预测是如何判断的。而且,随机森林和 SVM 的“说明书”写法不一样,你没法直接比较它俩谁更依赖哪个特征。
SHAP 的好处就在于:
-
解释到点子上:它能清楚地告诉你,对于每一次具体的预测,每个特征到底是把它往“好的方向”推了多少,还是往“坏的方向”拉了多少。
-
标准统一,能比较:不管你用的是随机森林、SVM 还是其他模型,SHAP 都用同一套标准(基于公平分配贡献的 Shapley 值)来解释,这样你就能公平地比较不同模型是怎么看待同一个特征的了。
简单说,自带说明书只给了个大概的总评,而 SHAP 能给你每次考试的详细得分和原因分析,而且评卷标准对所有模型都一样。
1 Shap原理
Shap库意在解释对于预测结果而言,每个样本的特征是如何影响预测过程,预测特征是如何影响过程就需要一个统一的标准,这在shap里面叫做基准值(Base Value)。那么问题来了,如何得到基准值以及预测特征的影响?
首先,我们需要一个训练好的模型。SHAP 会基于一个背景数据集(通常是训练数据)计算出一个基准值 ,这代表了模型的平均预测输出。接着,对于我们想要解释的数据(比如测试集或单个样本),SHAP 会为每个样本的每个特征计算一个 SHAP 值。根据 SHAP 的理论,对于任何一个样本,基准值加上它所有特征的 SHAP 值之和,就等于模型对该样本的最终预测输出值。因此,通过查看每个特征的 SHAP 值,我们就能理解单个特征对具体某次预测的贡献方向和大小,我们用公式简单说明Shap值组成
Shap值 = 基准值 + 特征1(shap) + 特征2(shap) + 特征3(shap) + ............... + 特征n(shap)
我们用shap瀑布图直观感受下:
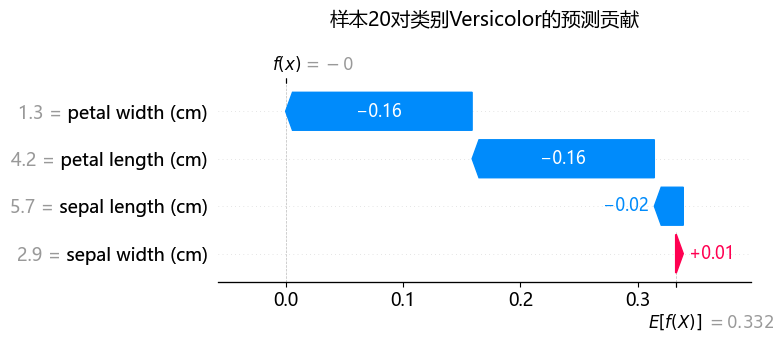
f(x):样本自身的shap值 E[f(x)]:shap基准值
图中蓝色和红色分别代表模型认为这四个特征是帮助其识别这个类别还是影响识别。必须说明一点,shap值仅仅起到解释特征对模型的影响程度而不能直接解释模型最终分类或回归结果。接下来进入Shap图表介绍。
2 Shap数据处理
Shap处理过程:
建立解释器——选择数据集计算Shap值并查看数据形状——根据绘图要求导入相关数据。
我们先看看Shap有哪些解释器
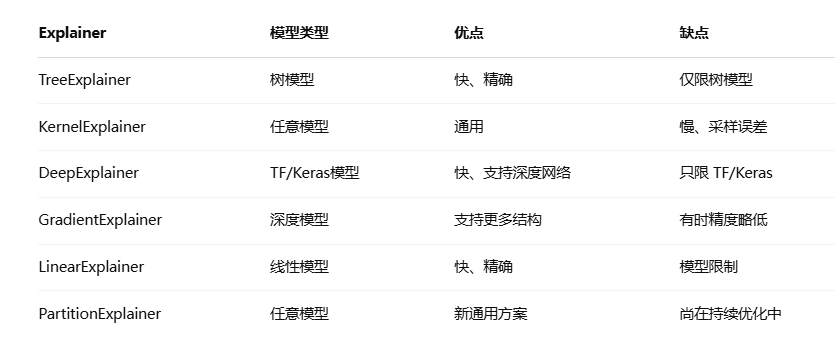
我用XGBoost来对iris数据集分类,以下是创建解释器和计算Shap值
#计算Shap值
import shap
# 导入适合树模型的 shap 解释器并初始化
explainer = shap.TreeExplainer(model)
# 计算所有训练数据的 shap 值
shap_values = explainer.shap_values(X_train)模型将iris分为三类,分别是0,1,2。我们查看下数据形式
print("shap_values shape:", shap_values.shape)#shap值的形状
