






摘要
本文全面综述了基于视觉的机器人抓取技术。我们总结了基于视觉的机器人抓取过程中的三个关键任务,分别是物体定位、物体位姿估计和抓取估计。具体而言,物体定位任务包括无需分类的物体定位、物体检测和物体实例分割。该任务为输入数据中的目标物体提供了区域信息。物体位姿估计任务主要是指估计物体的6D位姿,包括基于对应的方法、基于模板的方法和基于投票的方法,这些方法为已知物体生成抓取位姿。抓取估计任务包括2D平面抓取方法和6自由度(6DoF)抓取方法,其中前者受限于从单一方向进行抓取。这三个任务可以通过不同的组合来完成机器人抓取。许多物体位姿估计方法无需物体定位,而是联合进行物体定位和物体位姿估计。许多抓取估计方法也无需物体定位和物体位姿估计,而是以端到端的方式进行抓取估计。本文详细回顾了基于RGB-D图像输入的传统方法和最新的深度学习方法。同时,本文还总结了相关数据集以及当前最先进方法之间的比较。此外,本文还指出了基于视觉的机器人抓取面临的挑战以及未来应对这些挑战的方向。
注释:


6D位姿是指6个自由度的位姿,包括3个自由度的位移(Translation)和3个自由度的空间旋转(Rotation)。位移表示物体在三维空间中的位置,而旋转则表示物体在三维空间中的朝向。合起来,这6个自由度就构成了物体的位姿(Pose)
抓取位姿是指机械臂(或机器人手爪)为了有效地抓取并操作该已知物体,所需达到的具体位置和姿态。具体来说,抓取位姿包含了以下几个关键要素:
- 抓取点:这是机械臂与物体接触的具体位置。为了确保机械臂能够有效地接触并抓取物体,抓取点通常通过物体的几何中心、重心或边缘检测算法来确定。对于复杂形状的物体,可能需要多点抓取,即确定多个抓取点以确保稳定的抓取。
- 抓取姿态:这描述了机械臂在抓取物体时的具体姿态,包括机械臂的末端执行器(如夹爪)相对于物体的方向、角度等。抓取姿态的选择应确保机械臂能够稳定地夹持住物体,并在移动过程中保持物体的稳定性。
1 引言
智能机器人需具备感知环境并与环境进行交互的能力。在这些基本能力中,抓取能力尤为基础和重要,因为它将为社会带来巨大的推动力。例如,工业机器人能够完成对人类劳动力而言繁重不堪的搬运任务,而家用机器人则能在日常抓取任务中为残疾人或老年人提供帮助。赋予机器人感知能力一直是计算机视觉和机器人学领域长期追求的目标。
尽管抓取能力意义重大,但关于机器人抓取的研究已由来已久。机器人抓取系统被认为由以下子系统组成:抓取检测系统、抓取规划系统和控制系统。其中,抓取检测系统是关键的切入点,如图1所示。抓取规划系统和控制系统与运动和自动化领域更为相关,而在本综述中,我们仅专注于抓取检测系统。
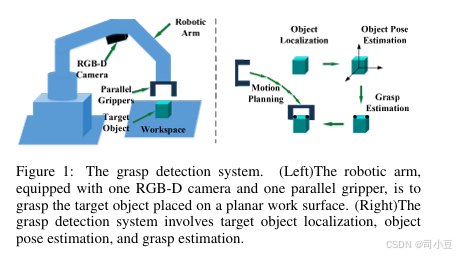
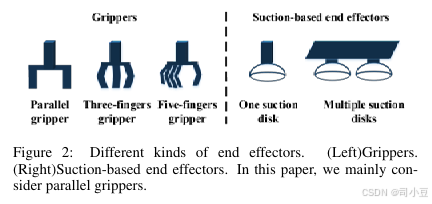
机械臂和末端执行器是抓取检测系统的重要组成部分。为了确保足够的灵活性,生产了各种具有5-7个自由度(DoF)的机械臂,并将它们安装在基座上或类人机器人上。如图2所示,不同种类的末端执行器,如夹爪和吸盘,可以完成物体抓取任务。大多数方法都关注于平行夹爪,这是一个相对简单的情况。随着学术界的不断努力,人们开始研究灵巧夹爪以完成复杂的抓取任务。在本文中,我们仅讨论夹爪,因为基于吸力的末端执行器相对简单且抓取复杂物体的能力有限。此外,我们重点关注使用平行夹爪的方法,因为这是研究最为广泛的方法。
抓取目标物体的关键信息是相机坐标系中的6D夹爪姿态,包括3D夹爪位置和3D夹爪方向,以执行抓取动作。6D夹爪姿态的估计因不同的抓取方式而异,可分为2D平面抓取和6DoF抓取。
解析:6DoF grasp,即6自由度抓取,是一种在三维空间中确定物体抓取位置和姿态的技术。这里的6自由度(6DoF)指的是物体在三维空间中的三个位置自由度(X、Y、Z坐标)和三个旋转自由度(绕X轴的旋转、绕Y轴的旋转、绕Z轴的旋转),共计六个自由度。这种抓取技术对于机器人来说至关重要,因为它允许机器人在复杂环境中准确地抓取和操作物体。
2D平面抓取意味着目标物体位于平面工作区内,且抓取动作从一个方向受限。在这种情况下,夹爪的高度是固定的,且夹爪方向与某一平面垂直。因此,关键信息从6D简化为3D,即2D平面位置和1D旋转角度。在早年深度信息不易捕获的时期,2D平面抓取是研究的主要方向。最常用的场景是在工厂中抓取机械部件。会评估抓取接触点是否能实现力封闭。随着深度学习的发展,大量方法将定向矩形作为抓取配置,这得益于成熟的2D检测框架。自此,2D平面抓取的能力得到了极大的扩展,抓取目标从已知物体扩展到新物体。提出了大量通过评估定向矩形来抓取物体的方法。此外,近年来还提出了一些基于深度学习的评估抓取接触点的方法。
6DoF抓取意味着夹爪可以在三维空间中的不同角度抓取物体,且关键的6D夹爪姿态无法简化。早年,人们使用分析方法来分析三维数据的几何结构,并根据力封闭原理找到适合抓取的点。
注释:力封闭(Force Closure)是指这样一种状态:如果一个物体因一组施加在物体表面的静态约束而不能发生任何位姿的改变,而这组静态约束完全由于机器人的手指施加在物体接触点处的力螺旋决定,那么就称这种状态为力封闭状态,同时称这组抓取为力封闭抓取。
Sahbani等人概述了三维物体抓取算法,其中大多数算法处理的是完整形状的物体。随着传感器设备(如Microsoft Kinect、Intel RealSense等)的发展,研究人员可以轻松获得目标物体的深度信息,现代抓取系统也配备了RGB-D传感器,如图3所示。利用相机内参,可以轻松将深度图像提升为三维点云,基于深度图像的6DoF抓取成为热门研究领域。在6DoF抓取方法中,大多数方法针对已知物体,这些物体的抓取动作可以预先计算,从而将问题转化为6D物体姿态估计问题。随着深度学习的发展,许多方法在处理新物体方面展现出了强大的能力。


无论是2D平面抓取还是6DoF抓取,都包含共同的任务:物体定位、物体姿态估计和抓取估计。
为了计算6D夹爪姿态,首先要定位目标物体。针对物体定位,存在三种不同情况:无分类的物体定位、物体检测和物体实例分割。无分类的物体定位意味着获取目标物体的区域,而不对其类别进行分类。在某些情况下,即使不知道物体的类别,也可以进行抓取。物体检测意味着检测目标物体的区域并对其类别进行分类。这有助于在多个候选物体中抓取特定物体。物体实例分割是指检测某一类别的像素级或点级实例物体。这为姿态估计和抓取估计提供了精细信息。早期方法假设要抓取的物体放置在背景简单且干净的环境中,从而简化了物体定位任务,而在相对复杂的环境中,它们的能力相当有限。传统的物体检测方法利用机器学习方法基于手工制作的二维描述符训练分类器。然而,由于手工描述符的限制,这些分类器的性能有限。随着深度学习的发展,二维检测和二维实例分割能力有了很大提高,这能够在更复杂的环境中进行物体检测。
目前的大多数机器人抓取方法都针对已知物体,估计物体姿态是成功抓取最准确且最简单的方法。存在各种计算6D物体姿态的方法,从二维输入到三维输入、从传统方法到深度学习方法、从有纹理物体到无纹理或遮挡物体。在本文中,我们将这些方法分为基于对应的方法、基于模板的方法和基于投票的方法,其中仅涉及特征点、整个输入和每个元单位来计算6D物体姿态。早期方法在三维域中通过执行部分配准来解决这个问题。随着深度学习的发展,仅使用RGB图像的方法可以提供相对精确的6D物体姿态,这大大提高了抓取能力。
在定位目标物体后,进行抓取估计。针对2D平面抓取,方法分为评估抓取接触点的方法和评估定向矩形的方法。针对6DoF抓取,方法分为基于部分点云的方法和基于完整形状的方法。基于部分点云的方法意味着我们没有目标物体的相同三维模型。在这种情况下,存在两种方法:评估候选抓取的抓取质量的方法和从现有抓取转移抓取的方法。基于完整形状的方法意味着在完整形状上进行抓取估计。当目标物体已知时,可以计算6D物体姿态。当目标形状未知时,可以从单视图点云重建它,并在重建的完整三维形状上进行抓取估计。随着上述方面的共同发展,可抓取的物体种类、抓取的鲁棒性以及可承受的抓取场景复杂性都有了很大提高,这为工业和家庭应用提供了更多应用机会。
针对上述任务,已有一些工作集中在一个或少数几个任务上,但仍缺乏对这些任务的全面介绍。本文对这些任务进行了详细回顾,并展示了这些任务的分类,如图4所示。据我们所知,这是首次广泛总结基于视觉的机器人抓取进展并预示新方向的综述。我们相信,这一贡献将为机器人学领域提供有见地的参考。
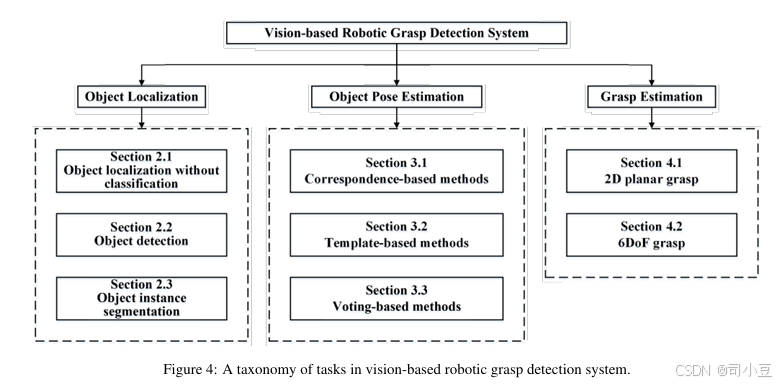
本文的其余部分安排如下。第2节回顾了物体定位的方法。第3节回顾了6D物体姿态估计的方法。第4节回顾了抓取估计的方法。每节还回顾了相关数据集、评估指标和比较。最后,第5节总结了挑战和未来方向。
2 目标物体定位
大多数机器人抓取方法首先需要在输入数据中确定目标物体的位置。这涉及到三种不同的情况:无分类的目标物体定位、目标检测和目标实例分割。无分类的目标物体定位仅输出目标物体可能存在的区域,而不需要知道它们的类别。目标检测则提供目标物体的边界框以及它们的类别。目标实例分割进一步提供了目标物体在像素级或点级上的区域,以及它们的类别。
2.1 无分类的目标物体定位
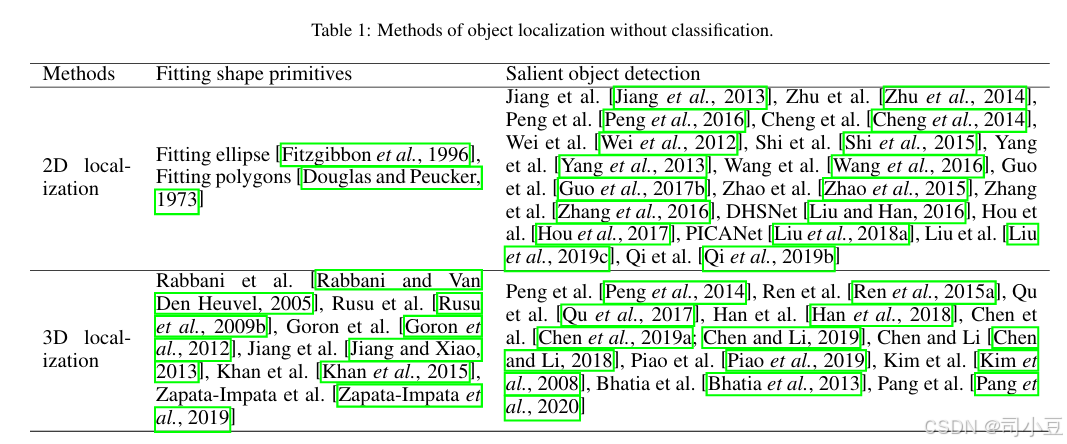
在这种情况下,任务是在不知道目标物体类别的情况下找到其可能的位置。存在两种情况:如果你知道目标物体的具体形状,你可以通过拟合基本形状(如矩形、圆形等)来获得其位置。如果你无法确定目标物体的形状,则可以进行显著物体检测(SOD)来找到目标物体的显著区域。基于二维或三维输入,这些方法在表1中进行了总结。
无分类的二维定位
这类方法处理的是二维图像输入,通常是RGB图像。根据目标物体的轮廓形状是否已知,方法可以分为拟合形状基元和显著物体检测两种方法。无分类的二维物体定位的典型功能流程图如图5所示。
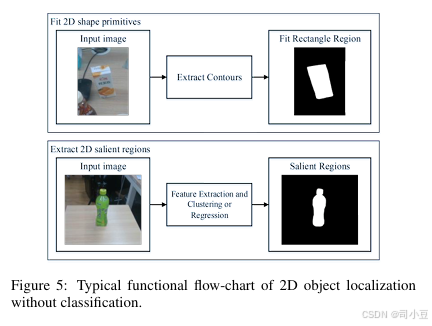
拟合二维形状基元
目标物体的形状可能是椭圆、多边形或矩形,这些形状可以视为形状基元。通过拟合方法,可以确定目标物体的位置。这类方法的一般程序通常包括封闭轮廓提取和基元拟合。OpenCV中集成了许多用于基元拟合的算法,如拟合椭圆和拟合多边形[Douglas和Peucker, 1973]。这类方法通常用于二维平面机器人抓取任务,其中物体从固定角度观察,且目标物体被某些已知形状所约束。
二维显著物体检测
与形状基元相比,显著物体区域可以以任意形状表示。二维显著物体检测(SOD)旨在定位并分割给定图像中最具视觉差异性的物体区域,这更像是一个没有物体分类的分割任务。非深度学习的SOD方法利用低级特征表示或依赖于某些启发式方法,如颜色对比、背景先验等。其他方法则进行过度分割过程,生成区域、超像素或物体候选框来辅助上述方法。自2015年以来,基于深度学习的SOD方法相较于传统解决方案表现出了优越的性能。一般来说,它们可以分为三类:基于多层感知器(MLP)的方法、基于全卷积网络(FCN)的方法和基于胶囊的方法。基于MLP的方法通常为每个图像处理单元提取深度特征,以训练MLP分类器进行显著性分数预测。Zhao等人提出了一个统一的多上下文深度学习框架,涉及全局上下文和局部上下文,这些上下文被输入到MLP中进行前景/背景分类,以模拟图像中物体的显著性。Zhang等人提出了一个显著物体检测系统,该系统为无约束图像输出紧凑的检测窗口,并使用基于最大后验(MAP)的子集优化公式来过滤边界框候选框。基于MLP的SOD方法不能很好地捕获关键空间信息,且耗时较长。受全卷积网络(FCN)的启发,许多方法直接输出整个显著性图。Liu和Han提出了一个称为DHSNet的端到端显著性检测模型,该模型可以同时细化粗略的显著性图。Hou等人[2017]在跳层结构中引入了短连接,这为每个层提供了丰富的多尺度特征图。Liu等人提出了一个称为PiCANet的像素级上下文注意网络,该网络为每个像素生成一个注意图,并且每个注意权重对应于每个上下文位置处的上下文相关性。随着胶囊网络(Capsule Network)的兴起,一些基于胶囊的方法被提出。Liu等人将显著物体检测中的部分-物体关系纳入其中,这是通过胶囊网络实现的。Qi等人提出了CapSalNet,它包括一个多尺度胶囊注意模块和多交叉层连接,用于显著物体检测。读者可以参考一些综述文章,以全面了解二维显著物体检测。
