






7.1 目标函数
我们可以使用任何模型将token序列映射到上下文嵌入中(例如, LSTM、Transformers):
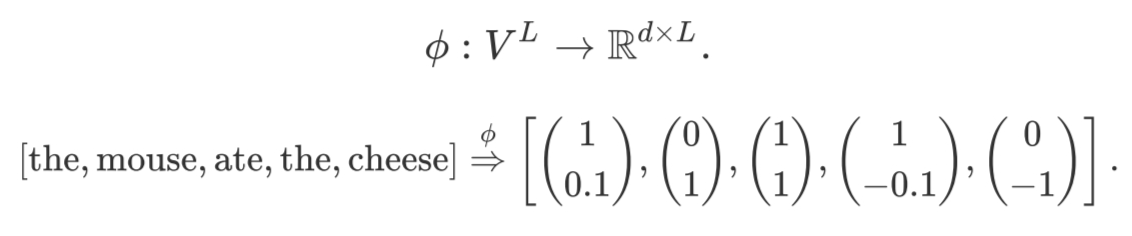
7.1.1 Decoder-only 模型
只包含解码器(Decoder-only)的模型(例如,GPT-3):自回归解码(根据自身解码,生成自身的内容)。主要面向文本生成任务。
例如给定一个句子包含4个单词 [A, B, C, D],GPT 需要利用 A 预测 B,利用 [A, B] 预测 C,利用 [A, B, C] 预测 D。预测方式如下:

7.1.1.1 最大似然
设是大型语言模型的所有参数。设D是由⼀组序列组成的训练数据。我们可以遵循最大似然原理,定义以下负对数似然损失目标函数:
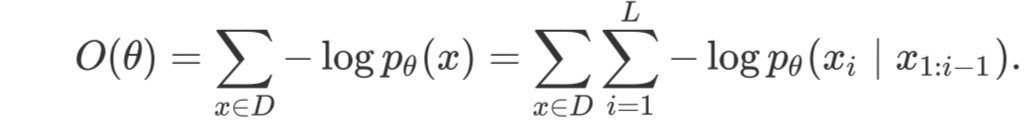
在机器学习中,我们通常希望模型的损失越小越好。我们的目标是要选择合适的参数θ使得这个函数的数值最小,损失最小。
7.1.2 Encoder-only 模型
只包含编码器(Encoder-only)的模型(例如,BERT):双向编码(根据上下文编码,填补内容)。对于Encoder-only的模型,预训练任务通常是“破坏一个句子,然后让模型去预测或填补”,并不生成文本。
7.1.2.1 BERT
Bert的训练是基于next-sentence prediction task和mask language modeling
1、next-sentence prediction task(下一句预测)是将原句子打乱成不同顺序的句子,让bert找出正确语序的原句,例如
- [CLS] Toast is a simple yet delicious food [SEP] It’s often served with butter, jam, or honey.
- [CLS] It’s often served with butter, jam, or honey. [SEP] Toast is a simple yet delicious food.
[CLS] 这一token是一个占位符标记,它提示模型返回一个 True 或 False 的标签,表示这两个句子是否按照正确的顺序排列。如果句子的顺序是正确的,模型应该返回 True,如果句子的顺序被打乱,模型应该返回 False。
[SEP] 这一token用来分割2个句子。
2、mask language modeling(掩码语言模型)则是在大量的文本语料库中将数据中的某部分遮住mask,让Bert根据上下文内容来预测mask的内容。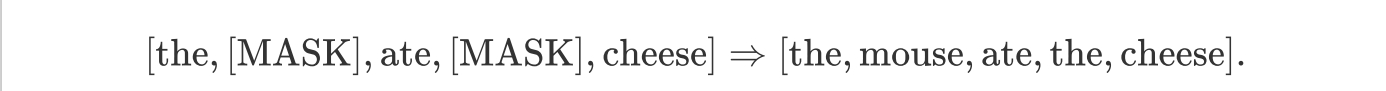
如上图把原句中15%的部分随机遮挡,遮挡的是“mouse”或“the”,80%的时间用[mask]token取代,10%的时间用随机token取代,10%的时间保持不变。
3、BERT的训练目标是:
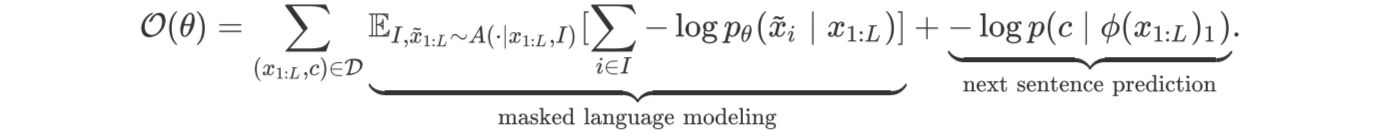
而数据集D按如下方式构建:

