






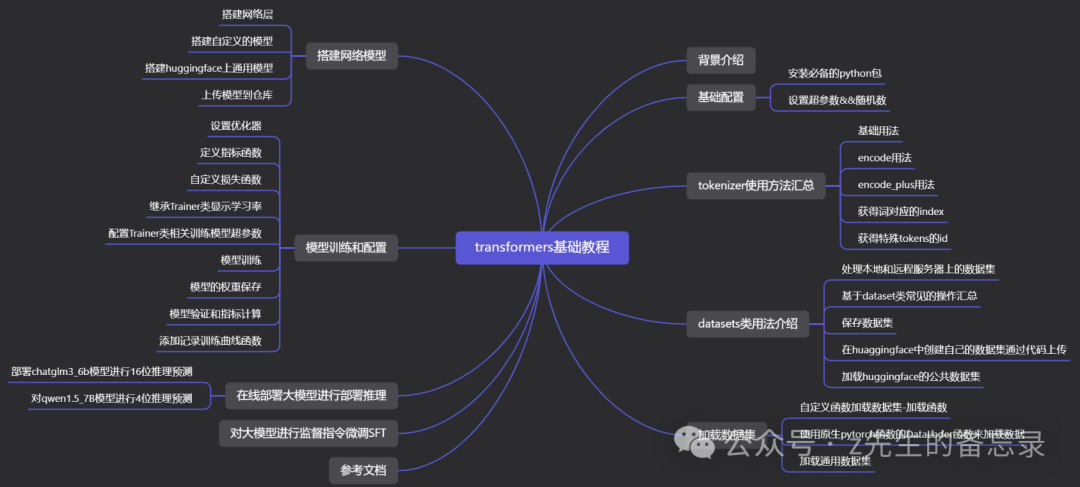
本文目录
基础配置
安装必备的python包
!pip install transformers datasets seqeval sacrebleu evaluate accelerate==0.19.0 sentencepiece loralib peft import transformers import torch import datasets import peft print("transformers vision: %s"%(transformers.__version__)) # transformers vision:4.29.2 print("torch vision: %s"%(torch.__version__)) # torch vision: 1.13.0 print(f"Accelerate version: {accelerate.__version__}") # Accelerate version: 0.19.0 print("datasets version: %s"%(datasets.__version__)) # datasets version: 2.1.0 print(f"PEFT version: {peft.__version__}") # peft version: 0.3.0
设置超参数&&随机数
import os import gc import ctypes import torch import random import numpy as np os.environ['WANDB_DISABLED'] = 'true' os.environ["TOKENIZERS_PARALLELISM"] = "false" # 释放不必要的显存和内存 def clean_memory(): gc.collect() ctypes.CDLL("libc.so.6").malloc_trim(0) torch.cuda.empty_cache() from huggingface_hub import login login(token= 'your_token') import wandb wandb.login(key= 'your_key') wandb.init(project="trl_imdb_positive") def seed_everything(seed): random.seed(seed) os.environ['PYTHONHASHSEED'] = str(seed) np.random.seed(seed) torch.manual_seed(seed) if torch.cuda.is_available(): torch.cuda.manual_seed(seed) torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = True torch.backends.cudnn.enabled = True # 自定义超参数 class Args: model_path = "hfl/chinese-bert-wwm-ext" max_seq_len = 128 ratio = 0.8 device = torch.device("cuda" if torch.cuda.is_available else "cpu") train_batch_size = 32 dev_batch_size = 32 weight_decay = 0.01 epochs = 1 learning_rate = 3e-5 eval_step = 100 prompt = "情感是[MASK][MASK]。" seed = 2024 args = Args() seed_everything(args.seed)
tokenizer使用方法汇总
基础用法
from transformers import BertForMaskedLM, BertTokenizer, BertForSequenceClassification, BertConfig, AdamW from transformers import pipeline tokenizer = BertTokenizer.from_pretrained(args.model_path) sentence = "It is a very beautiful book." tokens=tokenizer.tokenize(sentence) print(tokens) # ['it', 'is', 'a', 'very', 'beautiful', 'book', '.'] tokenizer.convert_tokens_to_ids(tokens) #[8233, 8310, 143, 11785, 13106, 9106, 119]
encode用法
token_samples_c=tokenizer.encode(text=sentence,add_special_tokens=True) token_samples_c # [101, 8233, 8310, 143, 11785, 13106, 9106, 119, 102] print(tokenizer.all_special_ids,tokenizer.all_special_tokens) #[100, 102, 0, 101, 103], ['[UNK]', '[SEP]', '[PAD]', '[CLS]', '[MASK]']
encode_plus用法
token_samples_d=tokenizer.encode_plus(text=sentence,max_length=15,return_tensors='pt',add_special_tokens=True, padding="max_length", truncation="longest_first", return_attention_mask=True, return_token_type_ids=True )#方式4 返回一个字典,包含id,type,mask,无须手动添加CLS与SEP,可以指定返回类型与长度,add_special_tokens默认为True token_samples_d # {'input_ids': tensor([[ 101, 8233, 8310, 143, 11785, 13106, 9106, 119, 102, 0, # 0, 0, 0, 0, 0]]), # 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), # 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0]])}
获得词对应的index
vocab = tokenizer.vocab#查看词典 label2ind = {} for label_name in label2id: zz=[vocab[label] for label in label_name] label2ind[label_name]=zz print(label2ind) # {'故事': [3125, 752], '文化': [3152, 1265], '娱乐': [2031, 727], '体育': [860, 5509], '财经': [6568, 5307], '房产': [2791, 772], # '汽车': [3749, 6756], '教育': [3136, 5509], '科技': [4906, 2825], '军事': [1092, 752], '旅游': [3180, 3952], '国际': [1744, 7354], # '股票': [5500, 4873], '三农': [676, 1093], '游戏': [3952, 2767]}
获得特殊tokens的id