print("shap_values[:, :, 0] shape:", shap_values[:, :, 0].shape)#(样本*特征)
print("X_train shape:", X_train.shape)#训练集的形状结果如下:
shap_values shape: (120, 4, 3) :(样本数,特征数,类别)
shap_values[:, :, 0] shape: (120, 4) :(类别0的shap值形状)
X_train shape: (120, 4) :(训练集形状)
分类问题shap值通常是三维形状(样本数,特征数,类别);回归问题shap值是二维形状(样本数,特征数)
3 Shap图表
3.0 导入库
#导入库
import xgboost as xgb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import pandas as pd
3.1 Shap决策图
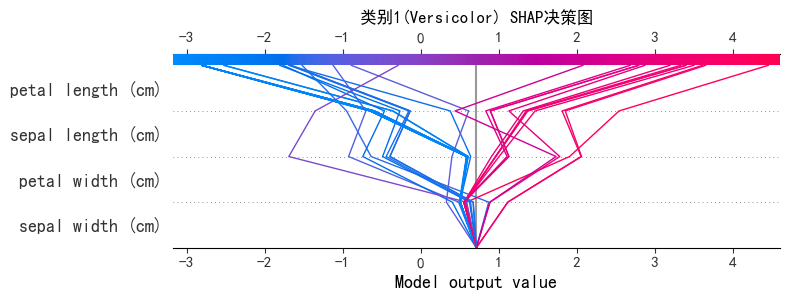
这个决策图是调用类别1的前40个样本(也就是全部样本)分析模型是如何决策的。
图片中的灰线是类别0的基准值,类别1每个样本的Shap值从基准值出发,在经过4个特征后发生变化,图片中的每一条线就代表一个样本的Shap值的变化过程。
1.看数据分布:大部分数据分类有规律,少部分异常值决策过程不同
2.看特征影响程度:Petal Length和Petal Width对类别1的分类影响大,线条转折都在这两个特征发生
详细代码:
# 定义类别映射
class_mapping = {
0: "Setosa",
1: "Versicolor",
2: "Virginica"
}
# 选择目标类别
class_id = 1 # 可以修改这个值来选择不同类别
class_name = class_mapping[class_id]
num_samples_to_plot = 40 # 要绘制的样本数量
feature_names = ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
# 绘制决策图
shap.decision_plot(
base_value=explainer.expected_value[class_idx], # 基准值
shap_values=shap_values[:num_samples_to_plot, :, class_idx], # NumPy 切片,前x个样本,所有特征,类别0
features=X_train[:num_samples_to_plot, :], # *** NumPy 切片,前x行,所有列 ***
feature_names=feature_names, # 特征名列表
title=f"类别{class_id}({class_name}) SHAP决策图",
show=False # 阻止自动显示
)
plt.tight_layout() # 调整布局
plt.show() # 显示图像