7.1.2.2 RoBERTa
RoBERTa对BERT进行了以下改进:

7.1.3 Encoder-decoder 模型
编码器解码器(Encoder-decoder)模型(例如,T5):既能自回归解码,又能双向编码。
7.1.3.1 BART
BART的结构在名字中已经体现得很明确了:就是一个BERT+GPT的结构。
BART主要训练过程如下:
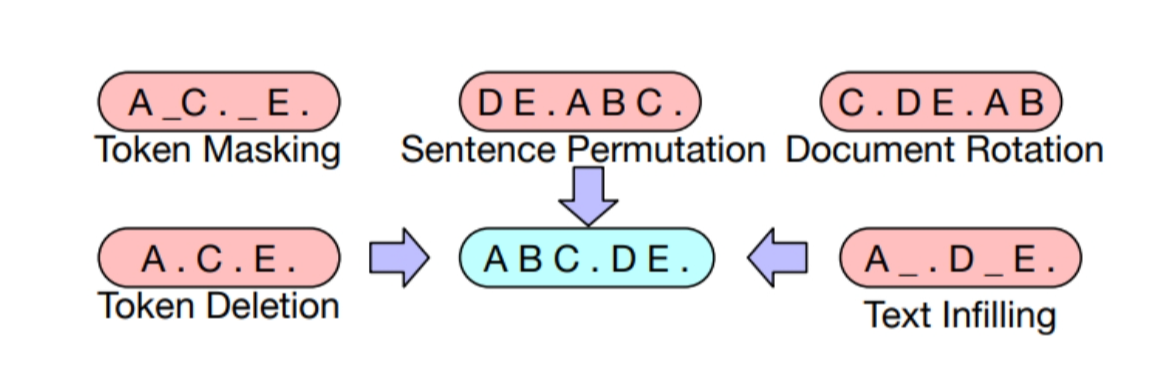

