







1.源码
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import numpy as np
# 导入线性回归模型
from sklearn.linear_model import LinearRegression # 线性回归模型用于预测一个或多个自变量与因变量之间的关系
# 打印标题,说明接下来是一个线性回归模型的训练例子
print("线性回归模型训练例子")
# 实例化一个线性回归模型对象
clf = LinearRegression()
# 使用三个样本点进行训练。这些点形成一条直线,所以线性回归模型可以完美地拟合它们
clf.fit([[0, 0], [1, 1], [2, 2]], [0, 1, 2]) # 训练数据,前两个列表是特征(x1, x2),第三个列表是目标值(y)
# 说明预期的线性方程,这里的注释仅用于说明,并非模型实际学到的方程
'''
y = 0.5*x1 + 0.5*x2 # 线性方程(预测模型),但这只是假设,实际模型可能会学到
不同的系数
'''
# 使用训练好的模型对新的数据点 [3, 3] 进行预测
pre = clf.predict([[3, 3]]) # 预测数据[3, 3]的 y 值
# 打印模型的回归系数和截距
print("回归系数", clf.coef_) # 回归系数表示每个特征对目标变量的影响程度
print("截距", clf.intercept_) # 截距表示当所有特征都为 0 时,目标变量的预测值
# 打印数据[3, 3]的预测值
print("数据[3, 3]的预测值:", pre)
print("*****************")
# 使用 make_classification 函数来生成一个模拟的二分类数据集
# 参数解释:
# n_samples=100: 生成的样本数量为 100
# n_features=2: 每个样本的特征数量为 2
# n_informative=2: 所有特征都是信息性的(即都与目标变量 y 相关)
# n_redundant=0: 没有冗余的特征(即与目标变量 y 无关的特征)
# random_state=42: 设置随机数生成器的种子,以确保每次运行代码时生成的数据集相同
X, y = make_classification(n_samples=100, n_features=2, n_informative=2,
n_redundant=0, random_state=42)
# 使用 train_test_split 函数来划分数据集
# 参数解释:
# X, y: 要划分的特征矩阵和目标变量数组
# test_size=0.2: 测试集占整个数据集的比例为 20%
# random_state=42: 设置随机数生成器的种子,以确保划分的结果相同
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=42)
# 创建一个逻辑回归模型的实例
# 参数解释:# solver='liblinear': 使用'liblinear'求解器来优化问题,它特别适合于小数据集
# random_state=42: 设置随机数生成器的种子,以确保模型训练的结果相同
clf = LogisticRegression(solver='liblinear', random_state=42)
# 使用训练集数据来拟合(训练)逻辑回归模型
# 参数解释:
# X_train, y_train: 训练集的特征矩阵和目标变量数组
clf.fit(X_train, y_train)
# 使用训练好的模型对测试集进行预测
# 参数解释:
# X_test: 测试集的特征矩阵
# 返回值:
# y_pred: 测试集上模型预测的目标变量数组
y_pred = clf.predict(X_test)
# 打印分类报告,该报告会展示模型的分类性能
print(classification_report(y_test, y_pred))
# 打印逻辑回归模型的系数(权重)
# 这些系数表示每个特征对模型预测结果的影响程度
print("回归系数(权重):", clf.coef_)
# 打印模型的截距
# 截距表示当所有特征都为 0 时,模型预测为正样本的概率的对数几率
print("截距:", clf.intercept_)
# 使用 predict_proba 方法获取测试集上每个样本属于各个类别的概率预测
# 对于二分类问题,这将返回两个概率值(对应于两个类别),它们的和应该接近 1
y_prob = clf.predict_proba(X_test)
print("预测概率:", y_prob)
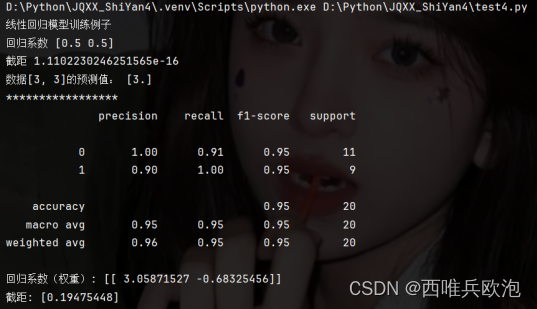
2. 运行结果


















 3091
3091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