我们分析发现不同特征影响程度不同,这时候就可以用Shap条形图分析特征重要性
3.2 Shap条形图
我们打印类比1的条形图
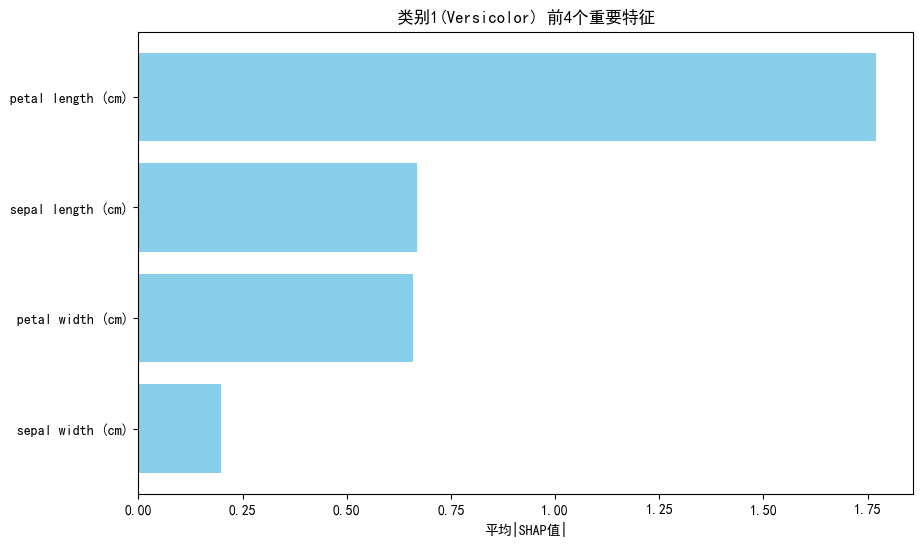
情况确实符合类别1的决策图情况,我们看看别的类别
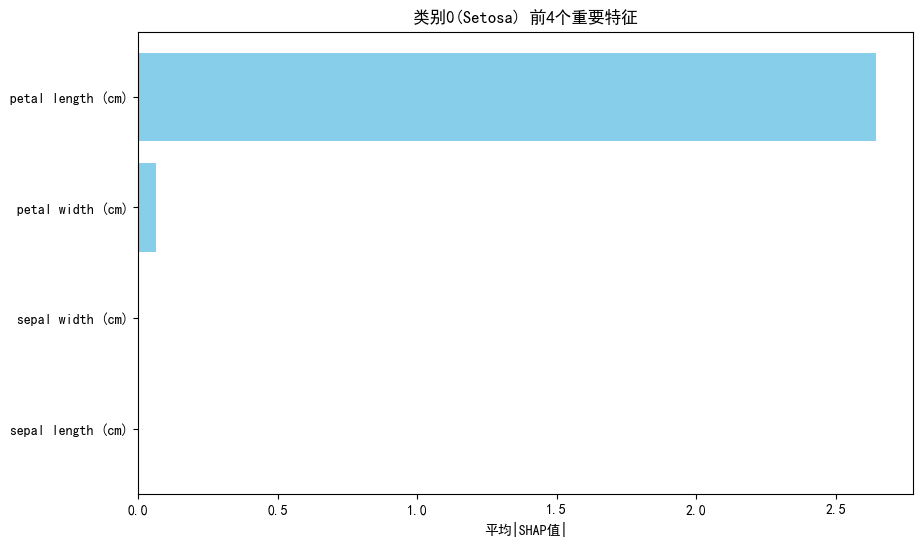
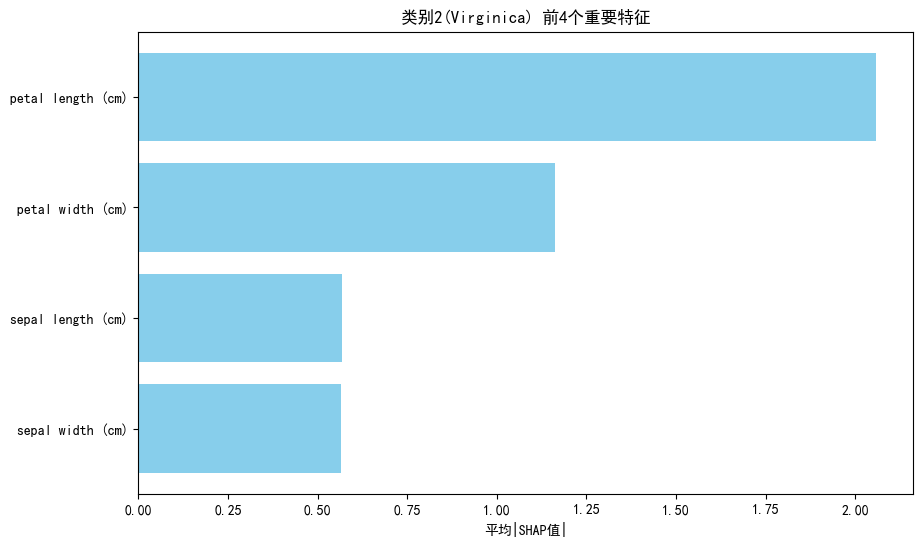
看了不同类别特征对模型识别贡献不同,我们看看整个分类过程中四个特征的重要性
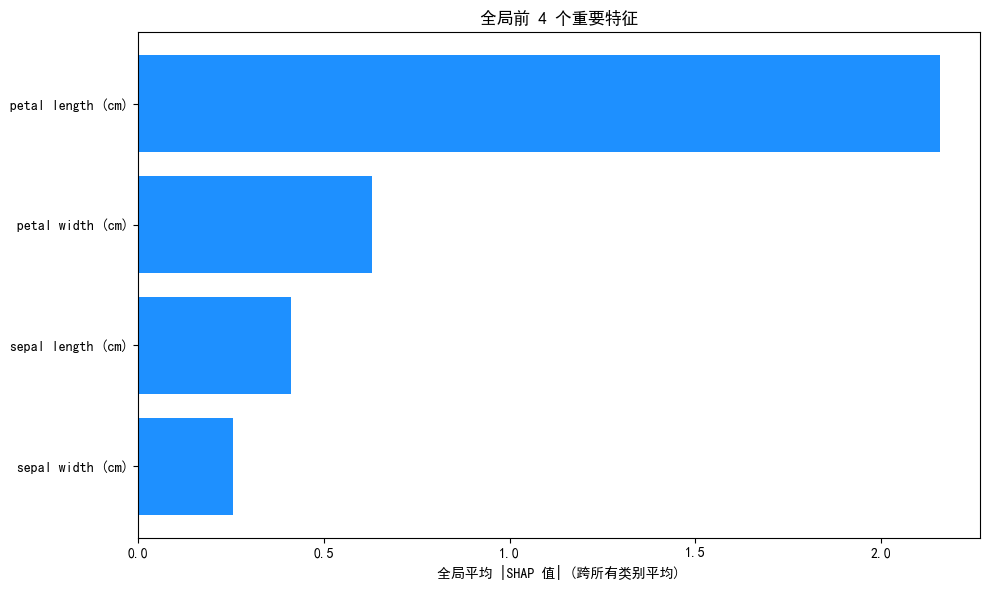
明显看出Petal Length是分类最重要的特征,但我们也不能被这个图蒙蔽,经过刚才查看三个类别各自特征的Shap值才发现原来其他三个特征其实也很重要,这也说明分类问题要查看每个类别单独的条形图
对应代码:
单个类别:
# 定义类别映射
class_mapping = {
0: "Setosa",
1: "Versicolor",
2: "Virginica"
}
# 选择目标类别
class_id = 1 # 可以修改这个值来选择不同类别
class_name = class_mapping[class_id]
feature_names = ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
# 计算指定类别的平均SHAP绝对值(特征重要性)
shap_values_class = shap_values[:, :, class_id]
mean_abs_shap = np.abs(shap_values_class).mean(axis=0)
# 创建特征重要性DataFrame并排序
importance_df = pd.DataFrame({
'feature': feature_names,
'importance': mean_abs_shap
}).sort_values('importance', ascending=False)
# 打印前10个最重要的特征(不足10个则显示全部)
top_n = min(10, len(importance_df))
print(f"类别{class_id}({class_name})的前{top_n}个重要特征排序:")
print(importance_df.head(top_n))
# 可视化前10个重要特征
plt.figure(figsize=(10, 6))
plt.barh(importance_df['feature'].head(top_n),
importance_df['importance'].head(top_n),
color='skyblue')
plt.xlabel('平均|SHAP值|')
plt.title(f'类别{class_id}({class_name}) 前{top_n}个重要特征')
plt.gca().invert_yaxis() # 重要性从高到低显示