讨论:无需分类的二维物体定位在机器人抓取任务中得到了广泛应用,但尚处于初级阶段。在工业场景中,机械部件通常具有固定形状,其中许多部件可以通过拟合形状基元进行定位。在其他一些抓取场景中,会利用背景先验或颜色对比来获取用于抓取的显著物体。在Dexnet 2.0中,目标物体被放置在绿色的工作空间中,通过颜色背景减法可以很容易地将它们分割出来。
无需分类的三维定位
这类方法处理的是三维点云输入,这些点云通常是从机器人抓取任务中的单视图深度图像重建而来的部分点云。根据物体的三维形状是否已知,这些方法还可以分为拟合三维形状基元的方法和显著三维物体检测的方法。无需分类的三维物体定位的典型功能流程图如图6所示。
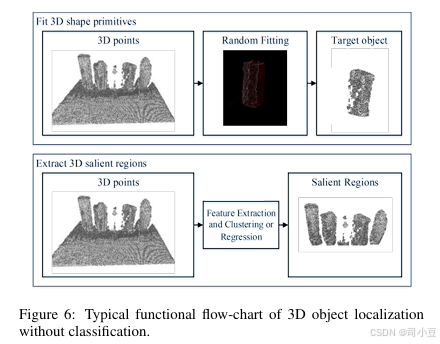
拟合3D形状基元
目标对象的形状可能是球体、圆柱体或立方体,这些形状可以被视为3D形状基元。存在许多旨在拟合3D形状基元的方法,如基于随机抽样一致算法(RANSAC)的方法、类霍夫投票方法和其他聚类技术。这些方法处理不同类型的输入,并已应用于建模、渲染和动画等领域。针对物体定位和机器人抓取任务,输入数据是部分点云,其中物体是不完整的,目的是找到能够构成3D形状基元之一的点。一些方法在物体边界检测平面并将它们组合起来。Jiang等人(Jiang and Xiao, 2013)和Khan等人探索了室内场景中的3D结构,并使用长方体估计其几何形状。Rabbani等人提出了一种高效的霍夫变换,用于在点云中自动检测圆柱体。一些方法在分割场景后进行基元拟合。Rusu等人结合了稳健的形状基元模型与三角网格,创建了适用于机器人抓取的混合形状-表面表示。Goron等人提出了一种方法,用于在杂乱场景中找到圆柱形和盒状物体的最佳参数。他们通过采用一组内点滤波器和霍夫投票来处理杂乱场景,提高了RANSAC拟合的稳健性。他们提供了稳健的结果和相关模型,这些对于抓取估计具有重要意义。读者可参考相关综述了解更多详细信息。
3D显著物体检测
与2D显著物体检测相比,3D显著物体检测消耗多种3D数据,如深度图像和点云。尽管上述2D显著物体检测方法已取得卓越性能,但在一些复杂场景中仍具有挑战性,其中深度信息可提供很大帮助。RGB-D显著性检测方法通常利用来自RGB-D图像的手工或基于深度学习的特征,并以不同方式进行融合。Peng等人(Peng et al., 2014)提出了一种简单的融合策略,通过结合深度诱导的显著性来扩展基于RGB的显著性模型。Ren等人(Ren et al., 2015a)利用归一化深度先验和全局上下文表面方向先验进行显著物体检测。Qu等人训练了一个基于卷积神经网络(CNN)的模型,该模型将不同的低级显著性线索融合为层次特征,用于检测RGB-D图像中的显著物体。Chen等人利用具有不同融合结构的双流CNN模型。Chen和Li进一步提出了一种渐进互补感知融合网络用于RGB-D显著物体检测,该方法比早期融合方法和后期融合方法更有效。Piao等人(Piao et al., 2019)提出了一种深度诱导的多尺度循环注意网络(DM RANet)用于显著性检测,该网络在复杂场景中尤其表现出色。Pang等人提出了一种分层动态滤波网络(HDFNet)和混合增强损失。Li等人提出了一种跨模态加权(CMW)策略,以促进RGB和深度通道之间的综合交互。这些方法展示了RGB-D显著物体检测(SOD)的卓越性能。针对3D点云输入,提出了许多方法来检测完整物体模型的显著性图,然而,我们的目标是从3D场景输入中定位显著物体。Kim等人描述了一种分割方法,该方法使用3D点云和RGB图像提取室外场景中的显著区域。Bhatia等人提出了一种自上而下的方法,用于提取室内场景3D点云中的显著物体/区域。他们首先分离出显著的平面区域,并从剩余点云中提取孤立的物体。然后,根据轮廓的较高曲率复杂性对每个物体进行显著性排序。
讨论
三维物体定位在机器人抓取任务中得到了广泛应用,但仍处于初级阶段。在Rusu等人(Rusu et al., 2009b)和Goron等人(Goron et al., 2012)的研究中,三维形状基元的拟合已成功应用于机器人抓取任务。在Zapata-Impata等人(Zapata-Impata et al., 2019)的研究中,首先利用高度约束过滤掉背景,然后通过随机抽样一致算法(RANSAC)(Fischler and Bolles, 1981)拟合平面来过滤掉桌子。剩余的点云被聚类,最终得到K个物体的点云。还存在其他一些方法,可以通过使用现有的完整三维点云拟合背景点来去除背景点。这些方法已成功应用于机器人抓取任务。
2.2 物体检测
物体检测的任务是检测某一类物体的实例,这可以看作是定位任务加上分类任务。通常,目标物体的形状是未知的,很难获得准确的显著区域。因此,常规边界框被用于一般的物体定位和分类任务,而物体检测的输出是具有类别标签的边界框。根据是否使用区域提议,这些方法可以分为两阶段方法和一阶段方法。这些方法分别针对二维或三维输入在表2中进行了总结。

二维物体检测
二维物体检测是指通过计算二维边界框和类别来检测二维图像中的目标物体。二维检测最常用的方法是生成物体提议并进行分类,即两阶段方法。随着深度学习网络,特别是卷积神经网络(CNN)的发展,两阶段方法得到了极大的改进。此外,还提出了大量的一阶段方法,这些方法以高速度实现了高精度。二维物体检测的典型功能流程图如图7所示。

两阶段方法
两阶段方法也可以称为基于区域提议的方法。大多数传统方法首先利用滑动窗口策略获取边界框,然后利用边界框的特征描述进行分类。已经提出了大量手工设计的全局描述子和局部描述子,如SIFT(Lowe, 1999)、FAST(Rosten and Drummond, 2005)、SURF(Bay et al., 2006)、ORB(Rublee et al., 2011)等。基于这些描述子,研究人员训练了分类器,如神经网络、支持向量机(SVM)或Adaboost,以进行二维检测。传统检测方法存在一些缺点。例如,滑动窗口需要针对特定对象进行预定义,且手工设计的特征对于强大的分类器来说代表性不够。随着深度学习的发展,可以使用深度神经网络计算区域提议。OverFeat(Sermanet et al., 2013)训练了一个全连接层来预测定位任务的边界框坐标,该任务假设单个对象。Erhan等人(Erhan et al., 2014)和Szegedy等人(Szegedy et al., 2014)从一个网络生成区域提议,该网络的最后一个全连接层同时预测多个边界框。此外,深度神经网络提取的特征比手工设计的特征更具代表性,使用卷积神经网络(CNN)(Krizhevsky et al., 2012)特征训练分类器极大地提高了性能。R-CNN(Girshick et al., 2014)使用选择性搜索(SS)(Uijlings et al., 2013)方法生成区域提议,使用CNN提取特征,并使用SVM训练分类器。在Fast R-CNN(Girshick, 2015)中,这一传统分类器被直接使用感兴趣区域(ROI)特征向量回归边界框所取代。Faster R-CNN(Ren et al., 2015b)进一步提出用区域提议网络(RPN)替代SS,RPN是一种全卷积网络(FCN)(Long et al., 2015),可以针对生成检测提议的任务进行端到端的专门训练。这种设计也被其他两阶段方法所采用,如R-FCN(Dai et al., 2016c)、FPN(Lin et al., 2017a)。一般来说,两阶段方法具有更高的准确性,但需要更多的计算资源或计算时间。
一阶段方法
一阶段方法也可以称为基于回归的方法。与两阶段方法相比,一阶段流程跳过了单独的对象提议生成,并在一次评估中预测边界框和类别分数。YOLO(Redmon et al., 2016)进行联合网格回归,同时预测多个边界框和这些边界框的类别概率。由于YOLO只为每个网格回归两个边界框,因此它不适合小对象。SSD(Liu et al., 2016)对由滑动窗口产生的固定锚框集合预测类别分数和边界框偏移量。与YOLO相比,SSD更快且更准确。YOLOv2(Redmon and Farhadi, 2017)也采用滑动窗口锚框进行分类和空间位置预测,以实现比YOLO更高的召回率。RetinaNet(Lin et al., 2017b)通过重塑标准交叉熵损失提出了焦点损失函数,从而使检测器在训练期间更加关注困难、分类错误的样本。RetinaNet以高检测速度实现了与两阶段检测器相当的准确性。与YOLOv2相比,YOLOv3(Redmon and Farhadi, 2018)和YOLOv4(Bochkovskiy et al., 2020)通过一系列改进进一步提高了性能,在不牺牲速度的情况下实现了巨大的性能提升,并且在处理小对象时更加稳健。还存在一些无锚方法,它们不使用锚边界框,如FCOS(Tian et al., 2019b)、CornerNet(Law and Deng, 2018)、ExtremeNet(Zhou et al., 2019b)、CenterNet(Zhou et al., 2019a; Duan et al., 2019)和CentripetalNet(Dong et al., 2020)。关于这些工作的进一步综述,可参考最近的调查文献[Zou et al., 2019; Zhao et al., 2019; Liu et al., 2020a; Sultana et al., 2020b]。
讨论
二维目标检测方法在二维平面机器人抓取任务中被广泛使用。这部分内容可参考第4.1节。
三维目标检测
三维目标检测旨在找到目标物体的三维边界框(amodel 3D bounding box),即找到一个完整目标物体所占据的三维空间范围。三维目标检测在室外场景和室内场景中均得到了深入研究。针对机器人抓取任务,我们可以通过RGB-D数据获取场景中的二维和三维信息,并使用通用的三维目标检测方法。与二维目标检测任务类似,三维目标检测也存在两阶段方法和一阶段方法。两阶段方法基于候选区域,而一阶段方法基于回归。三维目标检测的典型功能流程图如图8所示。
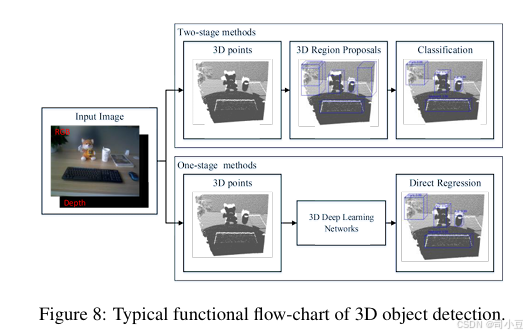
两阶段方法