print(tokenizer.unk_token, tokenizer.convert_tokens_to_ids(tokenizer.unk_token))# [UNK] 100 print(tokenizer.sep_token, tokenizer.convert_tokens_to_ids(tokenizer.sep_token))# [SEP] 102 print(tokenizer.pad_token, tokenizer.convert_tokens_to_ids(tokenizer.pad_token))# [PAD] 0 print(tokenizer.cls_token, tokenizer.convert_tokens_to_ids(tokenizer.cls_token))# [CLS] 101 print(tokenizer.mask_token, tokenizer.convert_tokens_to_ids(tokenizer.mask_token)) # [MASK] 103 print(tokenizer.all_special_ids)#打印special_ids # [100, 102, 0, 101, 103] print(tokenizer.all_special_tokens)#打印special_tokens # ['[UNK]', '[SEP]', '[PAD]', '[CLS]', '[MASK]']
datasets类用法介绍
处理本地和远程服务器上的数据集
## 处理本地数据 !wget https://github.com/crux82/squad-it/raw/master/SQuAD_it-train.json.gz !wget https://github.com/crux82/squad-it/raw/master/SQuAD_it-test.json.gz !gzip -dkv SQuAD_it-*.json.gz data_files = {"train": "SQuAD_it-train.json", "test": "SQuAD_it-test.json"} squad_it_dataset = load_dataset("json", data_files=data_files, field="data") squad_it_dataset ## 处理线上数据 url = "https://github.com/crux82/squad-it/raw/master/" data_files = { "train": url + "SQuAD_it-train.json.gz", "test": url + "SQuAD_it-test.json.gz", } squad_it_dataset = load_dataset("json", data_files=data_files, field="data") squad_it_dataset !wget "https://archive.ics.uci.edu/ml/machine-learning-databases/00462/drugsCom_raw.zip" !unzip drugsCom_raw.zip from datasets import load_dataset data_files = {"train": "drugsComTrain_raw.tsv", "test": "drugsComTest_raw.tsv"} # \t is the tab character in Python drug_dataset = load_dataset("csv", data_files=data_files, delimiter="\t") drug_dataset
基于dataset类常见的操作汇总
`## 查看明细 drug_sample = drug_dataset["train"].shuffle(seed=42).select(range(1000)) drug_sample[:3] ## 重命名列 drug_dataset = drug_dataset.rename_column( original_column_name="Unnamed: 0", new_column_name="patient_id") drug_dataset ## filter和map函数 def lowercase_condition(example): return {"condition": example["condition"].lower()} drug_dataset = drug_dataset.filter(lambda x: x["condition"] is not None) ## 过滤为空的值 drug_dataset = drug_dataset.map(lowercase_condition) ## 创建新列 def compute_review_length(example): return {"review_length": len(example["review"].split())} drug_dataset = drug_dataset.map(compute_review_length) ## sort函数 drug_dataset["train"].sort("review_length")[:3] drug_dataset = drug_dataset.filter(lambda x: x["review_length"] > 30) print(drug_dataset.num_rows, drug_dataset.num_columns) # DatasetDict({ # train: Dataset({ # features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length'], # num_rows: 138514 # }) # test: Dataset({ # features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length'], # num_rows: 46108 # }) # }) import html ## 性能加速 new_drug_dataset = drug_dataset.map(lambda x: {"review": [html.unescape(o) for o in x["review"]]}, batched=True) new_drug_dataset = drug_dataset.map(lambda x: {"review": [html.unescape(o) for o in x["review"]]}, batched=True, num_proc=4)) ## 移除多余的列 def tokenize_and_split(examples): return tokenizer( examples["review"], truncation=True, max_length=128, return_overflowing_tokens=True, ) tokenized_dataset = drug_dataset.map( tokenize_and_split, batched=True, remove_columns=drug_dataset["train"].column_names ) tokenized_dataset ## 数据集划分 drug_dataset_clean = drug_dataset["train"].train_test_split(train_size=0.8, seed=42) drug_dataset_clean["validation"] = drug_dataset_clean.pop("test") # Add the "test" set to our `DatasetDict` drug_dataset_clean["test"] = drug_dataset["test"] drug_dataset_clean `