plt.show()全局:
feature_names = ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
abs_shap_values = np.abs(shap_values)
# b. 对样本维度(axis=0)取平均,得到每个特征对每个类的平均影响
mean_abs_shap_per_class = abs_shap_values.mean(axis=0) # 形状: (num_features, num_classes)
# c. 对类别维度(axis=1)取平均,得到每个特征的全局平均影响
global_mean_abs_shap = mean_abs_shap_per_class.mean(axis=1) # 形状: (num_features,)
# --- 2. 创建特征重要性 DataFrame 并排序 ---
global_importance_df = pd.DataFrame({
'feature': feature_names,
'importance': global_mean_abs_shap # 使用全局平均绝对SHAP值
}).sort_values('importance', ascending=False) # 按重要性降序排列
# --- 3. 打印全局前 N 个重要特征 ---
top_n = min(10, len(global_importance_df)) # 最多显示10个,或所有特征(如果少于10个)
print(f"全局前 {top_n} 个重要特征排序 (基于跨类别平均绝对SHAP值):")
print(global_importance_df.head(top_n))
print("-" * 30) # 分隔线
# --- 4. 可视化全局前 N 个重要特征 ---
plt.figure(figsize=(10, 6))
plt.barh(
global_importance_df['feature'].head(top_n), # y轴: 特征名称
global_importance_df['importance'].head(top_n), # x轴: 重要性值
color='dodgerblue' # 使用不同颜色区分
)
plt.xlabel('全局平均 |SHAP 值| (跨所有类别平均)') # x轴标签
plt.title(f'全局前 {top_n} 个重要特征') # 图表标题
plt.gca().invert_yaxis() # 将最重要的特征显示在顶部
plt.tight_layout() # 调整布局防止标签重叠
plt.show()我们现在分析了特征的重要性,但是具体单个样本的特征是如何影响的呢?这时候我们可以用Shap的力图或者瀑布图来分析
3.3Shap力图和瀑布图
力图:

点开图片能看到有个灰色线对应基准值(base value),红色箭头代表该特征促进Shap增加且箭头长短直观表示该特征的促进大小。
代码:
# 定义类别映射
class_mapping = {
0: "Setosa",
1: "Versicolor",
2: "Virginica"
}
#选择样本
sample_idx = 20 # 选择第x个样本
# 选择目标类别
class_id = 1 # 可以修改这个值来选择不同类别
class_name = class_mapping[class_id]
# 绘制单个样本的SHAP力图
shap.force_plot(
base_value=explainer.expected_value[class_id], # 基准值
shap_values=shap_values[sample_idx, :, class_id], # 单个样本的SHAP值
features=X_train[sample_idx, :], # 单个样本的特征值
feature_names=feature_names, # 特征名列表
matplotlib=True, # 使用matplotlib渲染
show=False # 阻止自动显示
)
plt.title(f"类别{class_id}({class_name}) SHAP力图 - 样本{sample_idx}")
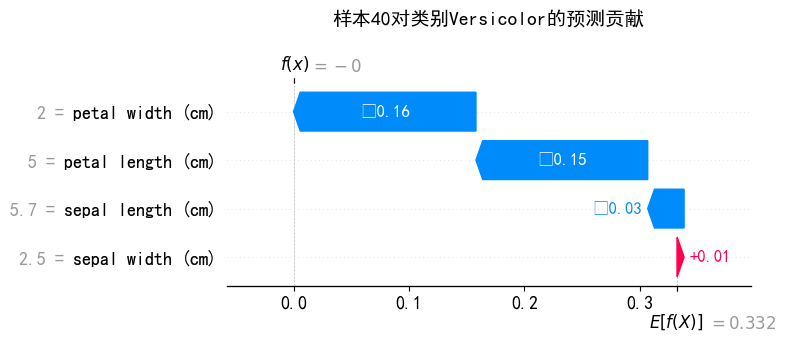
plt.tight_layout()瀑布图:
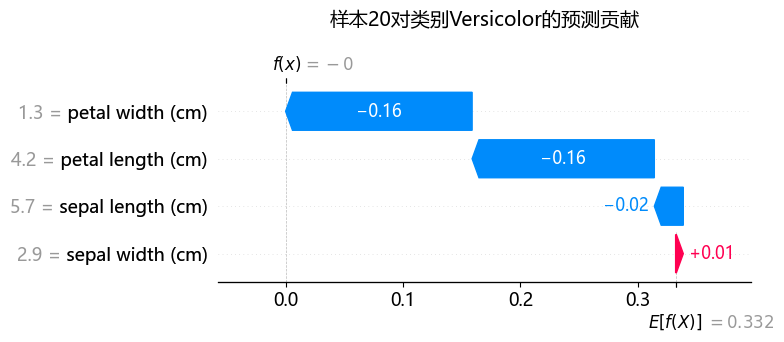
f(x):样本自身的shap值 E[f(x)]:shap基准值
瀑布图信息更密集,在力图的基础上展示基准值和样本Shap值,还说明每个特征自身的数据(左侧灰色数字)。
代码:
# 1. 准备数据
feature_names = ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
class_mapping = {0: "Setosa", 1: "Versicolor", 2: "Virginica"}
# 2. 选择目标类别和样本
class_id = 1 # 可以修改为0,1,2
sample_idx = 20 # 选择样本索引
# 设置 matplotlib 字体
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 使用微软雅黑字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 绘制瀑布图
plt.figure(figsize=(12, 8))
# 通过调整 `max_display` 来确保显示适当数量的特征
shap.plots.waterfall(
shap.Explanation(
values=shap_values[sample_idx, :, class_id],
base_values=explainer.expected_value[class_id],
data=X_train[sample_idx, :],
feature_names=feature_names
