






9.1 混合专家模型(MoE)
MoE 将预测建模任务分解为若干子任务,在每个子任务上训练一个专家模型(Expert Model),开发一个门控模型(Gating Model),门控模块用于选择使用哪个专家,组合各种专家。模型的实际输出为各个模型的输出与门控模型的权重组合。
各个专家模型可采用不同的函数(各种线性或非线性函数)。混合专家系统就是将多个模型整合到一个单独的任务中。
下图描述了MoE的基础架构:
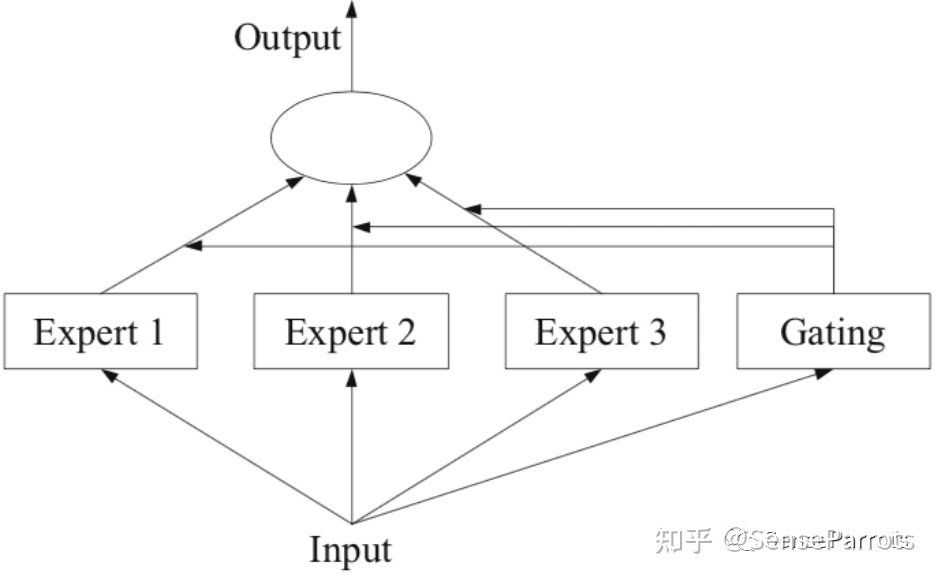
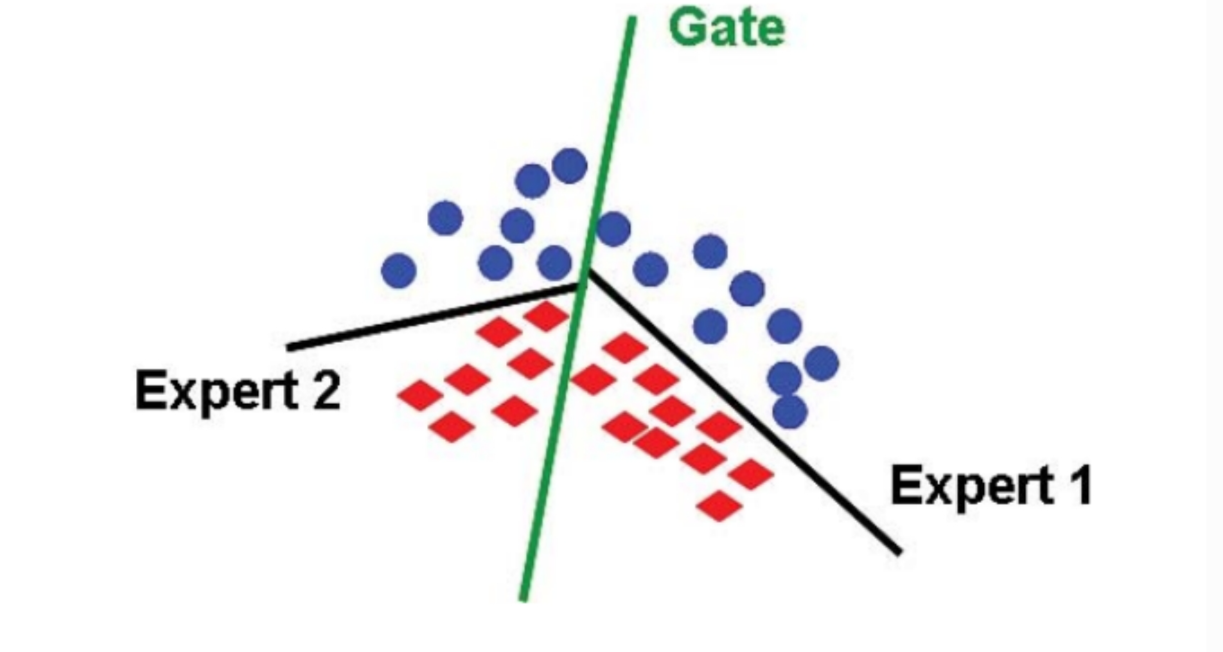
在 MoE 架构中,一组专家和一个门控相互合作,通过将输入空间划分为一组嵌套的区域来解决非线性监督学习问题,如下图所示。门控对整体输入空间进行软分割,专家模型在这些区域的分区中学习特定的参数。可以使用期望最大化 (Expectation Maximization, EM) 算法来学习专家模型和门控模型中的这些参数。
训练
我们可以通过反向传播(信号向前传播)结合最优化法(如梯度下降法)更新混合专家模型,使模型相邻两次迭代的误差很小。
节约计算
注意到,门控函数 对于每个专家都是非零的。例如:
正如公式所言,专家的混合不会节省任何计算,因为前向传播仍然需要评估每个专家,而反向传播也必须接触每个专家。 然而,如果我们将门控函数近似为
,其中大多数专家都是零。因此,在前向和反向传播时,我们只需要使用非零
的专家 。
例如,我们可以选取值排名前两位(top 2)的专家,并重新规范化:
平衡专家
- 只有所有专家都参与进来,混合专家才有效。
- 如果只有⼀个专家处于活跃状态(例如,
), 那么这就是浪费。
- 此外,如果我们⼀直处于这种状态,那么未使用的专家的梯度将为零,因此他们将不会收到任何梯度并得到改善。
