






7.1 大模型之模型概括
当前大型语言模型的能力在于给定⼀个基于自身需求的prompt就可以生成符合需求的结果。
从数学角度考虑,大型语言模型的能力就是就对训练数据 (traingdata: ())的概 率分布。
7.2 分词
分词:将一个字符串拆分成多个词元(token)。
7.2.1 基于空格的分词
最简单的解决方案是使⽤ text.split(' ') 方式进行分词,这种分词方式对于英文这种按照空格,且每个分词后的单词有语义关系的文本是简单而直接的分词方式。
然而,对于一些语言,如中文,句子中的单词之间没有空格,如:我今天去了商店。
7.2.2 Byte Pair Encoding(BPE)
BPE是一种简单的数据压缩技术,它主要使用子词来编码数据。它用一个未使用的字节反复替换序列中最频繁的一对字节。这种算法用于分词。
首先需要分出子词,比如说单词“looked"和“looking”为训练语料,从语料中构建词表[l,o,o,k,e,d,i,n,g],然后“lo”出现频率最高,分成[lo,o,k,e,d,i,n,g],接下来“loo”出现频率最高,分成[loo,k,e,d,i,n,g],以此类推,最后被分成子词“look”、“ing”、“ed”。
其次根据子词长度,按长度排列,遍历词表,寻找属于给定单词的子词,合并在一起输出。
7.2.3 Unigram
- unigram 一元分词,把句子分成一个一个的汉字
- bigram 二元分词,把句子从头到尾每两个字组成一个词语
- trigram 三元分词,把句子从头到尾每三个字组成一个词语

Unigram Model是最简单的文本模型,认为一篇文档的生成过程是从一个词袋(bag of words)中不断取词的过程。
对于文档,用
表示此
的先验概率,生成文档w的概率为
![]()
7.3 模型构架
到目前为止,我们已经将语言模型定义为对词元(token)序列的概率分布。但在实践中,还是要避免生成整个序列。
Contextual Embedding:根据上下文嵌入。将词元序列与相应的上下文的向量表征。
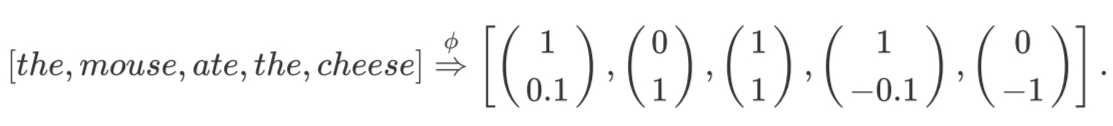
7.3.1 语言模型分类
7.3.1.1 编码端(Encoder-Only)架构
编码端架构的著名的模型如BERT、RoBERTa等。这些语言模型根据上下文进行内容嵌入,但不能直接生成文本。可以表示为:。编码端架构擅长对文本内容进行分析、分类。

该架构的优势是对于文本的上下文信息有更好的理解,因此该模型架构才会多用于理解任务。
7.3.1.2 解码端(Decoder-Only)架构
解码端架构的著名模型就是大名鼎鼎的GPT系列模型,主要是为了预测下一个输出的内容/token是什么,并把之前输出的内容/token作为上下文学习。实际上,Decoder-only模型在分析分类上也和Encoder-only的LLM一样有效。
7.3.1.3 编码-解码端(Encoder-Decoder)架构
编码-解码端架构就是最初的Transformer模型,其他的还有如 BART、T5等模型。既理解输入的内容NLU,又能处理并生成内容NLG,尤其擅长处理输入和输出序列之间存在复杂映射关系的任务,以及捕捉两个序列中元素之间关系至关重要的任务。

7.3.2 语言模型理论
7.3.2.1 递归神经网络(RNN)
第⼀个真正的序列模型是递归神经网络,它是⼀类模型, 包括简单的RNN、LSTM和GRU。
传统的神经网络(包括CNN),输入和输出都是相互独立的,例如一张图片的猫和狗是分隔开的,但是有些任务后续输出和之前的内容是相关的,局部的信息不足以使得后续的任务能够进行下去。RNN是需要之前或则之前序列的信息才能够使得任务进行下去的神经网络。
递归神经网络是空间上的展开,处理的是树/图结构的信息,模型结构如下:
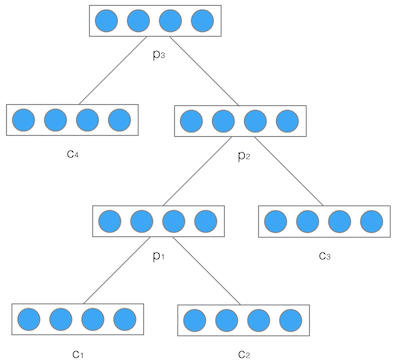
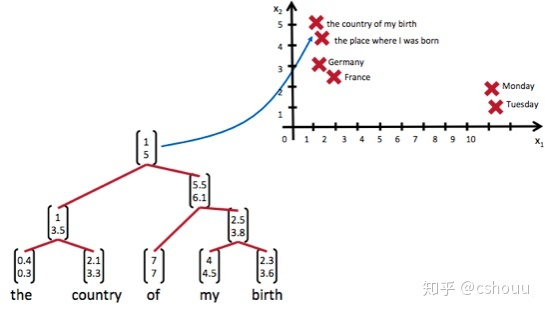
递归神经网络可以把一个树/图结构信息编码为一个向量,也就是把信息映射到一个语义向量空间中。这个语义向量空间满足某类性质,比如语义相似的向量距离更近。如果两句话(尽管内容不同)它的意思是相似的,那么把它们分别编码后的两个向量的距离也相近;反之,如果两句话的意思截然不同,那么编码后向量的距离则很远。如下图所示:
7.3.2.2 Transformer
Transformer是一个利用注意力机制来提高模型训练速度的模型。
注意力机制:当我们将Machine Learning翻译成机器学习的时候,希望Machine与“机器”关联度最大,而Learning与“学习”关联度更大。
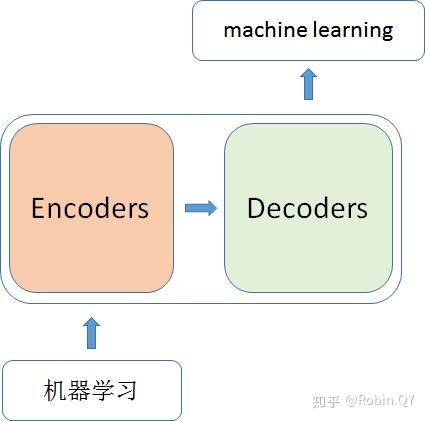
我们将transformer理解成一个黑盒子,黑盒子里就是encoder和decoder架构。
















 1089
1089











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