基于BERT的实验,最终模型进行了以下了变换:
- Mask文档中30%的token
- 将所有⼦句打乱
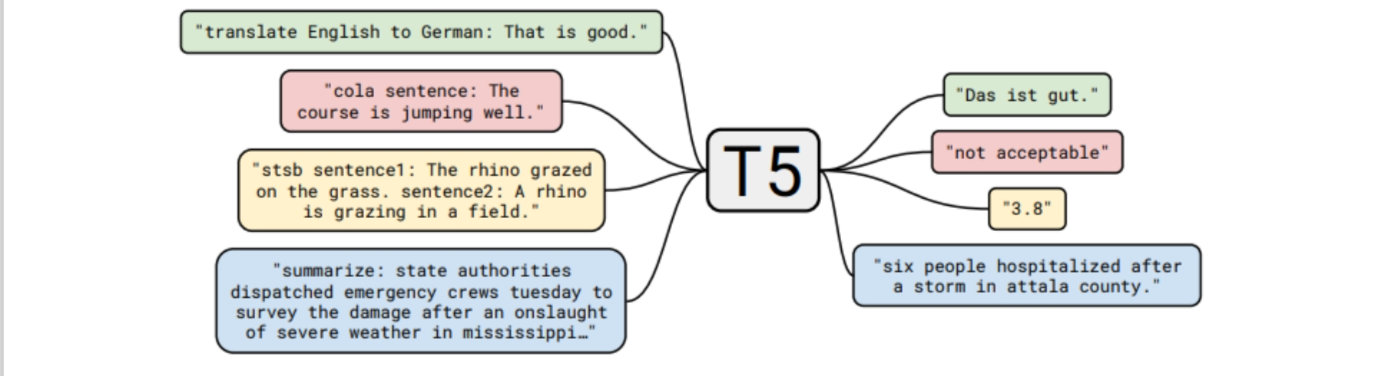
7.1.3.2 T5 (Text-to-Text Transfer Transformer)
T5的预训练任务: 给定⼀段文本,在随机位置将其分割为输入和输出。如下图:
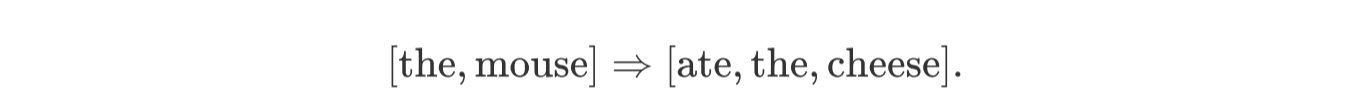
7.2 优化算法
我们以自回归语言模型为例,
7.2.1 随机梯度下降(SGD)
我们知道曲面上方向导数的最大值的方向就代表了梯度的方向,因此我们在做梯度下降的时候,应该是沿着梯度的反方向进行权重的更新,可以有效的找到全局的最优解。
最简单的优化算法是用小批量数据进行随机梯度下降,该算法的步骤如下:
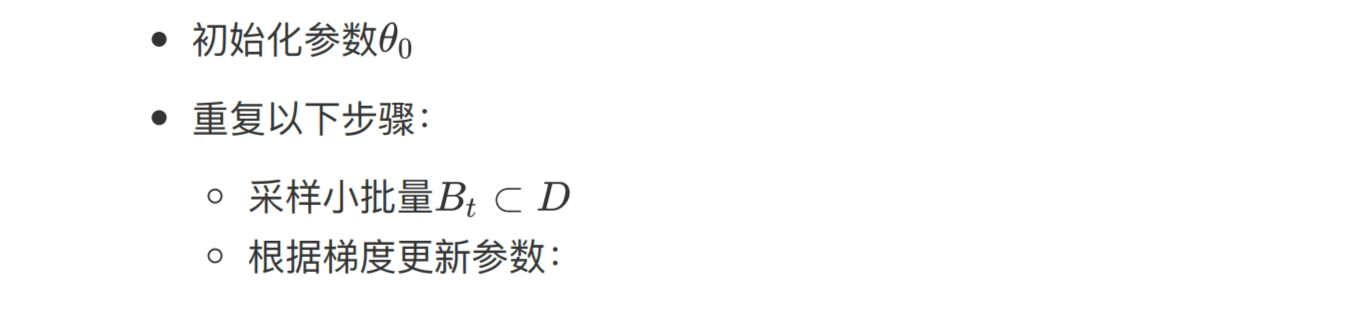
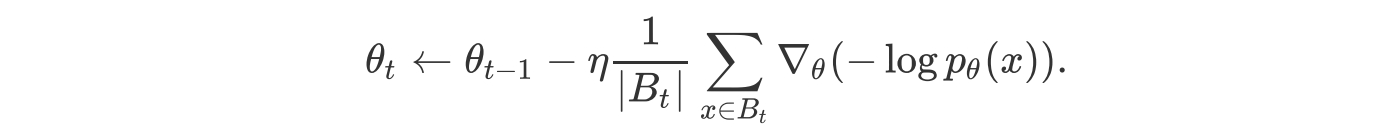
随机:用样本中一个例子来近似所有样本。
因为计算得到的并不是准确的一个梯度,对于最优化问题,凸问题,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的。
7.2.2 Adam (adaptive moment estimation)
Adam算法拥有以下两个创新:
- 引入动量(继续朝同一方向移动)
- 引入一阶、二阶矩的计算
在梯度下降的时候由于数据不同维度分布的方差不一致,而每次计算的梯度的方向是垂直于当前计算点的等高线的方向,可能会产生这种波动而导致收敛缓慢。如果设置过小的学习率能减少这种波动但这会导致模型收敛效率太慢。momentum概念的提出类似物理学上的(动量)的概念,也就是物体运动会趋向于保持于原来的运动状态。
该算法在创新的前提下重复随机梯度下降法。
7.2.3 AdaFactor
AdaFactor是⼀种为减少存储占用的优化算法。它有如下特点:

7.2.4 混合精度训练
混合精度训练是另⼀种减少存储的方法:

7.2.5 学习率
- 通常情况下,学习率会随着时间的推移而衰减。
- 对于Transformer模型,我们实际上需要通过预热(warmup) 提高学习率。
- ⼀个潜在的原因是防止层归⼀化的梯度消失,导致使用Adam优化器训练时不稳定。
7.2.6 初始化
















 3144
3144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