保存数据集
drug_dataset_clean.save_to_disk("drug-reviews") ## .to_csv() , to_json() from datasets import load_from_disk drug_dataset_reloaded = load_from_disk("drug-reviews")
在huaggingface中创建自己的数据集通过代码上传
from huggingface_hub import list_datasets all_datasets = list_datasets() from huggingface_hub import login login(token=your_token) from huggingface_hub import create_repo repo_url = create_repo(name="github-issues", repo_type="dataset") from huggingface_hub import Repository repo = Repository(local_dir="github-issues", clone_from=repo_url) !cp issues-datasets-with-hf-doc-builder.jsonl github-issues/ ## issues-datasets-with-hf-doc-builder.jsonl 需要上传的数据 repo.lfs_track("*.jsonl") repo.push_to_hub()
加载huggingface的公共数据集
remote_dataset = load_dataset("lewtun/github-issues", split="train") remote_dataset ## 加载公共数据集 from huggingface_hub import hf_hub_url from datasets import load_dataset data_files = hf_hub_url( repo_id="lewtun/github-issues", filename="datasets-issues-with-hf-doc-builder.jsonl", repo_type="dataset", ) issues_dataset = load_dataset("json", data_files=data_files, split="train") ## 保持文本向量 def get_embeddings(text_list): encoded_input = tokenizer( text_list, padding=True, truncation=True, return_tensors="pt" ) encoded_input = {k: v.to(device) for k, v in encoded_input.items()} model_output = model(**encoded_input) return cls_pooling(model_output) embedding = get_embeddings(comments_dataset["text"][0]) embedding.shape ##torch.Size([1, 768]) embeddings_dataset = comments_dataset.map( lambda x: {"embeddings": get_embeddings(x["text"]).detach().cpu().numpy()[0]} ) embeddings_dataset.add_faiss_index(column="embeddings")
加载数据集
自定义函数加载数据集-加载函数
def load_data(data, prompt, max_seq_len): return_data = [] # [(文本, 标签id)] for d in data: text = d[0] label = d[1] text = "".join(text.split(" ")).strip() +"," +prompt if len(text) > max_seq_len - 2: continue return_data.append((text, label)) return return_data class Collate: def __init__(self, tokenizer, max_seq_len): self.tokenizer = tokenizer self.max_seq_len = max_seq_len def collate_fn(self, batch): input_ids_all = [] token_type_ids_all = [] attention_mask_all = [] label_all = [] mask_pos_all = [] for data in batch: text = data[0] label = data[1] inputs = self.tokenizer.encode_plus(text=text, max_length=self.max_seq_len, padding="max_length", truncation="longest_first", return_attention_mask=True, return_token_type_ids=True) input_ids = inputs["input_ids"] mask_pos = [i for i, token_id in enumerate(input_ids) if token_id == self.tokenizer.convert_tokens_to_ids(self.tokenizer.mask_token)] mask_pos_all.append(mask_pos) token_type_ids = inputs["token_type_ids"] attention_mask = inputs["attention_mask"] input_ids_all.append(input_ids) token_type_ids_all.append(token_type_ids) attention_mask_all.append(attention_mask) label_all.append(label) input_ids_all = torch.tensor(input_ids_all, dtype=torch.long) token_type_ids_all = torch.tensor(token_type_ids_all, dtype=torch.long) attention_mask_all = torch.tensor(attention_mask_all, dtype=torch.long) mask_pos_all = torch.tensor(mask_pos_all, dtype=torch.long) label_all = torch.tensor(label_all, dtype=torch.long) return_data = { "input_ids": input_ids_all, "attention_mask": attention_mask_all, "token_type_ids": token_type_ids_all, "label": label_all, "mask_pos": mask_pos_all, } return return_data
使用原生pytorch函数的DataLoder函数来加载数据