传统的三维检测方法通常针对已知形状的物体。三维目标检测问题被转化为检测和六维姿态估计问题。提出了许多手工设计的三维形状描述符,如自旋图像(Spin Images)[Johnson, 1997]、三维形状上下文(3D Shape Context)[Frome et al., 2004]、快速点特征直方图(FPFH)[Rusu et al., 2009a]、聚类视图特征直方图(CVFH)[Aldoma et al., 2011]、签名直方图方向(SHOT)[Salti et al., 2014]等,这些描述符可用于定位候选物体。此外,可以通过局部配准获得目标物体的精确六维姿态。这部分内容在第3.1节中介绍。然而,这些方法在通用三维目标检测任务中面临困难。针对通用三维目标检测任务,三维候选区域得到了广泛应用。传统方法基于三维形状描述符训练分类器,如支持向量机(SVM)。提出了滑动形状(Sliding Shapes)[Song and Xiao, 2014],该方法在三维空间中滑动一个三维检测窗口,并从三维点云中提取特征以训练一个范例支持向量机(Exemplar-SVM)分类器[Mal isiewicz et al., 2011]。随着深度学习的发展,可以高效地生成三维候选区域,并且可以使用深度神经网络中的特征来回归三维边界框,而不是训练传统分类器。存在多种生成三维候选区域的方法,这些方法大致可分为三类:基于视锥体的方法[Qi et al., 2018; Xu et al., 2018; Wang and Jia, 2019]、基于全局回归的方法[Song and Xiao, 2016; Chen et al., 2017; Liang et al., 2019b]和基于局部回归的方法。基于视锥体的方法使用成熟的二维目标检测器生成候选物体,这是一种直接的方法。Frustum PointNets[Qi et al., 2018]利用二维卷积神经网络(CNN)目标检测器获得二维区域,并将提升后的视锥体状三维点云变为三维候选区域。基于PointNet[Qi et al., 2017a],从候选区域内的分割点特征中回归出模型三维边界框。PointFusion[Xu et al., 2018]首先利用Faster R-CNN[Ren et al., 2015b]获得图像裁剪,然后将对应图像和原始点云的深度特征进行密集融合,以回归三维边界框。FrustumConvNet[Wang and Jia, 2019]也利用了从二维候选区域提升而来的三维候选区域,并为每个候选区域生成一系列视锥体。基于全局回归的方法从单个或多个输入的特征表示中生成三维候选区域。Deep Sliding Shapes[Song and Xiao, 2016]提出了第一个使用三维卷积神经网络(ConvNets)的三维候选区域网络(RPN)和第一个联合目标识别网络(ORN),以提取三维几何特征和二维颜色特征,从而回归三维边界框。MV3D[Chen et al., 2017]使用鸟瞰图表示点云,并采用二维卷积生成三维候选区域。通过多视图数据的感兴趣区域(ROI)池化获得的区域特征被融合起来,以共同预测三维边界框。MMF[Liang et al., 2019b]提出了一个用于二维和三维目标检测的多任务多传感器融合模型,该模型使用多传感器融合特征生成少量高质量的三维检测结果,并应用ROI特征融合来回归更准确的二维和三维边界框。Part-A2[Shi et al., 2020b]预测了物体内部部件的位置,并通过将点云输入到编码器-解码器网络中生成三维候选区域。提出了一种ROI感知点云池化方法来聚合每个三维候选区域中的部件信息,并提出了一种部件聚合网络来细化结果。PV-RCNN[Shi et al., 2020a]利用具有三维稀疏卷积[Graham and van der Maaten, 2017; Graham et al., 2018]的体素CNN进行特征编码和候选区域生成,并通过体素集抽象提出体素到关键点的场景编码,以及关键点到网格的ROI特征抽象用于候选区域细化。PV-RCNN在室外场景数据集上实现了显著的三维检测性能。基于局部回归的方法意味着生成逐点的三维候选区域。PointRCNN[Shi et al., 2019]从输入点云中提取逐点特征向量,并从通过分割计算的每个前景点生成三维候选区域。然后进行点云区域池化和规范三维边界框细化。STD[Yang et al., 2019c]设计了球形锚点和将标签分配给锚点的策略以生成准确的基于点的候选区域,并提出了一个PointsPool层来生成用于最终边界框预测的密集候选区域特征。VoteNet[Qi et al., 2019a]提出了一种深度霍夫投票策略,从采样的三维种子点生成三维投票点。对三维投票点进行聚类以获得候选物体,这些候选物体将进一步细化。MLCVNet[Xie et al., 2020c]提出了多级上下文VoteNet,考虑了物体之间的上下文信息。H3DNet[Zhang et al., 2020b]预测了一组几何基元的混合集合,如三维边界框的中心点、面中心点和边中心点,并将三维目标检测表述为回归和聚合这些几何基元。然后利用匹配和细化模块对候选物体进行分类并微调结果。与仅使用点云输入的VoteNet[Qi et al., 2019a]相比,ImVoteNet[Qi et al., 2020]还从二维图像中提取了几何和语义特征,并将这些二维特征融合到三维检测流程中,从而在室内场景数据集上实现了显著的三维检测性能。
一阶方法
一阶方法使用单阶段网络直接预测类别概率并回归物体的三维非模态边界框。这些方法无需生成区域建议或进行后处理。VoxelNet[Zhou and Tuzel, 2018]将点云划分为等间距的三维体素,并将每个体素内的点群转换为统一的特征表示。通过卷积中间层和区域建议网络,得到最终结果。与VoxelNet相比,SECOND[Yan et al., 2018b]采用稀疏卷积层[Graham et al., 2018]来解析紧凑的体素特征。PointPillars[Lang et al., 2019]将点云转换为稀疏伪图像,并通过二维卷积主干网络处理成高级表示。主干网络的特征被检测头用于预测物体的三维边界框。TANet[Liu et al., 2020c]提出了三重注意力(Triple Attention,TA)模块和粗细回归(Coarse-to-Fine Regression,CFR)模块,专注于困难物体的三维检测和对噪声点的鲁棒性。HVNet[Ye et al., 2020]提出了混合体素网络,该网络在逐点层面上融合了不同尺度的体素特征编码器(VFE),并将其投影到多个伪图像特征图上。上述方法主要是基于体素的三维单阶段检测器,而Yang等人[Yang et al., 2020b]提出了一种基于点的三维单阶段物体检测器,称为3DSSD,其中包括在下采样过程中的融合采样策略、候选生成层以及带有三维中心点分配策略的无锚回归头。它们在准确性和效率之间实现了良好的平衡。Point-GNN[Shi and Rajkumar, 2020]在点云上利用图神经网络,并设计了一种具有自动配准机制的图神经网络,能够一次性检测多个物体。DOPS[Najibi et al., 2020]提出了一种物体检测流程,该流程利用三维稀疏U-Net[Graham and van der Maaten, 2017]和图卷积模块。他们的方法可以联合预测物体的三维形状。Associate-3Ddet[Du et al., 2020]学习将从真实场景中提取的特征与来自类别概念模型的更具辨别力的特征相关联。有关三维物体检测的全面综述可参考[Guo et al., 2020]的调查报告。
讨论
三维物体检测仅呈现目标物体的大致形状,这对于机器人抓取操作来说是不够的,因此它主要应用于自动驾驶领域。然而,估计的三维边界框可以提供大致的抓取位置,并为碰撞检测提供有价值的信息。
2.3 物体实例分割
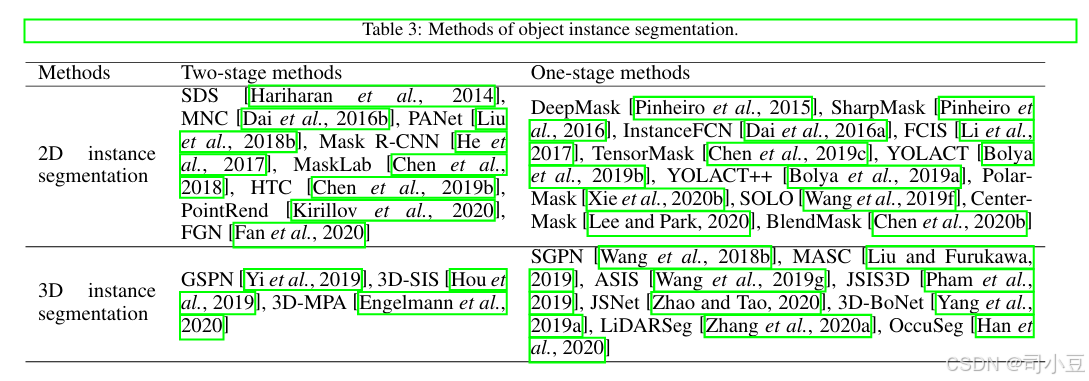
物体实例分割是指检测某一类别的像素级或点级实例物体,它与物体检测和语义分割任务密切相关。同样存在两种方法:两阶段方法和一阶段方法。两阶段方法基于区域建议,而一阶段方法则基于回归。这两种方法的代表性工作如表3所示,分别针对二维输入和三维输入。
二维物体实例分割
二维物体实例分割是指从输入图像中检测某一类别的像素级实例物体,通常以掩膜的形式表示。两阶段方法遵循成熟的物体检测框架,而一阶段方法则直接从整个输入图像进行回归。二维物体实例分割的典型功能流程图如图9所示。
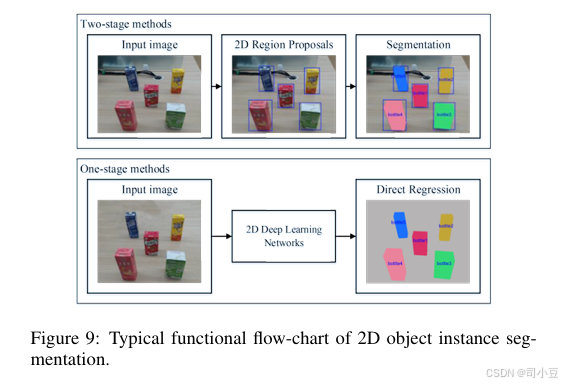
两阶段方法
这类方法也可以称为基于区域建议的方法。成熟的二维物体检测器用于生成边界框或区域建议,然后在这些边界框内预测物体掩膜。许多方法都是基于卷积神经网络(CNN)的。SDS[Hariharan等人,2014]使用CNN对与类别无关的区域建议进行分类。MNC[Dai等人,2016b]通过三个网络分别进行实例区分、掩膜估计和物体分类,从而实现实例分割。提出了路径聚合网络(PANet)[Liu等人,2018b],增强了基于区域建议的实例分割框架中的信息流。Mask R-CNN[He等人,2017]通过添加一个分支来预测物体掩膜,与现有的用于边界框识别的分支并行,从而扩展了Faster R-CNN[Ren等人,2015b],并取得了显著成果。MaskLab[Chen等人,2018]同样基于Faster R-CNN[Ren等人,2015b]构建,并额外产生了语义和实例中心方向输出。Chen等人[Chen等人,2019b]提出了一个名为混合任务级联(HTC)的框架,该框架对物体检测和分割进行联合级联细化,并采用全卷积分支提供空间上下文。PointRend[Kirillov等人,2020]基于迭代细分算法,在自适应选择的位置执行基于点的分割预测。PointRend可以通过在其基础上构建灵活地应用于实例分割任务,并产生更详细的结果。FGN[Fan等人,2020]为少样本实例分割提出了一个全引导网络(FGN),该网络将不同的引导机制引入到Mask R-CNN[He等人,2017]的各种关键组件中。
单阶段方法
这类方法也可以称为基于回归的方法,其中分割掩膜和物体性分数是同时预测的。Deep Mask[Pinheiro等人,2015]、SharpMask[Pinheiro等人,2016]和InstanceFCN[Dai等人,2016a]预测位于中心物体的分割掩膜。FCIS[Li等人,2017]被提出为全卷积实例感知语义分割方法,其中使用位置敏感的内外得分图来执行物体分割和检测。TensorMask[Chen等人,2019c]使用结构化的4D张量在空间域上表示掩膜,并提出了一个框架来预测密集掩膜。YOLACT[Bolya等人,2019b]将实例分割分解为两个并行子任务,即生成一组原型掩膜和预测每个实例的掩膜系数。YOLACT是第一个实时单阶段实例分割方法,并由YOLACT++[Bolya等人,2019a]进行了改进。PolarMask[Xie等人,2020b]将实例分割问题表述为通过实例中心分类和极坐标中的密集距离回归来预测实例轮廓。SOLO[Wang等人,2019f]引入了实例类别的概念,根据实例的位置和大小为每个实例内的每个像素分配类别,从而将实例掩膜分割转换为可解决的分类问题。CenterMask[Lee和Park,2020]在与Mask R-CNN[He等人,2017]相同的思路下,为无锚单阶段物体检测器(FCOS[Tian等人,2019b])添加了一个新颖的空间注意力引导掩膜(SAG-Mask)分支。BlendMask[Chen等人,2020b]也基于FCOS[Tian等人,2019b]物体检测器构建,它使用一个混合器模块来有效预测密集的每像素位置敏感实例特征,并为每个实例学习注意力图。详细综述请参考调查[Sultana等人,2020a;Hafiz和Bhat,2020]。
讨论
二维物体实例分割在机器人抓取任务中得到了广泛应用。例如,SegICP [Wong等人, 2017] 利用基于RGB的物体分割来获取属于目标物体的点。Xie等人 [Xie等人, 2020a] 分别利用RGB和深度信息进行未见物体实例分割。Danielczuk等人 [Danielczuk等人, 2019] 使用在合成数据上训练的Mask R-CNN [He等人, 2017] 从真实深度图像中分割出未知的3D物体。