- 因此,使用混合专家的主要考虑因素之⼀是确保所有专家都能被输入使用。
并行
- 混合专家非常有利于并行。
- 每个专家都可以放置在不同的机器上。
- 我们可以在中心节点计算近似门控函数
。
- 然后,我们只要求包含激活专家的机器(稀疏)来处理 。
9.1.1 Sparsely-gated mixture of experts(稀疏门控制的混合专家模型)
现在的模型越来越大,训练样本越来越多,每个样本都需要经过模型的全部计算,这就导致了训练成本的平方级增长。
为了解决这个问题,提出了一种方式,即将大模型拆分成多个小模型,对于一个样本来说,无需经过所有的小模型去计算,而只是激活一部分小模型进行计算,这样就节省了计算资源。
那么如何决定一个样本去经过哪些小模型呢?这就引入了一个稀疏门机制,即样本输入给这个门,得到要激活的小模型索引,这个门需要确保稀疏性,从而保证计算能力的优化。

也就是说,我们会尝试降低专家2的权重,避免其被过度使用,以节省计算资源。
9.1.2 Switch Transformer
定义近似门控函数只有一个专家(获得更多稀疏性)。
自然语言 MoE 层,它以 token 表征 x 为输入,然后将其发送给 top-k 专家。假设将 token 表征发送给 k>1 个专家是必要的,可以使 routing 函数具备有意义的梯度。他们认为如果没有对比至少两个专家的能力,则无法学习路由。
在MoE中,Switch Transformer只将 token 表征发送给单个专家。研究表明,这种简化策略保持了模型质量,降低了路由计算,并且性能更好。研究者将这种 k=1 的策略称为 Switch 层。
由于训练和推断过程中的路由决策,计算是动态的。鉴于此,一个重要的技术难题出现了:如何设置专家容量?
