






由于涉及到一些信息安全等问题,尤其是公司内部文件或者体制内等,想要体验大模型带来的便捷,同时又可以规避掉数据泄漏的风险,这时候就可以考虑将一些大模型基于本地进行部署。这里就首推meta公司开源的ollama框架,可以快速对llm进行本地化部署。Ollama是一个用于在本地计算机上运行大型语言模型(LLMs)的命令行工具。它允许用户下载并本地运行像Llama 3、Code Llama等模型,并支持自定义和创建自己的模型。Ollama是免费开源的项目,支持macOS和Linux操作系统和Windows系统。它还提供了官方的Docker镜像,使用户可以通过Docker容器部署大型语言模型,确保所有与模型的交互都在本地进行,无需将私有数据发送到第三方服务。
官网下载页面:https://ollama.com/download
(1)基础使用
一些基本的常见大模型模型可以在https://ollama.com/library 中找到,以中文微调过的 Llama2-Chinese 7B 模型为例,下述命令会下载接近 4GB 的 4-bit 量化模型文件,需要至少 8GB 的内存进行推理,推荐配备 16GB 以流畅运行。
ollama pull llama2-chinese
下载完成后,使用 run 命令运行模型,可直接将消息附在命令后,或留空进入对话模式,对话模式内置了几个以斜杠引出的命令:
ollama run llama2-chinese "你是谁"
值得一提的是,Ollama 会判别正在运行的硬件并在可行的情况下调用 GPU 加速,不妨在推理时打开活动监视器或任务管理器观察以验证。到此,你已经体验到触手可及的本地大模型了。总结一下ollama常用的基础操作:
1.运行模型 ollama run
2.创建模型 ollama create -f
Modelfile示例:
# 模型来自于哪个基础模型`` ``FROM llama3``# 设置创造力参数,1表示更高的创造性,较低则表示更加连贯``PARAMETER temperature 1`` ``# prompt``SYSTEM """ You are Mario from Super Mario Bros. Answer as Mario, the assistant, only. """
3.查看有哪些模型 ollama list
4.删除模型 ollama rm
(2)进阶玩法
若是觉得命令行的形式不够易用,Ollama 有一系列的周边工具可供使用,包含了网页、桌面、终端等交互界面及诸多插件和拓展。之所以 Ollama 能快速形成如此丰富的生态,是因为它自立项之初就有清晰的定位:让更多人以最简单快速的方式在本地把大模型跑起来。于是,Ollama 不是简单地封装 llama.cpp,而是同时将繁多的参数与对应的模型打包放入;Ollama 因此约等于一个简洁的命令行工具和一个稳定的服务端 API。这为下游应用和拓展提供了极大便利。就 Ollama GUI 而言,根据不同偏好,有许多选择:
-
Web 版:Ollama WebUI 具有最接近 ChatGPT 的界面和最丰富的功能特性,需要以 Docker 部署;
-
终端 TUI 版:oterm 提供了完善的功能和快捷键支持,用 brew 或 pip 安装;
-
此外,llm-anything或者open-webui以及还有 Swift 编写的 macOS 原生应用 Ollamac、类似于 Notion AI 的 Obsidian Ollama 等有趣应用,可按需选用。
(3)高级玩法
–切换更高级别支持的模型
Ollama 采取了与 Docker 组织镜像相似的方案,使用模型名加上标签的形式( model:tag )来确定具体的模型版本,不加标签时默认为 latest ,通常对应 7B 参数量 4bit 量化版。而如果要运行 13B 版本,就可以使用 13b 标签,此外,还可以换用其他模型。在此,但官方模型库里对中文支持相对较好的不多,比如qwen系列等。
–支持图像
除了纯语言大模型,Ollama 自 0.1.15 版本开始提供支持的视觉模型也值得一玩。将本地图片的路径写在 prompt 里即可(macOS 用户可以直接将图片拖入终端来获得其路径):
% ollama run llava`` ``>>> What does the text in this image say? xx.png` ` ``Added image 'xx.png'`` ``The text in this image says "The Ollamas."