三维物体实例分割
三维物体实例分割意味着从输入的3D点云中检测出某一类物体的点级实例。与二维物体实例分割类似,两阶段方法需要区域提议,而一阶段方法则无需提议。三维物体实例分割的典型功能流程图如图10所示。
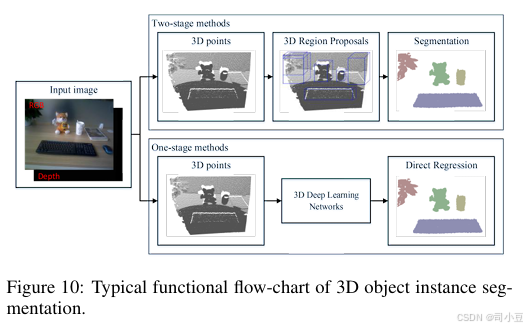
两阶段方法
这类方法也可以称为基于提议的方法。一般方法利用2D或3D检测结果,在相应的视锥体或边界框中进行前景或背景分割。GSPN [Yi等人, 2019] 提出了生成形状提议网络(GSPN)来生成3D物体提议,以及Region-PointNet框架来进行3D物体实例分割。3D-SIS [Hou等人, 2019] 利用联合2D和3D端到端特征学习,对几何和RGB输入进行3D物体边界框检测和语义实例分割。3D-MPA [Engelmann等人, 2020] 基于从稀疏体积主干网络学习到的语义特征预测密集物体中心,采用图卷积网络显式建模相邻提议特征之间的高阶交互,并利用多提议聚合策略而非非极大值抑制(NMS)来获得最终结果。
一阶段方法
这类方法也可以称为基于回归的方法。许多方法学习将每点特征分组以分割3D实例。SGPN [Wang等人, 2018b] 提出了相似性分组提议网络(SGPN)来预测点分组提议和每个提议对应的语义类别,从而可以直接提取实例分割结果。MASC [Liu和Furukawa, 2019] 利用子流形稀疏卷积 [Graham和van der Maaten, 2017; Graham等人, 2018] 来预测每个点的语义分数以及不同尺度下相邻体素之间的亲和力。然后基于预测的亲和力和网格拓扑将点分组为实例。ASIS [Wang等人, 2019g] 学习语义感知的点级实例嵌入,并将属于同一实例的点的语义特征融合在一起,以进行逐点语义预测。JSIS3D [Pham等人, 2019] 提出了一种多任务逐点网络(MT-PNet),该网络同时预测3D点的物体类别,并将这些3D点嵌入到高维特征向量中,从而允许将点聚类为物体实例。JS Net [Zhao和Tao, 2020] 也提出了一个联合实例和语义分割(JISS)模块,并设计了一个高效的点云特征融合(PCFF)模块来生成更具区分性的特征。3D-BoNet [Yang等人, 2019a] 被提出用于直接回归点云中所有实例的3D边界框,同时预测每个实例的点级掩码。LiDARSeg [Zhang等人, 2020a] 提出了一种密集特征编码技术,一种单次实例预测的解决方案,以及处理严重类别不平衡的有效策略。OccuSeg [Han等人, 2020] 提出了一种占用感知的3D实例分割方案,该方案预测每个实例占用的体素数量。占用信号指导3D实例分割的聚类阶段,OccuSeg取得了显著的性能。
讨论
三维物体实例分割在机器人抓取任务中非常重要。然而,当前方法主要利用二维实例分割方法来获取目标物体的3D点云,这利用了RGB-D图像的优势。如今,三维物体实例分割仍然是一个快速发展的领域,如果其性能和速度得到大幅提升,未来将得到广泛应用。
3 物体位姿估计
在某些二维平面抓取任务中,目标物体被限制在二维工作空间内且不会堆叠,此时物体的六维姿态(6D object pose)可以用二维位置和平面内旋转角度来表示。这种情况相对简单,并且基于二维特征点或二维轮廓曲线的匹配可以得到很好的解决。在其他二维平面抓取和六自由度(6DoF)抓取场景中,通常需要知道物体的六维姿态,这有助于机器人了解目标物体的三维位置和三维方向。物体的六维姿态实现了从物体坐标系到相机坐标系的转换。本节我们主要关注六维物体姿态估计,并将其分为三类:基于对应的方法、基于模板的方法和基于投票的方法。在回顾每种方法时,我们都讨论了传统方法和基于深度学习的方法。
3.1 基于对应点的方法
基于对应点的6D物体姿态估计涉及在观测输入数据和现有的完整3D物体模型之间找到对应点的方法。当我们想基于2D RGB图像来解决这个问题时,我们需要找到2D像素与现有3D模型的3D点之间的对应点。因此,可以通过透视n点(Perspective-n-Point,PnP)算法[Lepetit等人,2009]来恢复6D物体姿态。当我们想基于从深度图像提取的3D点云来解决这个问题时,我们需要找到观测到的部分视图点云与完整3D模型之间的3D点的对应点。因此,可以通过最小二乘法来恢复6D物体姿态。基于对应点的方法在表4中进行了总结。
PnP算法基于透视投影模型,该模型描述了三维点如何投影到二维图像中。其目标是根据已知的三维点坐标和对应的二维图像点坐标,计算出相机的姿态,即相机的旋转矩阵R和平移向量t。简单来说,就是通过已知的n个三维空间点及其在二维图像中的投影位置,来估计相机的位姿

基于2D图像的方法
在使用2D RGB图像时,基于对应点的方法主要通过匹配2D特征点来针对具有丰富纹理的物体,如图11所示。首先,通过将现有的3D模型从不同角度进行投影来渲染多张图像,渲染图像中的每个物体像素都对应一个3D点。通过匹配观测图像和渲染图像上的2D特征点[Vacchetti等人,2004;Lepetit等人,2005],可以建立2D-3D对应点。除了渲染图像外,基于关键帧的同时定位与地图构建(Simultaneous Localization and Mapping,SLAM)方法[Mur-Artal等人,2015]中的关键帧也可以为2D关键点提供2D-3D对应点。常用的2D描述符,如尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)[Lowe,1999]、快速加速鲁棒特征(Features from Accelerated Segment Test,FAST)[Rosten和Drummond,2005]、加速鲁棒特征(Speeded Up Robust Features,SURF)[Bay等人,2006]、定向快速和旋转不变BRIEF(Oriented FAST and Rotated BRIEF,ORB)[Rublee等人,2011]等,通常用于2D特征匹配。基于2D-3D对应点,可以通过透视n点(PnP)算法[Lepetit等人,2009]来计算6D物体姿态。然而,当物体没有丰富纹理时,这些基于2D特征的方法会失效。
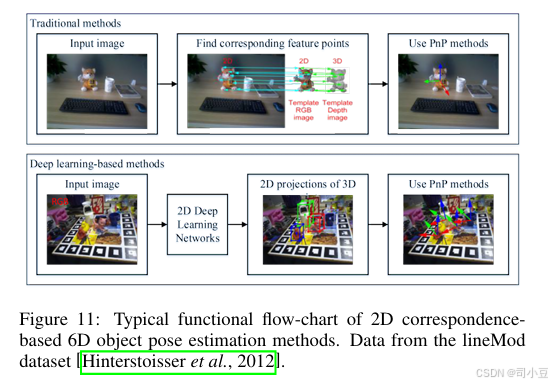
随着卷积神经网络(Convolutional Neural Network,CNN)等深度神经网络的发展,可以从图像中提取代表性特征。一种直接的方法是提取判别性特征点[Yi等人,2016;Truong等人,2019],并使用代表性CNN特征进行匹配。Yi等人[Yi等人,2016]提出了一种类似于SIFT的特征描述符。Truong等人[Truong等人,2019]提出了一种贪婪学习精确匹配点的方法。Superpoint[DeTone等人,2018]提出了一个自监督框架来训练兴趣点检测器和描述符,该框架在某些传统特征检测器和描述符方面显示出优势。LCD[Pham等人,2020]专门学习了一个用于2D图像和3D点云匹配的局部跨域描述符,其中包含一个双自动编码器神经网络,该网络将2D和3D输入映射到一个共享的潜在空间表示中。还存在另一种方法[Rad和Lepetit,2017;Tekin等人,2018;Crivellaro等人,2017;Hu等人,2019],其使用代表性CNN特征来预测3D点的2D位置,如图11所示。由于很难选择要投影的3D点,因此许多方法都使用物体3D边界框的八个顶点。Rad和Lepetit[Rad和Lepetit,2017]预测了其3D边界框角点的2D投影,并获得了2D-3D对应点。与他们不同的是,Tekin等人[Tekin等人,2018]提出了一种单次深度CNN架构,该架构可以直接检测3D边界框顶点的2D投影,而无需进行后验细化。其他方法利用3D物体的特征点。Crivellaro等人[Crivellaro等人,2017]在卷积神经网络(CNN)的帮助下,以少量控制点的2D投影的形式预测了物体各部分的姿态。KeyPose[Liu等人,2020b]使用来自立体输入的3D关键点来预测物体姿态,适用于透明物体。Hu等人[Hu等人,2020]进一步使用深度学习网络以单阶段的方式从一组候选2D-3D对应点中预测6D物体姿态,而不是基于随机抽样一致性(RANSAC)的透视n点(PnP)算法。HybridPose[Song等人,2020]预测了一个混合中间表示来表达输入图像中的不同几何信息,包括关键点、边缘向量和对称对应点。其他方法预测了物体所有像素的3D位置。Hu等人[Hu等人,2019]提出了一种分割驱动的6D姿态估计框架,其中物体的每个可见部分都以2D关键点位置的形式对局部姿态预测做出贡献。姿态候选者被组合成一个稳健的2D-3D对应点集,从中计算出可靠的姿态估计结果。DPOD[Zakharov等人,2019]估计了输入图像和可用3D模型之间的密集多类2D-3D对应点图。Pix2pose[Park等人,2019b]使用3D模型(无纹理)从RGB图像中回归物体的像素级3D坐标。EPOS[Hodan等人,2020]通过表面片段来表示物体,从而可以处理对称性,预测每个像素处数据依赖的精确3D位置数量,建立多对多的2D-3D对应点,并利用估计器来恢复多个物体实例的姿态。
基于3D点云的方法
图12展示了基于3D匹配的6D物体姿态估计方法的典型功能流程图。当使用从深度图像中提取的3D点云时,可以利用3D几何描述符进行匹配,从而消除纹理的影响。然后,可以通过直接基于3D-3D对应关系计算变换来获得6D物体姿态。广泛使用的3D局部形状描述符,如Spin Images(约翰逊,1997年)、3D Shape Context(Frome等人,2004年)、FPFH(Rusu等人,2009a)、CVFH(Aldoma等人,2011年)、SHOT(Salti等人,2014年),可用于找到物体部分3D点云与完整点云之间的对应关系,从而获得6D物体姿态。其他3D局部描述符可参考相关综述(Guo等人,2016b)。然而,这类方法要求目标物体具有丰富的几何特征。还存在基于深度学习的3D描述符[Zeng等人,2017a;Yew和Lee,2018],旨在匹配具有代表性和判别性的3D点。3DMatch(Zeng等人,2017a)提出使用基于3D体素的深度学习网络来匹配3D特征点。3DFeat-Net(Yew和Lee,2018)提出了一种弱监督网络,该网络仅使用GPS/INS标记的3D点云整体学习3D特征检测器和描述符。Gojcic等人(Gojcic等人,2019)提出了3DSmoothNet,其使用具有体素化平滑密度值(SDV)表示的孪生深度学习架构和全卷积层来匹配3D点云。Yuan等人(Yuan等人,2020)提出了一种用于点云中描述符的自监督学习方法,该方法无需手动标注即可实现具有竞争力的性能。StickyPillars(Simon等人,2020)提出了一种基于图神经网络的端到端训练的3D特征匹配方法,他们借助基于Transformer的多头自注意力和交叉注意力机制进行上下文聚合。
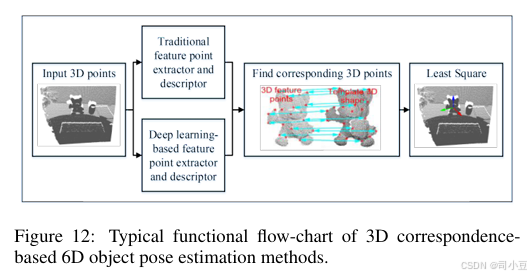
3.2 基于模板的方法
基于模板的6D物体姿态估计涉及从已标注真实6D物体姿态的模板中找到最相似模板的方法。在二维情况下,模板可以是已知3D模型的投影二维图像,模板中的物体在相机坐标系中具有相应的6D物体姿态。因此,6D物体姿态估计问题就转化为图像检索问题。在三维情况下,模板可以是目标物体的完整点云。我们需要找到最佳6D姿态,使部分点云与模板对齐,从而将6D物体姿态估计问题转化为部分到整体的粗略配准问题。基于模板的方法总结在表5中。