),
max_display=10, # 显示前5个特征,避免重叠
show=False
)
# 调整边距来避免重影
plt.subplots_adjust(left=0.25, right=0.85, top=0.85, bottom=0.15)
title_str = f'样本{sample_idx}对类别{class_mapping[class_id]}的预测贡献'
plt.title(title_str, fontsize=14, pad=20)
plt.tight_layout(pad=1.0) # 增加整体间距
plt.show()特别的bug:
代码中设置中午字体的时候,不要用黑体SimHei,会发生下图问题
“-”号无法显示以及有可能发生数据重叠,当初这个莫名其妙的问题也困扰我1个小时,后面换了好几个字体才解决。
3.4Shap依赖图
我们仔细观察了特征的重要性并看了几个样本Shap值的解释过程,但是我想分析特征与Shap值的交互作用以及特征之间的交互作用,这时候我们可以用依赖图来查看
特征与Shap值交互:
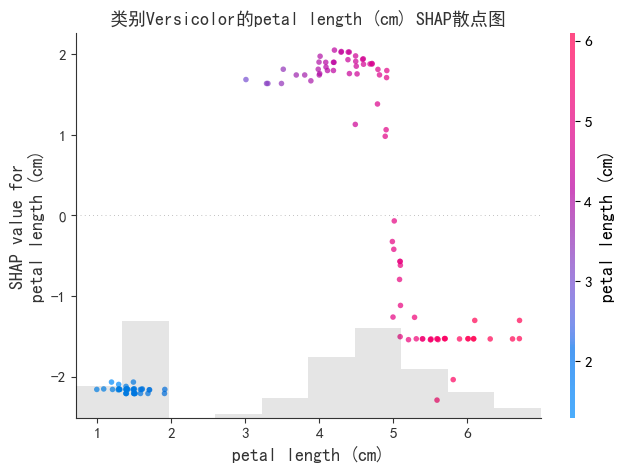
先观察散点图。左侧是Petal Length的Shap值。发现Petal Length大小与帮助模型分类类别Ver的关系是:负贡献-积极贡献-负贡献,图中灰色直方图代表数据分布形式。
代码:
# 定义类别映射
class_mapping = {
0: "Setosa",
1: "Versicolor",
2: "Virginica"
}
# 选择目标类别和特征
class_id = 1 # 可以修改为0,1,2
feature_name = "petal length (cm)" # 可以修改为其他特征名
# 获取特征索引
feature_idx = feature_names.index(feature_name)
# 创建Explanation对象
explanation = shap.Explanation(
values=shap_values[:, :, class_id],
data=X_train,
feature_names=feature_names
)
# 绘制SHAP散点图
shap.plots.scatter(
explanation[:, feature_name], # 使用Explanation对象和特征名
color=explanation[:, feature_name], # 用SHAP值着色
x_jitter=0.3, # 添加轻微抖动避免点重叠
alpha=0.7, # 设置透明度
title=f"类别{class_mapping[class_id]}的{feature_name} SHAP散点图"
)
plt.tight_layout()
plt.show()特征与特征交互:
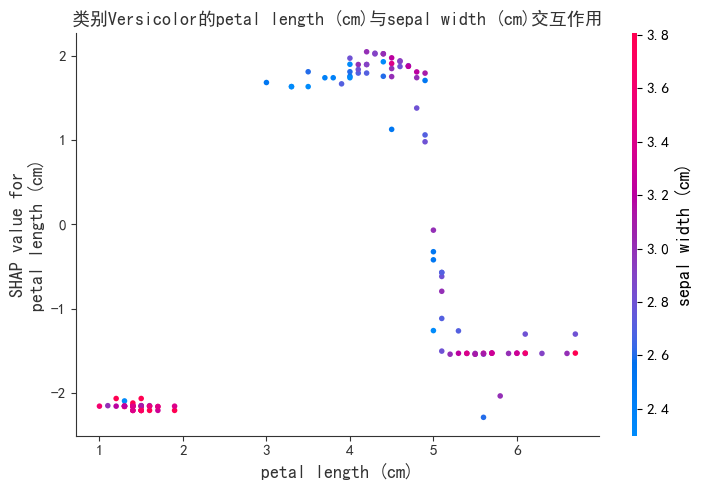