–自定义系统提示词
根据 ChatGPT 的使用经验,多数人都已知晓系统提示词的重要性。好的系统提示词能有效地将大模型定制成自己需要的状态。在 Ollama 中,有多种方法可以自定义系统提示词。首先,不少 Ollama 前端已提供系统提示词的配置入口,推荐直接利用其功能。此外,这些前端在底层往往是通过 API 与 Ollama 服务端交互的,我们也可以直接调用,并传入系统提示词选项:
curl http://localhost:11434/api/chat -d '{` `"model": "llama2-chinese:13b",` `"messages": [` `{` `"role": "system",` `"content": "以老师的口吻简单作答。"` `},` `{` `"role": "user",` `"content": "天空为什么是蓝色的?"` `}` `],` `"stream": false``}'
其中 role 为 system 的消息即为系统提示词。
–其他设置
Ollama 的 ModelFile 给用户留下了更多自定义的空间,基于ollama modelfile功能,构建自己的ollama模型,modelefile的原理和写法都和Dockerfile类似,除了系统提示词,包括对话模板、模型推理温度、上下文窗口长度等参数均可自行设置,适合进阶使用。在创建前,通过 ollama show --modelfile xx命令可以查看现有模型的 ModelFile 内容作为参考:
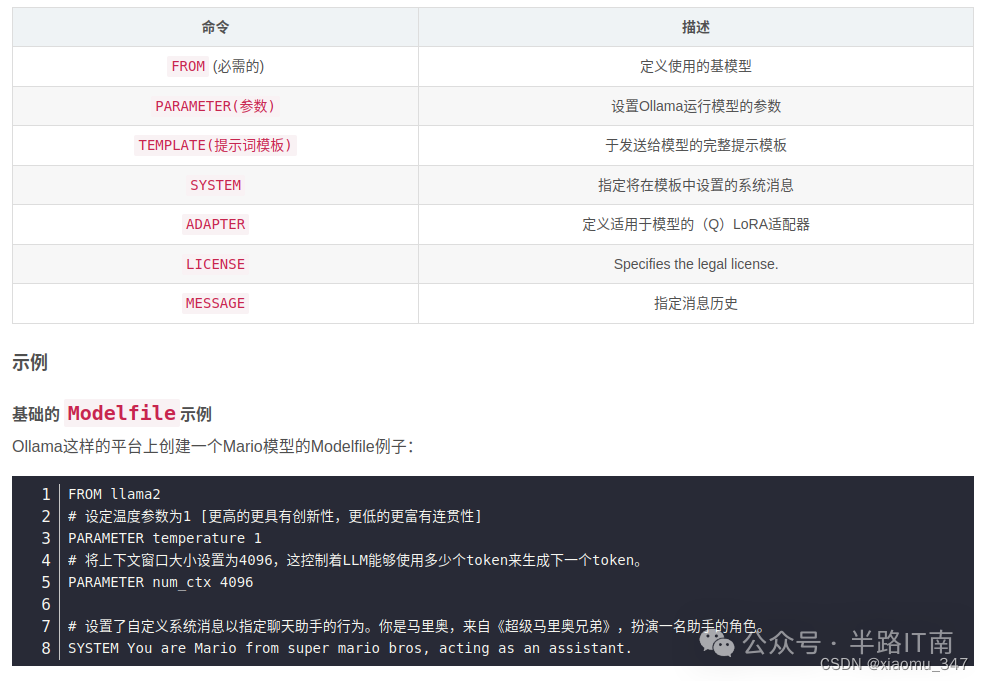
对于自定义modelfile可以参考官方链接ollama/docs/modelfile.md at main · ollama/ollama · GitHub,以自定义系统提示词并修改推理温度参数(流畅关联度)为例,应构建如下格式的 ModelFile,下面我会演示如何基于模型的System Message能力,使用ollama modelfile构建以女朋友口吻的一个Chatbot,需注意在Modelfile中是不会区分字母大小写的
FROM llama2-chinese:13b``SYSTEM "以可爱风格和萌萌哒的女朋友口吻作答。"``PARAMETER temperature 0.1
然后使用 create 命令进行创建,新的模型会沿用原有模型的权重文件和未作调整的选项参数:
ollama create llama2-chinese-pirate -f ~/path/to/ModelFile
这时候你就可以收获一个回答偏可爱萌萌哒风格的大模型了,当然它的性能还是主要依赖你的基准模型,如果想要效果更佳则需要对模型进行finetune,这个会安排在后面章节。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓















 7145
7145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