基于二维图像的方法
如果存在具有区分性的特征点,则可以使用传统的基于二维特征的方法来找到最相似的模板图像,并可以利用基于二维对应的方法。因此,这类方法主要针对难以用基于对应的方法处理的无纹理或非纹理物体。在这些方法中,通常利用梯度信息。图13展示了基于二维模板的6D物体姿态估计方法的典型功能流程图。将现有完整3D模型从不同角度投影生成的多个图像视为模板。Hinterstoisser等人(Hinterstoisser et al., 2012)通过扩展图像梯度方向用于模板匹配,提出了一种新颖的图像表示方法,并用有限的模板集表示3D物体。通过考虑从密集深度传感器获得的密集点云计算出的3D表面法线方向,提高了估计姿态的准确性。Hodaň等人(Hodaň et al., 2015)提出了一种在RGB-D图像中检测和精确定位多个无纹理刚性物体的方法。通过匹配不同模态下的特征点来验证候选物体实例,并将与每个检测到的模板相关联的近似物体姿态用作进一步优化的初始值。存在基于深度学习的图像检索方法(Gordo et al., 2016),可以辅助模板匹配过程。然而,很少有方法将它们用于基于模板的方法中,或许是因为模板数量太少,无法让深度学习方法学习到具有代表性和区分性的特征。
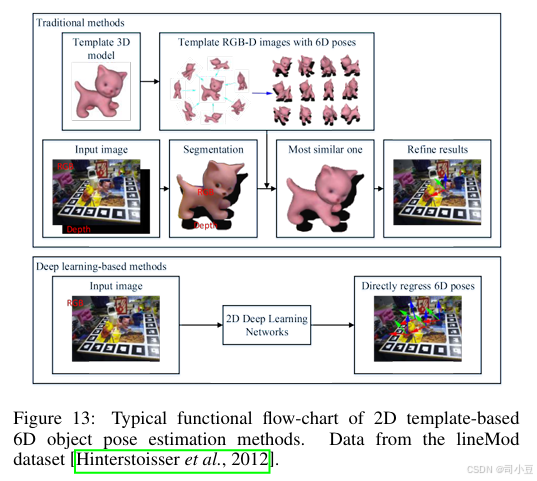
上述方法显式地找到最相似的模板,还存在一些隐式方法。Sundermeyer等人(Sundermeyer et al., 2018)提出了增强自编码器(Augmented Autoencoders, AAE),其隐式地学习3D方向。从完整3D模型渲染出数千张模板图像,并将这些模板图像编码成码本。输入图像将被编码成一个新代码,并与码本进行匹配以找到最相似的模板图像,从而获得6D物体姿态。
还存在一些方法(Xiang et al., 2018; Do et al., 2018a; Liu et al., 2019a)直接从输入图像估计目标物体的6D姿态,这可以视为隐式地从预训练和标注的图像中找到最相似的图像。与基于对应的方法不同,这类方法学习从输入图像到姿态参数表示的直接映射,因此可以结合物体检测来估计6D物体姿态(Patil and Rabha, 2018)。Xiang等人(Xiang et al., 2018)提出了PoseCNN用于直接6D物体姿态估计。通过定位图像中的中心并预测与相机的距离来估计物体的三维平移,通过回归四元数表示来计算三维旋转。Kehl等人(Kehl et al., 2017)利用SSD网络提出了一种类似的方法。Do等人(Do et al., 2018a)提出了一个名为Deep-6DPose的端到端深度学习框架,该框架可以联合检测、分割并从单个RGB图像中恢复物体实例的6D姿态。他们通过向实例分割网络Mask R-CNN(He et al., 2017)添加姿态估计分支来直接回归6D物体姿态,而无需任何后处理细化。Liu等人(Liu et al., 2019a)提出了一种两阶段卷积神经网络(CNN)架构,该架构可以直接输出6D姿态,而无需像PnP那样需要多个阶段或额外的后处理。他们将姿态估计问题转化为分类和回归任务。CDPN(Li et al., 2019)提出了基于坐标的解缠姿态网络(Coordinates-based Disentangled Pose Network, CDPN),该网络将姿态解缠以分别预测旋转和平移。Tian等人(Tian et al., 2020)还提出了旋转回归的离散-连续公式来解决局部最优问题。他们在SO(3)中均匀采样旋转锚点,并预测每个锚点到目标的受限偏差。
还存在为类别级物体构建潜在表示的方法。这类方法也可以视为基于模板的方法,并且模板可以从多个图像中隐式构建。NOCS(Wang et al., 2019c)、LatentFusion(Park et al., 2020)和Chen等人(Chen et al., 2020a)是代表性方法。
基于3D点云的方法
基于3D模板的6D物体姿态估计方法的典型功能流程图如图14所示。传统的部分配准方法旨在找到最佳地将部分点云与完整点云对齐的6D变换。存在各种全局配准方法[Mellado等人,2014;Yang等人,2015;Zhou等人,2016],这些方法可以应对初始姿态的大幅变化,并且对大噪声具有鲁棒性。然而,这类方法耗时较长。其中大多数方法利用局部配准方法,如迭代最近点(ICP)算法[Besl和McKay,1992],来优化结果。这部分内容可以参考一些综述论文[Tam等人,2013;Bellekens等人,2014]。
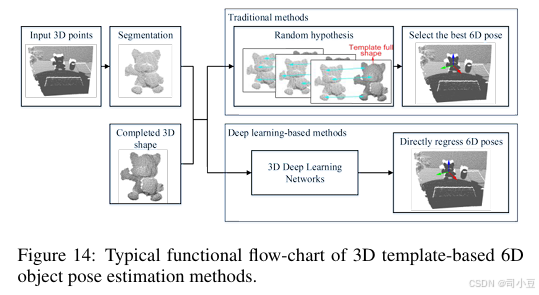
也存在一些基于深度学习的方法,这些方法能够高效地完成部分配准任务。这些方法接收一对点云,从3D深度学习网络中提取具有代表性和判别性的特征,并回归这对点云之间的相对6D变换。PCRNet[Sarode等人,2019b]、DCP[Wang和Solomon,2019a]、PointNetLK[Aoki等人,2019]、PRNet[Wang和Solomon,2019b]、DeepICP[Lu等人,2019]、Sarode等人[Sarode等人,2019a]、TEASER[Yang等人,2020a]和DGR[Choy等人,2020]是代表性方法,读者可参考最近的综述[Villena-Martinez等人,2020]。还存在一些方法[Chen等人,2020c;Gao等人,2020],它们直接从部分点云回归6D物体姿态。G2L-Net[Chen等人,2020c]通过2D检测从RGB-D图像中提取粗略的物体点云,然后进行平移定位和旋转定位。Gao等人[Gao等人,2020]通过对点云进行监督学习来进行6D物体姿态回归。
3.3 基于投票的方法
基于投票的方法意味着每个像素或3D点通过提供一个或多个投票来参与6D物体姿态的估计。我们大致将投票方法分为两类,即间接投票方法和直接投票方法。间接投票方法意味着每个像素或3D点对一些特征点进行投票,这些特征点提供了2D-3D对应或3D-3D对应。直接投票方法意味着每个像素或3D点对某个6D物体坐标或姿态进行投票。这些方法在表6中进行了总结。

间接投票方法
这类方法可以视为对基于对应的方法的投票。在2D情况下,对2D特征点进行投票,可以实现2D-3D对应。在3D情况下,对3D特征点进行投票,可以实现观察到的部分点云与规范完整点云之间的3D-3D对应。这类方法大多利用深度学习方法,因为深度学习方法具有强大的特征表示能力,可以预测更好的投票结果。基于间接投票的6D物体姿态估计方法的典型功能流程图如图15所示。

在2D情况下,PVNet[Peng等人,2019]对投影的2D特征点进行投票,然后找到相应的2D-3D对应来计算6D物体姿态。Yu等人[Yu等人,2020]提出了一种方法,该方法从向量场中投票物体的关键点2D位置。他们开发了一种可微分的代理投票损失(DPVL),该损失模拟了投票过程中的假设选择。在3D情况下,PVN3D[He等人,2020]对3D关键点进行投票,可以视为PVNet[Peng等人,2019]在3D领域的变体。YOLOff[Gonzalez等人,2020]利用分类卷积神经网络(CNN)从局部图像块中估计物体在图像中的2D位置,然后利用经过训练的回归CNN预测相机坐标系中一组关键点的3D位置。通过最小化配准误差来实现6D物体姿态的估计。6-PACK[Wang等人,2019a]基于观察到可以通过关键点匹配来估计物体实例的帧间运动,预测物体的少量有序3D关键点。该方法实现了在RGB-D数据上的类别级6D物体姿态跟踪。
直接投票方法
如果我们将被投票的物体姿态或物体坐标视为最相似的模板,那么这类方法可以视为对基于模板的方法的投票。基于直接投票的6D物体姿态估计方法的典型功能流程图如图16所示。
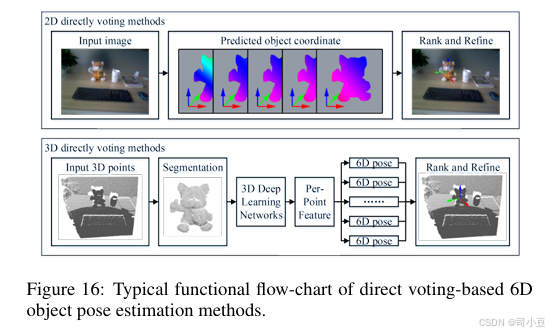
在2D情况下,这类方法主要用于计算被遮挡物体的姿态。对于这些物体,图像中的局部证据限制了期望输出的可能结果,因此通常使用每个图像块对6D物体姿态进行投票。Brachmann等人[Brachmann等人,2014]提出了一种学习的中间表示,该表示以密集的3D物体坐标标签和密集的类别标签配对的形式存在。每个物体坐标预测定义了图像和3D物体模型之间的3D-3D对应,并生成和精炼姿态假设以获得最终假设。Tejani等人[Tejani等人,2014]训练了一个霍夫森林,用于从RGB-D图像中估计6D姿态。森林中的每棵树都将一个图像块映射到一个叶子节点,该叶子节点存储了一组6D姿态投票。
在3D情况下,Drost等人[Drost等人,2010]提出了点对特征(PPF)来从深度图像中恢复物体的6D姿态。点对特征包含两个任意3D点之间的距离和法线信息。作为传统局部和全局管道的有效且集成的替代方案,PPF一直是最成功的6D姿态估计方法之一。Hodan等人[Hodan等人,2018a]提出了一个从单个RGB-D输入图像估计刚体6D姿态的基准,而PPF的一个变体[Vidal等人,2018]赢得了2018年的SIXD挑战。
基于深度学习的方法也辅助了直接投票方法。DenseFusion[Wang等人,2019b]利用了一种异构架构,该架构独立处理RGB和深度数据,并提取逐像素的密集特征嵌入。每个特征嵌入都对6D物体姿态进行投票,并采用最佳预测。他们进一步提出了一种迭代姿态精炼程序来精炼预测的6D物体姿态。MoreFusion[Wada等人,2020]执行了对象级体积融合,并执行了点级体积姿态预测,该预测利用了从图像观测中的体积重建和CNN特征提取。然后,基于对象之间的几何一致性和不可穿透空间,共同精炼对象姿态。
3.4 比较与讨论
本节主要回顾基于RGB-D图像的方法,因为基于3D点云的6D物体姿态估计可以视为一个配准或对齐问题,已有一些相关调查[Tam等人,2013;Bellekens等人,2014]。本节将介绍相关的数据集、评价指标和比较结果。
数据集与评价指标
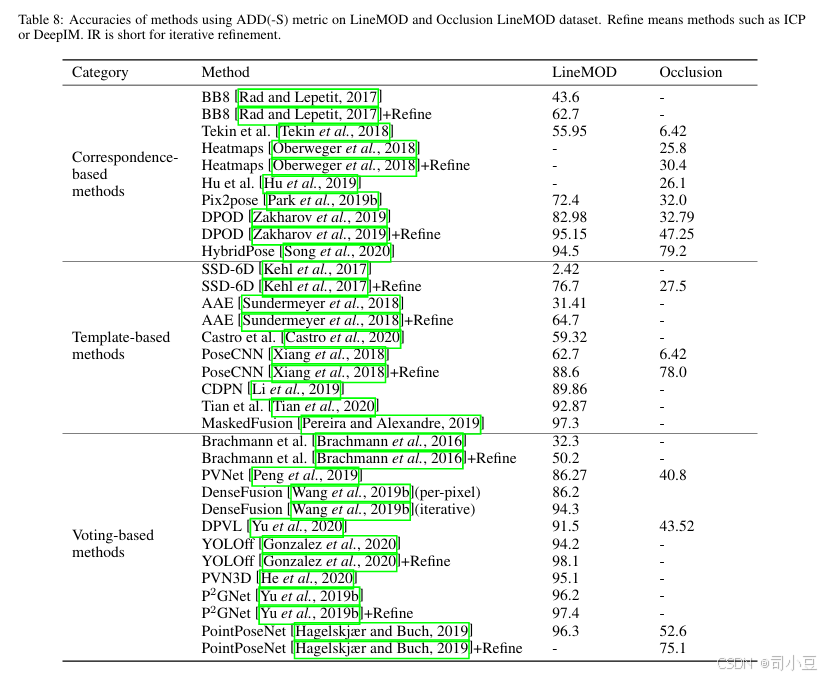
对于6D姿态估计,存在各种基准测试集[Hodaň等人,2018b],如LineMod[Hinterstoisser等人,2012]、IC-MI/IC-BIN数据集[Tejani等人,2014]、T-LESS数据集[Hodaň等人,2017]、RU-APC数据集[Rennie等人,2016]和YCB-Video[Xiang等人,2018]等。这里我们只回顾了最常用的LineMod[Hinterstoisser等人,2012]数据集和YCB-Video[Xiang等人,2018]数据集。LineMod为每个数据集中的15个物体提供了大约1000张图像的手动标注。Occlusion Linemod[Brachmann等人,2014]包含了更多物体被遮挡的示例。YCB-Video包含21个物体的子集,共133,827张图像。这些数据集被广泛用于评估各种方法。6D物体姿态可以用一个4x4矩阵P=[Rt;01]表示,其中R是3x3旋转矩阵,t是3x1平移向量。旋转矩阵也可以用四元数或角度-轴表示法表示。直接比较数值之间的方差不能提供直观的视觉理解。常用的评价指标包括非对称物体的平均模型点距离(ADD)[Hinterstoisser等人,2012]和对称物体的平均最近点距离(ADD-S)[Xiang等人,2018]。给定一个3D模型M、真实旋转R和平移T以及估计的旋转R'和平移T',ADD表示所有模型点x与其变换版本之间的平均距离。如果平均距离小于预定阈值,则认为6D物体姿态是正确的。ADD-S[Xiang等人,2018]是一种歧义不变姿态误差度量,将对称和非对称物体纳入整体评估。给定估计姿态[R'T']和真实姿态[RT],ADD-S计算由[R'T']变换的每个3D模型点到由[RT]变换的目标模型上最近点的平均距离。