右图是Sepal Width的大小, 可以看出Petal Length与Sepal Width的交互作用。Sepal Width对Petal Length Shap值的影响与Petal Length十分相似,过大过小都会影响petal值。交互特征作用分析很复杂,需要多个单个特征依赖图和多特征依赖图组合分析,本文不做其他分析。
代码:
# 定义类别映射
class_mapping = {
0: "Setosa",
1: "Versicolor",
2: "Virginica"
}
# 选择目标类别和特征
class_id = 1 # 可以修改为0,1,2
feature_name1 = "petal width (cm)" # 主特征
feature_name2 = "sepal length (cm)" # 交互特征
# 获取特征索引
feature_idx1 = feature_names.index(feature_name1)
feature_idx2 = feature_names.index(feature_name2)
# 绘制带交互特征的依赖图
shap.dependence_plot(
feature_idx1,
shap_values[:, :, class_id], # 该类别的所有SHAP值
X_train,
feature_names=feature_names,
interaction_index=feature_idx2, # 显示交互特征
title=f"类别{class_mapping[class_id]}的{feature_name1}与{feature_name2}交互作用",
show=False
)
plt.tight_layout()
plt.show()3.5 Shap摘要图(散点图)
我们观察了特征的交互作用,现在看看所有特征大小是如何影响Shap值的
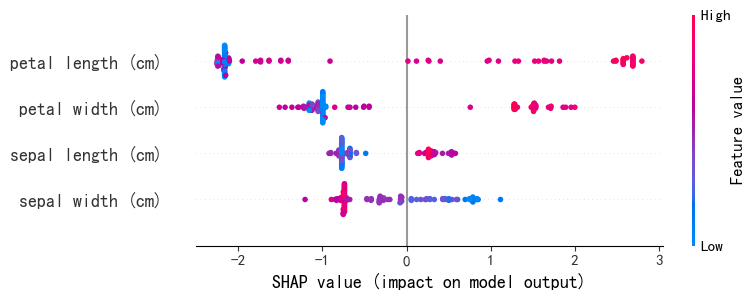
散点图的宽度代表数据分布多少,每一个点代表一个样本。为了美观我们可以转变为小提琴图
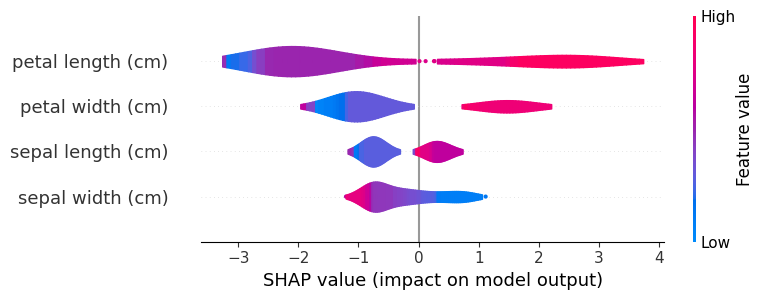
小提琴图确实美观不少但是数据分布准确度确实有一些缺失,看自己用法。
代码:
# 定义类别映射
class_mapping = {
0: "Setosa",
1: "Versicolor",
2: "Virginica"
}
# 选择目标类别
class_id = 2 # 可以修改为0,1,2
class_name = class_mapping[class_id]
# 绘制SHAP Summary Plot
shap.summary_plot(
shap_values[:, :, class_id], # 该类别的所有SHAP值
X_train,
feature_names=feature_names,
plot_type="violin", # 点图形式dot,小提琴violin
show=False,
title=f"类别{class_name}的SHAP特征重要性摘要"
)
plt.tight_layout()
