






1. 直接通过sklearn库进行数据导入
from sklearn.datasets import load_boston
这种方法在比较新的版本中会被移除掉,下图是1.2.2的sklearn作为演示,导入失败:
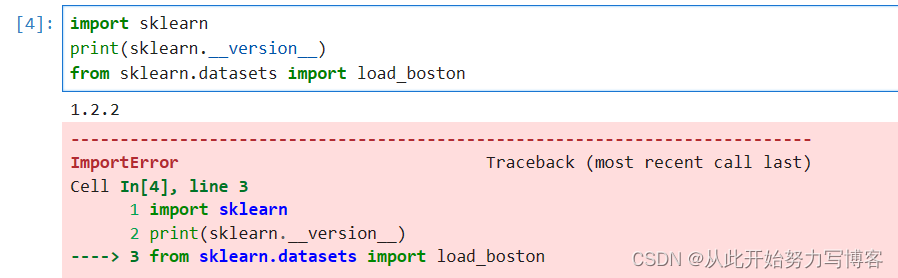
可通过使用旧版python解释器来导入,下图是python3.6,,sklearn版本是0.24.1,成功导入:

2.导入函数 fetch_openml
from sklearn.datasets import fetch_openml
boston = fetch_openml(name="boston", version=1, as_frame=True)
boston['data']
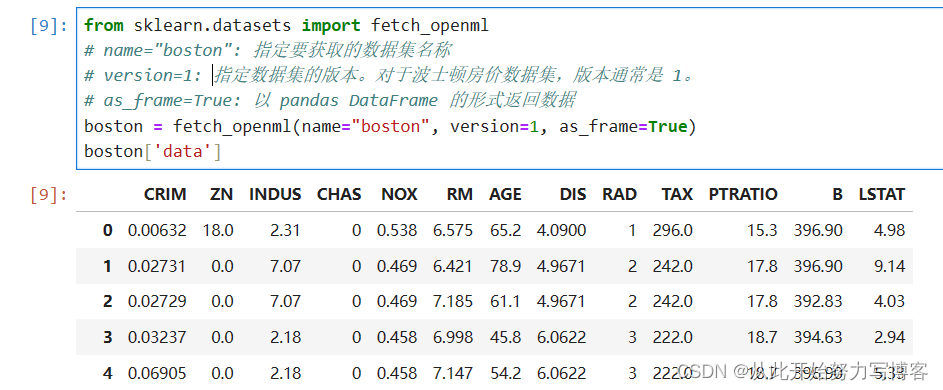
3.通过pandas导入
从第一种方法的报错中找到数据的地址:
data_url = “http://lib.stat.cmu.edu/datasets/boston”
import pandas as pd
import numpy as np
data_url = "http://lib.stat.cmu.edu/datasets/boston"
# 通过sep指定空格作为分隔符
# skiprows = 22 表示跳过前22行
# header=None表示不将第一行作为列名
raw_df = pd.read_csv(data_url, sep='\s+', skiprows=22, header=None)
# 将原始数据转换为Numpy数组
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
# 提取目标值
target = raw_df.values[1::2, 2]
data


















 1198
1198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