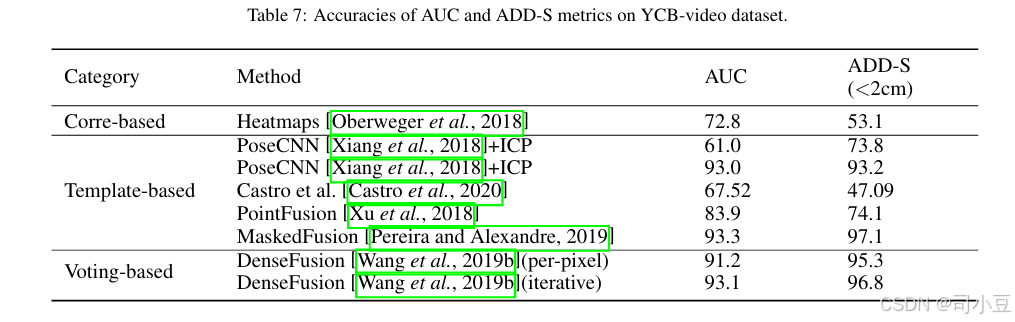
针对LineMOD数据集,ADD用于非对称物体,ADD-S用于对称物体。阈值通常设置为模型直径的10%。针对YCB-Video数据集,常用的评价指标是ADD-S度量。经常使用ADD-S小于2cm(<2cm)的百分比来衡量机器人操作所需的最小容差下的预测结果。此外,还报告了遵循PoseCNN[Xiang等人,2018]的ADD-S曲线下的面积(AUC),并将AUC的最大阈值设置为10cm。
比较与讨论
6D物体姿态估计在机器人和增强现实领域发挥着至关重要的作用。存在多种方法,它们具有不同的输入、精度、速度、优缺点。针对机器人抓取任务,应首先分析实际环境、可用输入数据、可用硬件配置、待抓取目标物体以及任务要求,以决定采用哪种方法。上述三种方法分别适用于不同类型的物体。通常,当目标物体具有丰富的纹理或几何细节时,基于对应关系的方法是不错的选择;当目标物体纹理或几何细节较弱时,基于模板的方法更为合适;当物体被遮挡且仅部分表面可见,或目标物体从特定物体扩展到类别级物体时,基于投票的方法则是较好的选择。此外,这三种方法均接受2D输入、3D输入或混合输入。以RGB-D图像为输入的方法在YCB-Video数据集上的结果总结在表7中,在LineMOD和Occlusion LineMOD数据集上的结果总结在表8中。由于遮挡较少,LineMOD数据集上的所有最新方法均达到了高精度。当存在遮挡时,基于对应关系和基于投票的方法表现优于基于模板的方法。基于模板的方法更像是一个直接的回归问题,高度依赖于提取的全局特征。而基于对应关系和基于投票的方法则利用局部部分信息,构成局部特征表示。
当前6D物体姿态估计方法面临一些挑战。首要挑战在于,当前方法在通常会发生遮挡的杂乱场景中表现出明显的局限性。尽管最先进的方法在Occlusion LineMOD数据集上取得了高精度,但它们仍然无法应对严重遮挡的情况,因为这种情况甚至对人类来说也可能造成歧义。第二个挑战是缺乏足够的训练数据,因为上述数据集的大小相对较小。目前,深度学习方法在训练数据集中不存在的物体上表现不佳,而模拟数据集或许是一个解决方案。尽管最近出现了一些类别级6D物体姿态方法[Wang等人,2019c;Park等人,2020;Chen等人,2020a],但它们仍然无法处理大量类别。
4 抓取估计
抓取估计是指在相机坐标系中估计6D抓取器姿态。如前所述,抓取可分为2D平面抓取和6自由度(6DoF)抓取。对于2D平面抓取,抓取在一个方向受限,因此6D抓取器姿态可以简化为3D表示,包括2D平面内位置和1D旋转角度,因为高度和其他轴上的旋转是固定的。对于6DoF抓取,抓取器可以从不同角度抓取物体,6D抓取器姿态对于执行抓取至关重要。本节将详细介绍2D平面抓取和6DoF抓取的方法。
4.1 2D平面抓取
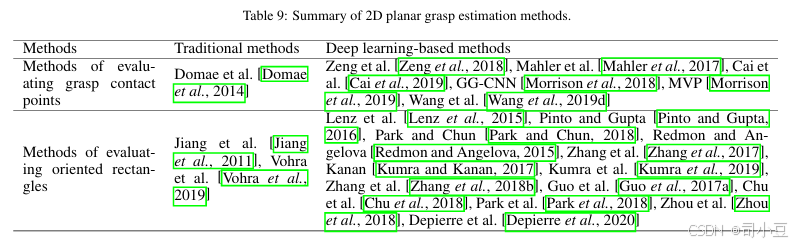
2D平面抓取方法可分为评估抓取接触点的方法和评估有向矩形的方法。在2D平面抓取中,抓取接触点可以唯一确定抓取器的抓取姿态,这在6DoF抓取中并非如此。2D有向矩形也可以唯一确定抓取器的抓取姿态。这些方法总结在表9中,典型的功能流程图如图17所示。
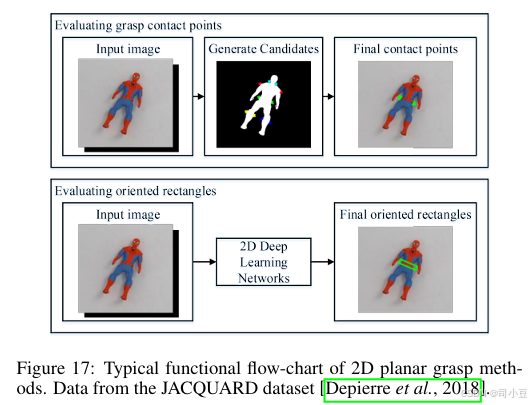
评估抓取接触点的方法
这类方法首先采样候选抓取接触点,并使用分析方法或基于深度学习的方法来评估成功抓取的可能性,这些都是基于分类的方法。机器人抓取的经验方法是在已知某些先验知识(如物体几何形状、物理模型或力分析)的前提下进行的。抓取数据库通常只包含有限数量的物体,经验方法在处理未知物体时会遇到困难。Domae等人[Domae et al., 2014]提出了一种方法,该方法在单个深度图上估计随机放置在容器中的物体的抓取性度量。首先提取候选抓取区域,然后通过将一个接触区域掩模图像和一个碰撞区域掩模图像进行卷积来计算抓取性。基于深度学习的方法可以辅助评估候选抓取接触点的抓取质量。Mahler等人[Mahler et al., 2017]提出了DexNet 2.0,它使用合成点云和分析抓取指标来规划稳健的抓取。他们首先从深度图像中分割出当前感兴趣点,并生成多个候选抓取。然后使用Grasp Quality-CNN网络测量抓取质量,并选择质量最高的作为最终抓取。他们的数据库包含超过50,000个抓取,抓取质量测量网络取得了相对令人满意的性能。
基于深度学习的方法还可以通过估计像素级的抓取能力来估计最可能的抓取接触点。机器人抓取能力[Do et al., 2018b; Ard´on et al., 2019; Chu et al., 2019]通常旨在预测物体部分对于机器人操作的抓取能力,这更像是一个分割问题。然而,存在一些方法[Zeng et al., 2018; Cai et al., 2019]预测相对于抓取基本动作的像素级抓取能力。这些方法为每个像素生成抓取质量,并执行具有最高抓取能力值的点对。Zeng等人[Zeng et al., 2018]提出了一种方法,该方法利用全卷积网络推断四种不同抓取基本动作的抓取能力的密集像素级概率图。Cai等人[Cai et al., 2019]提出了一种像素级抓取能力解释器网络,该网络基于与Zeng等人[Zeng et al., 2018]类似的全卷积残差网络学习对极抓取模式。这两种方法都不对目标物体进行分割,而是为每个像素预测像素级的抓取能力图。这是一种无需采样抓取候选即可直接估计抓取质量的方法。Morrison等人[Morrison et al., 2018]提出了生成抓取卷积神经网络(GG-CNN),该网络预测每个像素的抓取质量和姿态。此外,Morrison等人[Morrison et al., 2019]提出了一种多视图拾取(MVP)控制器,该控制器使用主动感知方法根据抓取姿态估计的分布选择信息丰富的观察点。他们利用实时GG-CNN[Morrison et al., 2018]进行视觉抓取检测。Wang等人[Wang et al., 2019d]提出了一种全卷积神经网络,该网络将原始输入图像编码为特征,并对这些特征进行解码以生成每个像素的机器人抓取属性。与通过神经网络生成多个抓取候选的分类方法不同,他们的像素级实现通过一次前向传播直接预测多个抓取候选。
定向矩形评估方法
Jiang等人[Jiang et al., 2011]首先提出使用定向矩形来表示夹持器配置,他们采用了一个两步程序,该程序首先利用某些易于计算的特征来修剪搜索空间,然后使用高级特征来精确选择一个合适的抓取方式。Vohra等人[Vohra et al., 2019]提出了一种抓取估计策略,该策略估计了点云中对象的轮廓,并预测了抓取姿态以及图像平面中的对象骨架。估算了每个骨架点的抓取矩形,并使用与抓取矩形部分和对象质心相对应的点云数据来确定最终的抓取矩形。他们的方法简单,且无需抓取配置采样步骤。
针对基于定向矩形的抓取配置,深度学习方法逐渐以三种不同的方式应用,即基于分类的方法、基于回归的方法和基于检测的方法。这些方法大多采用五维表示[Lenz et al., 2015]来描述机器人的抓取动作,这种表示方式是将抓取动作视为具有位置、方向和大小的矩形:(x, y, θ, h, w)。
基于分类的方法训练分类器来评估候选抓取动作,并选择得分最高的抓取动作。Lenz等人[Lenz et al., 2015]是首先将深度学习方法应用于机器人抓取的人。他们提出了一个由两个深度网络组成的两步级联系统,其中第一个网络的顶级检测结果由第二个网络重新评估。第一个网络产生一组小型的定向矩形作为候选抓取动作,这些矩形将与坐标轴对齐。第二个网络使用从彩色图像、深度图像和表面法线中提取的特征对这些候选动作进行排序。选择排名最高的矩形,并执行相应的抓取动作。Pinto和Gupta[Pinto and Gupta, 2016]通过采样图像块并预测抓取角度来预测抓取位置。他们训练了一个基于卷积神经网络(CNN)的分类器,以估计给定输入图像块在不同抓取方向上的抓取可能性。Park和Chun[Park and Chun, 2018]提出了一种基于分类的机器人抓取检测方法,该方法使用了多阶段空间变换网络(STN)。他们的方法允许对中间结果(如多个抓取配置候选者的抓取位置和方向)进行部分观测。基于分类的方法过程直观,且准确率相对较高。然而,这些方法往往速度较慢。
基于回归的方法训练一个模型来直接产生位置和方向的抓取参数,因为一个统一的网络将比两步级联系统表现得更好[Lenz et al., 2015]。Redmon和Angelova[Redmon and Angelova, 2015]提出了一个更大的神经网络,该网络执行单阶段回归以获得可抓取的边界框,而无需使用标准的滑动窗口或区域提议技术。Zhang等人[Zhang et al., 2017]利用多模态融合架构,结合RGB特征和深度特征,以提高抓取检测的准确性。Kumra和Kanan[Kumra and Kanan, 2017]使用了深度神经网络,如ResNet[He et al., 2016],进一步提高了抓取检测的性能。Kumra等人[Kumra et al., 2019]提出了一种新的生成残差卷积神经网络(GR-ConvNet)模型,该模型可以从n通道图像输入中生成稳健的对掌抓取。一些方法不是全局回归抓取参数,而是采用了基于感兴趣区域(ROI)或逐像素的方式。Zhang等人[Zhang et al., 2018b]在输入图像中使用了ROI,并基于ROI特征回归了抓取参数。
基于检测的方法利用了参考锚框,这些锚框被用于一些基于深度学习的目标检测算法中[Ren et al., 2015b; Liu et al., 2016; Redmon et al., 2016],以辅助候选抓取的生成和评估。利用预期的抓取尺寸先验知识,可以简化回归问题[Depierre et al., 2020]。Guo等人[Guo et al., 2017a]提出了一种结合了视觉和触觉感知的混合深度架构。他们引入了与坐标轴对齐的参考框。他们的网络生成一个质量分数和一个方向,作为离散角度值之间的分类。Chu等人[Chu et al., 2018]提出了一种架构,该架构可以预测多个候选抓取动作,而不是单个结果,并将方向回归转换为分类任务。方向分类包含质量分数,因此他们的网络既预测抓取回归值,也预测离散方向分类分数。Park等人[Park et al., 2018]提出了一个旋转集成模块(REM),该模块使用旋转网络权重的卷积来进行机器人抓取检测。Zhou等人[Zhou et al., 2018]设计了一种定向锚框机制来提高抓取检测的准确性,并采用了端到端的全卷积神经网络。他们仅使用一个具有多个方向的锚框,而不是多个尺度或纵横比[Guo et al., 2017a; Chu et al., 2018]作为参考抓取,并为每个定向参考框预测五个回归值和一个抓取质量分数。Depierre等人[Depierre et al., 2020]通过添加回归预测和分数评估之间的直接依赖关系,进一步扩展了Zhou等人[Zhou et al., 2018]的工作。他们提出了一种新的深度神经网络(DNN)架构,其中包含一个评估给定位置可抓取性的评分器,并引入了一个新的损失函数,该函数将抓取参数的回归与可抓取性分数相关联。