plt.show()3.6 Shap热力图
Shap热力图看所有样本是如何分类或者回归的
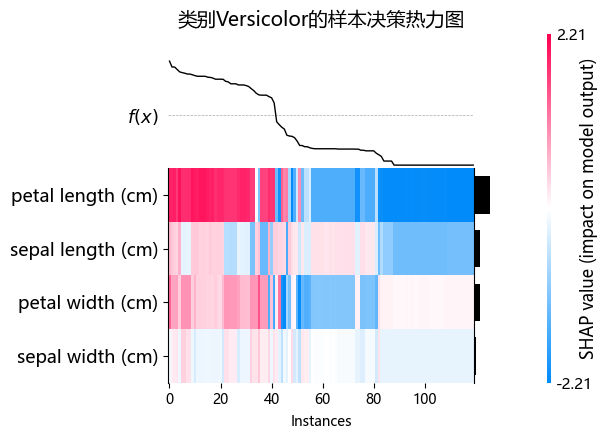
图片上方的灰色线是类别Ver的基准值,黑色线条由全部样本的Shap值组成。黑色线条和中间红色或蓝色的线条可以直观感受到特征是如何影响Shap值变化的,右边黑色柱状图代表对应特征的重要性。
虽然我选择了单个类别,但是热力图是调用计算Shap值的所有样本来分析每个样本是如何被分类的
代码:
# 设置 matplotlib 字体
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 使用微软雅黑字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 1. 准备数据
feature_names = ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
class_mapping = {0: "Setosa", 1: "Versicolor", 2: "Virginica"}
# 2. 选择目标类别
class_id = 1 # 可以修改为0,1,2
class_name = class_mapping[class_id]
# 3. 创建Explanation对象
explanation = shap.Explanation(
values=shap_values[:, :, class_id], # 仅包含目标类别的SHAP值
data=X_train,
feature_names=feature_names
)
# 4. 绘制热力图,解释的是120个样本中,每个样本是如何被理解成Versicolor的
plt.figure(figsize=(12, 8))
shap.plots.heatmap(
explanation,
max_display=10, # 最多显示10个特征
instance_order=np.argsort(-shap_values[:, :, class_id].sum(axis=1)), # 降序排列,若要升序则-shap.values改成shap_values
show=False
)
plt.title(f'类别{class_name}的样本决策热力图', fontsize=14)
plt.tight_layout()
plt.show()4.总结
本文介绍了Shap原理、各类图表以及图表在分类问题的简单应用,详细Shap分析与图表查看官网文档
需要特别强调的是:使用 SHAP 库时一定要关注 SHAP 值的形状。不同情境下,SHAP 值的形状可能不同,绘图时的数据输入格式也会有所变化。如果对 SHAP 的形状不了解,后续修改代码将变得非常困难。
@浙大疏锦行

















 1537
1537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