专家容量(每个专家计算的 token 数量)的计算方式为:每个批次的 token 数量除以专家数量,再乘以容量因子。如公式所示: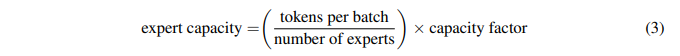 如果将太多 token 发送给一个专家,则会跳过计算,token 表征通过残差连接直接传递到下层。增加专家容量会导致数值太高将导致高计算和高内存的消耗。
如果将太多 token 发送给一个专家,则会跳过计算,token 表征通过残差连接直接传递到下层。增加专家容量会导致数值太高将导致高计算和高内存的消耗。
9.1.3 Balanced Assignment of Sparse Experts (BASE) layers
为大型语言模型引入了一个新的专家平衡分配(BASE)层,大大简化了现有的高容量稀疏层。稀疏层可以通过将每个token表征发送给特定的专家模型来极大地提高训练和推理的效率。
然而,要学习充分利用现有专家的平衡routing函数可能很困难;现有的方法通常使用routing启发式方法或辅助专家平衡损失函数。相比之下,我们将token到专家的分配表述为一个线性分配问题,最佳分配是允许每个专家收到相同数量的token。这种最优分配方案通过平衡的计算负载来提高效率,同时也不需要通过任何新的超参数或辅助损失来简化训练。
9.1.4 Generalist Language Model (GLaM)
使用更多数据、计算和参数扩展语言模型推动了自然语言处理的重大进展。例如,由于扩展,GPT-3 能够在上下文学习任务上取得出色的成果。但是,训练这些大型密集模型需要大量的计算资源。提出并开发了一个名为GLaM(通才语言模型)的语言模型家族,它使用稀疏激活的专家混合架构来扩展模型容量,同时与密集变体相比,训练成本也大大降低。最大的 GLaM 有 1.2 万亿个参数,大约是 GPT-7 的 3 倍。它仅消耗用于训练 GPT-3 的 1/3 的能量,并且需要一半的计算失败才能进行推理,同时在 29 个 NLP 任务中仍能实现更好的整体零镜头和单次性能。
9.2 基于检索的模型
现在,我们转向另⼀类语言模型,基于检索的(或检索增强的、记忆增强的模型),它可以帮助我们突破稠密Transformer的缩放上限。
9.2.1 Encorder-decorder模型
输入 :What is the capital of Canada?
输出 :Ottawa
9.2.2 检索方法
基于检索的模型直观的生成过程:
- 基于输入x ,检索相关序列z 。
- 给定检索序列z 和输入x ,生成输出y 。
示例:
输入 :What is the capital of Canada?
检索 :Ottawa is the capital city of Canada.
输出 :Ottawa
9.2.3 Retrieval-augmented generation (RAG)
RAG 是一种将信息检索与 seq2seq 生成器结合在一起的端到端可微模型。其中的信息检索系统是dense-passage retrieval system,seq2seq生成器则是使用BART模型。
从输入和输出看,RAG很像是一个标准的 seq2seq 模型。不过RAG还有一个中间步骤,RAG没有将输入直接传递给生成器,而是使用输入来检索一组相关文档。
比如输入问题是:“地球上第一个哺乳动物是什么时候出现的?”,RAG可能先用检索系统召回“哺乳动物”、“地球历史”和“哺乳动物的进化”相关文档。然后,这些文档作为上下文与原始输入拼接起来,再输入到seq2seq模型。
9.2.4 RETRO
该模型与 GPT-3 性能相当,但参数量仅为 GPT-3 的 4%。RETRO 整合了从数据库中检索到的信息,将其参数从昂贵的事实和世界知识存储中解放出来。















 2217
2217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