还提出了一些其他方法,旨在解决杂乱场景中的问题,在这种场景中,机器人需要知道对象是否位于成堆的对象中的另一个对象上,以成功抓取。Guo等人[Guo et al., 2016a]提出了一种共享卷积神经网络来进行对象发现和抓取检测。Zhang等人[Zhang et al., 2018a]提出了一种多任务卷积机器人抓取网络,以解决在成堆的对象中结合抓取检测和对象检测以及关系推理的问题。Zhang等人[Zhang et al., 2018a]的方法由几个深度神经网络组成,这些网络分别负责生成局部特征图、抓取检测、对象检测和关系推理。相比之下,Park等人[Park et al., 2019a]提出了一个单一的多任务深度神经网络,该网络通过简单的后处理即可获得抓取检测、对象检测和对象间关系推理的信息。
比较与讨论
本节对二维平面抓取方法进行了评估,包括数据集、评估指标以及近期方法的比较。
数据集与评估指标
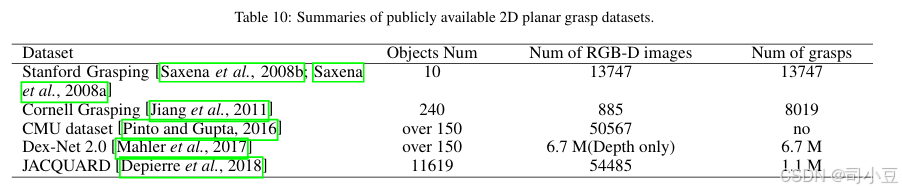
二维平面抓取存在几个数据集,如表10所示。其中,康奈尔抓取数据集(Cornell Grasping dataset)[Jiang等人,2011]是最常用的数据集。此外,该数据集分为图像级划分和对象级划分。图像级划分随机划分图像,用于测试该方法对于之前见过的物体的新位置能否很好地泛化。对象级划分将所有相同物体的图像放入相同的交叉验证划分中,用于测试该方法对于新物体能否很好地泛化。
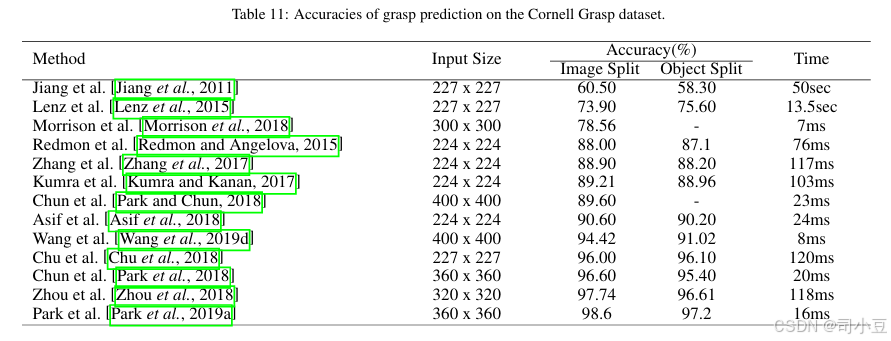
针对基于点的抓取和基于定向矩形的抓取[Jiang等人,2011],存在两种评估抓取检测性能的指标:点指标和矩形指标。前者评估预测抓取中心与真实抓取中心之间的距离,该距离与一个阈值相关。确定距离阈值较为困难,且该指标不考虑抓取角度。后者认为,如果抓取角度与真实抓取角度相差30度以内,且预测抓取A与真实抓取B的杰卡德指数J(AB)= A ∩ B / A ∪ B大于25%,则该抓取为正确。
比较 表11比较了评估定向矩形的方法在广泛使用的康奈尔抓取数据集[Jiang等人,2011]上的表现。从表中可以看出,最先进的方法在该数据集上取得了非常高的准确性。近期工作[Depierre等人,2020]开始在JacquardGrasp数据集[Depierre等人,2018]上进行实验,因为该数据集包含更多图像,且抓取类型更加多样。
4.2 六自由度抓取(6DoFGrasp)
六自由度抓取方法可分为基于部分点云的方法和基于完整形状的方法。这些方法总结在表12中。
基于部分点云的方法
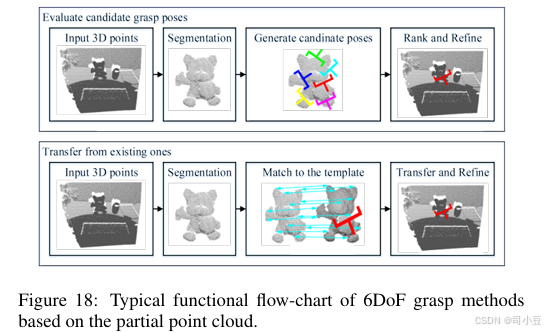
这类方法可分为两种。第一种方法估计候选抓取的抓取质量,第二种方法将抓取从现有抓取中迁移。基于部分点云的方法的典型功能流程图如图18所示。
估计候选抓取抓取质量的方法
这类方法意味着仅通过分析输入的部分点云来估计六自由度抓取姿态。这类方法中的大多数[Bohg和Kragic, 2010; Pas和Platt, 2015; Zapata-Impata等, 2019; ten Pas等, 2017; Liang等, 2019a]首先采样大量候选抓取,然后利用各种方法来评估抓取质量,这是一种基于分类的方式。而一些新方法[Qin等, 2020; Zhao等, 2020a; Ni等, 2020; Mousavian等, 2019]则更简单地估计抓取质量,并一次性直接预测六自由度抓取姿态,这是一种基于回归的方式。
Bohg和Kragic[Bohg和Kragic, 2010]应用了形状上下文[Belongie等, 2002]的概念来提高抓取点分类的性能。他们使用监督学习方法,并用标记的合成图像训练分类器。Pas等[Pas和Platt, 2015]首先使用几何必要条件采样一组高质量的抓取假设,然后使用对极抓取的概念对这些假设进行分类。Zapata-Impata等[Zapata-Impata等, 2019]提出了一种方法,在给定未知对象的部分单视图点云的情况下,找到最佳的抓取点对。他们定义了一个改进的排序指标[Zapata-Impata等, 2017]版本,用于评估一对接触点,该指标由正在使用的机器人手的形态参数化。
3D数据具有多种表示形式,如多视图图像、体素网格或点云,并且每种表示形式都可以使用相应的深度神经网络进行处理。这些不同类型的神经网络已经被应用于机器人抓取任务。GPD[ten Pas等, 2017]首先在感兴趣区域(ROI)上生成候选抓取。然后,将这些候选抓取编码为堆叠的多通道图像。最后,使用四层卷积神经网络对每个候选抓取进行评估以获得分数。Lou等[Lou等, 2019]提出了一种算法,该算法首先在整个3D空间中均匀采样以生成候选抓取,然后使用3D卷积神经网络(CNN)预测抓取稳定性,并结合候选抓取姿态使用抓取可达性,最后获得最终的抓取成功概率。PointnetGPD[Liang等, 2019a]随机采样候选抓取,并使用3D深度神经网络PointNet[Qi等, 2017a]通过直接点云分析来评估抓取质量。在训练数据集生成期间,通过结合力封闭指标和抓取力空间(GWS)分析[Kirkpatrick等, 1992]来评估抓取质量。Mousavian等[Mousavian等, 2019]提出了一种名为6-DoF Grasp Net的算法,该算法使用变分自动编码器采样抓取提议,并使用抓取评估器模型细化采样抓取。使用Pointnet++[Qi等, 2017b]生成和评估抓取。Murali等[Murali等, 2019]通过引入基于夹持器信息和场景原始点云的学习的碰撞检测器,进一步改进了6-DoF GraspNet,在杂乱场景中具有更高的成功率。
Qin等[Qin等, 2020]提出了一种名为S4G的算法,该算法利用使用Pointnet++[Qi等, 2017b]和合成数据训练的单次抓取提议网络,高效且有效地预测模态抓取提议。每个抓取提议都会进一步使用鲁棒性分数进行评估。S4G的核心新颖见解在于,它们通过回归来学习提出可能的抓取,而不是使用类似滑动窗口的风格。S4G直接生成抓取提议,而6-DoF GraspNet使用编码和解码方式。Ni等[Ni等, 2020]提出了Pointnet++Grasping,这也是一种端到端方法,可直接预测所有抓取的姿态、类别和分数。此外,Zhao等[Zhao等, 2020a]提出了一种名为REGNet的端到端单次抓取检测网络,该网络以单视图点云作为平行夹持器的输入。他们的网络包含三个阶段:得分网络(SN)用于选择具有高抓取置信度的正点,抓取区域网络(GRN)用于在选定的正点上生成一组抓取提议,以及细化网络(RN)用于基于局部抓取特征细化检测到的抓取。REGNet是3D空间中抓取检测的最先进方法,优于包括GPD[ten Pas等, 2017]、PointnetGPD[Liang等, 2019a]和S4G[Qin等, 2020]在内的几种方法。Fang等[Fang等, 2020]提出了一个名为GraspNet-1Billion的大规模抓取姿态检测数据集,其中包含97,280张RGB-D图像,超过10亿个抓取姿态。他们还提出了一种端到端的抓取姿态预测网络,该网络以解耦的方式学习接近方向和操作参数。
从已有抓取方式中迁移抓取方法
这类方法是从已有的抓取方式中迁移抓取方法,即如果知道它们属于同一类别,就需在观察到的单视角点云与已有的完整点云之间找到对应关系。在大多数情况下,目标物体与现有数据库中的物体并不完全相同。如果物体来自数据库中涉及的某一类别,则被视为相似物体。在对目标物体进行定位后,可利用基于对应关系的方法将相似且完整的3D物体的抓取点迁移到当前的部分视图物体上。由于当前目标物体与数据库中的物体并不完全相同,这些方法通过观察物体来学习抓取方式,而无需估计其6D姿态。
基于分类学、分割等不同方法被用来寻找对应关系。Andrew等人[Miller等人, 2003]提出了一种基于分类学的方法,该方法将物体分类为应由每种标准抓取方式抓取的类别。Nikandrova和Kyrki[Nikandrova和Kyrki, 2015]提出了一种针对特定任务中形状变化的物体的稳定抓取的概率方法。在概率背景下,考虑到形状的不确定性,最优抓取是指最有可能与任务兼容且稳定的抓取。他们的方法需要新物体的部分模型,并且在训练期间仅使用了少数模型和示例抓取。Vahrenkamp等人[Vahrenkamp等人, 2016]提出了一种基于部件的抓取规划方法,以生成适用于多个熟悉物体的抓取方式。根据物体的形状和体积信息对物体模型进行分割,并为物体部件贴上语义和抓取信息的标签。提出了一种抓取可迁移性度量来评估计划的抓取方式如何成功地应用于同一物体类别的新物体实例。Tian等人[Tian等人, 2019a]提出了一种方法,将抓取配置从先前的示例物体迁移到新物体,这假设新物体和示例物体具有相同的拓扑结构和相似的形状。他们考虑了几何和语义形状特征对物体进行3D分割,使用主动学习为每个示例物体的部分计算抓取空间,并为新物体的模型部分和相应抓取建立双射接触映射。Florence等人[Florence等人, 2018]提出了密集物体网络(Dense Object Nets),它建立在自监督密集描述符学习上,并将密集描述符作为机器人操作的表示。他们可以在可能变形的配置中抓取物体上的特定点,在杂乱环境中抓取具有实例特异性的物体,或在同一类别中的物体之间迁移特定抓取。Patten等人[Patten等人, 2020]提出了DGCM-Net,这是一种用于基于增量经验的机器人抓取的密集几何对应匹配网络。他们应用度量学习在特征空间中编码具有相似几何形状的附近物体,并通过最近邻搜索为未见物体检索相关经验。DGCM-Net还使用依赖于视图的归一化物体坐标空间来重建3D-3D对应关系,从而将检索样本的抓取配置转换到未见物体上。通过引导抓取选择到与物体功能使用相关的物体部分,他们的方法可扩展到语义抓取。
比较与讨论
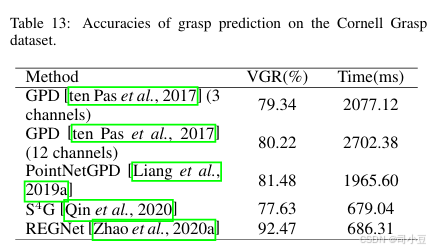
由于这是获得6D抓取姿态的直接方式,因此评估候选抓取的抓取质量的方法受到了广泛关注。针对6自由度抓取,二维平面抓取的评估指标并不适用。常用的指标是由REGNet[Zhao等人, 2020a]提出的有效抓取比率(Valid Grasp Ratio,VGR)。VGR定义为对跖且无碰撞抓取与所有抓取的比值。通常用于评估的抓取数据集是YCB-Video[Xiang等人, 2018]数据集。与近期方法的比较如表13所示。
从已有抓取方式中迁移抓取方法在高级机器人操作任务中具有潜在用途。不仅可以迁移抓取方式,还可以迁移操作技能。许多从示范中学习抓取的方法[Berscheid等人, 2019; Yang等人, 2019b]通常利用这类方法。
基于完整形状的方法
基于部分点云的方法适用于未知物体,因为这些方法没有可用的相同三维模型。针对已知物体,可以估计其六维姿态(6D poses),并且可以在完整三维形状上估计的六自由度(6DoF)抓取姿态可以从物体坐标系转换到相机坐标系。从另一个角度来看,相机坐标系下的三维完整物体形状也可以通过观察到的单视图点云来完成。并且,可以基于相机坐标系中的完整三维物体形状来估计六自由度抓取姿态。由于六自由度抓取姿态是基于完整物体形状来估计的,我们将这两种方法视为基于完整形状的方法。基于完整形状的六自由度抓取方法的典型功能流程图如图19所示。
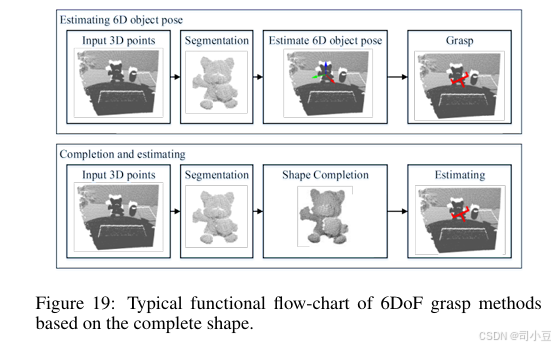
六维物体姿态估计方法
如第3节所述,如果目标物体是已知的,则可以从RGB-D数据中准确估计出六维物体姿态,并且可以通过离线预计算或在线生成来获得六自由度抓取姿态。这是抓取系统中最常用的方法。如果六自由度抓取姿态存在于数据库中,则可以从知识库中检索当前的六自由度抓取姿态,或者通过与现有抓取姿态进行比较来对它们进行采样和排序来获得。如果六自由度抓取姿态不存在于数据库中,则使用分析方法来计算抓取姿态。分析方法在确定抓取时考虑运动学和动力学公式[Sahbani等人,2012]。力封闭是完成抓取任务的主要条件之一,并且存在许多用于三维物体的力封闭抓取综合方法。其中,首先处理多面体物体,因为它们由有限数量的平面面组成。力封闭条件简化为面法线之间角度的测试[Nguyen,1987],或者使用线性模型来推导用于抓取表征的分析公式[Ponce等人,1993]。为了处理通常具有更复杂形状的常用物体,提出了观察不同接触点的方法[Ding等人,2001]。这些方法试图在三维物体表面上找到接触点,以确保力封闭,并根据预定义的抓取质量标准,通过最小化目标能量函数来计算最佳抓取[Mirtich和Canny,1994]。然而,搜索抓取解空间是一个复杂且非常耗时的问题。然后提出了一些启发式技术,通过根据预定程序生成一组抓取候选来减少搜索空间[Borst等人,2003],或通过定义一组规则来生成起始位置[Miller等人,2003]。一些机器人抓取模拟器,如GraspIt![Miller和Allen,2004],有助于生成最佳抓取器姿态以成功抓取。Andrew和Peter[Miller和Allen,2004]提出了GraspIt!,这是一个用于机器人抓取的通用模拟器。GraspIt!支持加载任意几何形状的物体和障碍物,以填充完整的模拟世界。它允许用户交互地操作机器人或物体,并在它们之间创建接触。Xue等人[Xue等人,2009]基于GraspIt!实现了一个抓取规划系统,以规划高质量的抓取。León等人[León等人,2010]提出了OpenGRASP,这是一个用于模拟抓取和灵巧操作的工具包。它提供了一个整体环境,可以处理与机器人抓取相关的各种因素。这些方法产生了成功的抓取,并且在调查[Sahbani等人,2012]中可以找到详细的评论。
传统和基于深度学习的六维物体姿态估计算法都被用来辅助机器人抓取任务。在亚马逊拣选挑战赛中提出的大多数方法[Zeng等人,2017b]首先利用部分配准估计的六维姿态。Zeng等人[Zeng等人,2017b]提出了一种方法,该方法使用全卷积神经网络对场景的多个视图进行分割和标记,然后将预扫描的三维物体模型拟合到分割结果上,以获得六维物体姿态。此外,Billings和Johnson-Roberson[Billings和Johnson Roberson,2018]提出了一种方法,该方法使用卷积神经网络(CNN)管道联合完成物体姿态估计和抓取点选择。Wong等人[Wong等人,2017]提出了一种方法,该方法集成了基于RGB的物体分割和基于深度图像的部分配准,以获得目标物体的姿态。他们提出了一种新的指标来评估模型配准质量,并进行了多假设配准,实现了1厘米位置误差和<5度角度误差的精确姿态估计。使用这种精确的六维物体姿态,抓取的成功率很高。一些基于深度学习的六维物体姿态估计方法,如DenseFusion[Wang等人,2019b],也证明了在实际机器人抓取任务中取得了很高的成功率。
形状补全方法
还存在一种方法,即对部分点云进行3D形状补全,然后估计抓取动作。3D形状补全可以从部分观测中提供物体的完整几何形状,在补全后的形状上估计6自由度(6DoF)抓取姿态会更加精确。这类方法中的大多数是从部分点云估计物体几何形状[Varley等人,2017;Lundell等人,2019;Van der Merwe等人,2019;Watkins-Valls等人,2019;Tosun等人,2020],而其他一些方法[Wang等人,2018a;Yan等人,2018a;Yan等人,2019;Gao和Tedrake,2019;Sajjan等人,2019]则利用RGB-D图像。其中许多方法[Wang等人,2018a;Watkins-Valls等人,2019]还结合了触觉信息以进行更好的预测。
Varley等人[Varley等人,2017]提出了一种架构,通过形状补全实现机器人抓取规划。他们利用3D卷积神经网络(CNN)来完成形状补全,并为不抓取的物体创建了快速网格,为要抓取的物体创建了详细网格。抓取动作最终在GraspIt![Miller和Allen,2004]中的重建网格上进行估计,并执行质量最高的抓取动作。Lundell等人[Lundell等人,2019]提出了一种形状补全深度神经网络(DNN)架构来捕捉形状不确定性,并提出了一种概率抓取规划方法,该方法利用形状不确定性来提出稳健的抓取动作。Merwe等人[Van der Merwe等人,2019]提出了PointSDF,以学习部分可见对象的符号距离函数隐式表面,并提出了一种抓取成功预测学习架构,该架构隐式地学习了几何感知点云编码。Watkins-Valls等人[Watkins-Valls等人,2019]还结合了深度和触觉信息来创建丰富且准确的3D模型,这些模型对机器人操作任务非常有用。他们同时利用深度和触觉信息作为输入,并将其直接输入到模型中,而不是使用触觉信息来精炼结果。Tosun等人[Tosun等人,2020]利用抓取建议网络和学习的3D形状重建网络,其中由第一个网络生成的候选抓取动作利用第二个网络的3D重建结果进行精炼。上述方法主要利用深度数据或点云作为输入。
Wang等人[Wang等人,2018a]通过结合视觉和触觉观测,以及从大规模形状存储库中学习到的常见物体形状的先验知识,来感知准确的3D物体形状。他们首先应用具有学习形状先验的神经网络,从单视图彩色图像预测物体的3D形状,并使用触觉感知来精炼形状。Yan等人[Yan等人,2018a]提出了一种深度几何感知抓取网络(DGGN),该网络首先从RGB-D输入中学习一个6DoF抓取动作。DGGN具有形状生成网络和结果预测网络。Yan等人[Yan等人,2019]进一步提出了一种自监督形状预测框架,该框架将完整的3D点云重构为机器人应用的表示形式。他们首先使用对象检测网络获取以对象为中心的颜色、深度和掩码图像,这些图像将用于生成检测到的对象的3D点云。然后使用一个抓取评估网络来预测抓取动作。Gao和Tedrake[Gao和Tedrake,2019]提出了一种新的混合对象表示方法,由语义关键点和密集几何形状(点云或网格)组成,作为感知模块和运动规划器之间的接口。利用基于学习的关键点检测和形状补全方面的进展,可以从原始传感器输入中感知到密集几何形状和关键点。Sajjan等人[Sajjan等人,2019]提出了ClearGrasp,这是一种深度学习方法,用于从单个RGB-D图像估计透明物体的准确3D几何形状,以便进行机器人操作。ClearGrasp使用深度卷积网络来推断表面法线、透明表面掩码和遮挡边界,这将精炼场景中所有透明表面的初始深度估计。
比较与讨论
当存在准确的3D模型时,可以获得物体的6D姿态,从而为目标物体生成抓取动作。然而,当现有的3D模型与目标物体不同时,6D姿态将产生较大偏差,这将导致抓取失败。在这种情况下,我们可以完成部分视图点云并通过三角剖分获得完整形状。可以在重构且完整的3D形状上生成抓取动作。开发了各种抓取模拟工具包来促进抓取动作的生成。针对估计物体6D姿态的方法,存在一些挑战。首先,这类方法高度依赖于物体分割的准确性。然而,训练一个支持广泛物体的网络并不容易。同时,这些方法要求待抓取的3D物体与注释模型足够相似,以便可以找到对应关系。对于通常会发生遮挡的杂乱环境中的物体,计算高质量的抓取点也颇具挑战性。针对形状补全方法,也存在一些挑战。信息的缺乏,尤其是相机相反方向的几何形状,极大地影响了补全的准确性。然而,使用多源数据将是未来的一个研究方向。
5 挑战与未来方向
在本综述中,我们从物体定位、物体姿态估计和抓取估计这三个关键方面回顾了基于视觉的机器人抓取的相关工作。本综述的目的是让读者了解在给定初始原始数据的情况下,如何检测成功的抓取操作,从而获得全面的认识。每节都介绍了各种细分方法以及相关的数据集和比较。与现有文献相比,我们提供了一个关于如何构建基于视觉的机器人抓取检测系统的端到端综述。
尽管已经提出了许多智能算法来辅助机器人抓取任务,但在实际应用中仍然存在挑战,如数据采集信息不足、训练数据量不足、抓取新物体的通用性不足以及抓取透明物体的困难。
第一个挑战是数据采集信息不足。目前,决定抓取操作的常用输入是从固定位置拍摄的一张RGB-D图像,它缺乏后方的信息。在没有物体完整几何形状的情况下,很难决定如何抓取。针对这一挑战,可以采取一些策略。第一种策略是利用多视图数据。更广泛视角的数据会更好,因为部分视图不足以全面了解目标物体。可以采用基于机械臂姿态的方法[Zeng等人,2017b;Blomqvist等人,2020]或SLAM方法[Dai等人,2017]来合并多视图数据。除了融合多视图数据外,还可以明确选择最佳的抓取视图[Morrison等人,2019]。第二种策略是引入多传感器数据,如触觉信息。已经有一些工作[Lee等人,2019;Falco等人,2019;Hogan等人,2020]引入了触觉数据来辅助机器人抓取任务。
第二个挑战是训练数据量不足。如果我们想构建一个足够智能的抓取检测系统,那么对训练数据的需求将非常大。公开的抓取数据集数量非常少,且涉及的物体大多是实例级别的,这与我们日常生活中的物体相比规模太小。针对这一挑战,可以采取一些策略。第一种策略是利用模拟环境生成虚拟数据[Tremblay等人,2018]。一旦建立了虚拟抓取环境,就可以通过模拟从不同角度的传感器来生成大量虚拟数据。由于模拟数据与实际数据之间存在差距,因此已经提出了许多域适应方法[Bousmalis等人,2018;Fang等人,2018;Zhao等人,2020b]。第二种策略是利用半监督学习方法[Mahajan等人,2020;Yokota等人,2020]来学习抓取,同时结合未标记数据。第三种策略是利用自监督学习方法为6D物体姿态估计[Deng等人,2020]或抓取检测[Suzuki等人,2020]生成标记数据。
第三个挑战是抓取新物体的通用性。上述抓取估计方法(除评估6D物体姿态的方法外)在处理新物体时都具有一定的通用性。但这些方法大多在训练数据集上表现良好,而在新物体上表现不佳。除了提高上述算法的性能外,还可以采取一些策略。第一种策略是利用类别级别的6D物体姿态估计。许多工作[Wang等人,2019c;Park等人,2020;Wang等人,2019a;Chen等人,2020a]开始处理类别级别物体的6D物体姿态估计,因为实例级别物体的高性能已经实现。第二种策略是在抓取检测系统中引入更多语义信息。借助各种形状分割方法[Yu等人,2019a;Luo等人,2020],可以使用物体的部分而不是完整形状来缩小候选抓取点的范围。还可以估计表面材料和重量信息,以获得更精确的抓取检测结果。
第四个挑战在于抓取透明物体。透明物体在我们的日常生活中很常见,但对于当今的深度传感器来说,捕获它们的3D信息相当困难。已经有一些开创性工作以不同的方式解决了这个问题。GlassLoc[Zhou等人,2019c]被提出用于在透明杂物中使用全光感知检测透明物体的抓取姿态。KeyPose[Liu等人,2020b]对透明物体进行了多视图3D标注和关键点估计,以估计其6D姿态。ClearGrasp[Sajjan等人,2019]从单张RGB-D图像中估计透明物体的准确3D几何形状,用于机器人操作。该领域将进行进一步研究,以使抓取在日常生活中更加准确和稳健。

















 1078
1078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