collate = Collate(tokenizer, args.max_seq_len) train_loader = DataLoader(train_data, batch_size=args.train_batch_size, shuffle=True, num_workers=2, collate_fn=collate.collate_fn) total_step = len(train_loader) * args.epochs args.total_step = total_step dev_loader = DataLoader(dev_data, batch_size=args.dev_batch_size, shuffle=False, num_workers=2, collate_fn=collate.collate_fn) test_loader = dev_loader for step, batch_data in enumerate(train_loader): label = batch_data["label"] batch_size = label.size(0) input_ids = batch_data["input_ids"] mask_pos = batch_data["mask_pos"] token_type_ids = batch_data["token_type_ids"] attention_mask = batch_data["attention_mask"] print(input_ids[:2]) print(mask_pos[:2]) break # tensor([[ 101, 6206, 5440, 6407, 1044, 4312, 3614, 8043, 5739, 1744, 1187, 3441, # 8188, 2399, 837, 5320, 8024, 2110, 4495, 812, 9126, 8024, 6662, 782, # 679, 4007, 117, 712, 7579, 3221, 103, 103, 511, 102, 0, 0, # 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, # 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, # 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, # 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, # 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, # 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, # 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, # 0, 0, 0, 0, 0, 0, 0, 0], # [ 101, 872, 6371, 711, 686, 4518, 677, 1525, 702, 1062, 1385, 3297, # 1326, 2154, 8043, 117, 712, 7579, 3221, 103, 103, 511, 102, 0, # 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, # 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, # 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, # 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, # 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, # 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, # 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, # 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, # 0, 0, 0, 0, 0, 0, 0, 0]]) # tensor([[30, 31], # [19, 20]])
加载通用数据集
from sklearn.model_selection import StratifiedKFold from sklearn.model_selection import train_test_split from datasets import Dataset, DatasetDict test = Dataset.from_pandas(test) disaster_tweets_test = DatasetDict() disaster_tweets_test['test'] = test data_y = train['labels'] data_x = train.drop(columns='labels') def get_train_val_test(df_train,df_val): tds = Dataset.from_pandas(df_train) vds = Dataset.from_pandas(df_val) disaster_tweets = DatasetDict() disaster_tweets['train'] = tds disaster_tweets['validation'] = vds return disaster_tweets from transformers import AutoTokenizer from transformers import ElectraTokenizer, ElectraForSequenceClassification,AdamW import torch max_length = 40 # 98(key+local+text) # model_ckpt ='bert-large-uncased'#'microsoft/deberta-v3-large' #'microsoft/deberta-v3-base'#'microsoft/deberta-v3-large'# 'microsoft/deberta-v3-base'#'xlm-roberta-base' tokenizer = AutoTokenizer.from_pretrained(model_ckpt)# 'xlm-roberta-base') # tokenizer = ElectraTokenizer.from_pretrained('google/electra-base-discriminator') def tokenize(batch): return tokenizer(batch['text'], max_length=max_length,padding=True, truncation=True) #batch['keyword'], disaster_tweets_test_encoded = disaster_tweets_test.map(tokenize, batched=True, batch_size=None) from sklearn.model_selection import StratifiedKFold Fold = StratifiedKFold(n_splits=n_fold, shuffle=True, random_state=seed_val) for n, (train_index, val_index) in enumerate(Fold.split(data_x, data_y)): train_pf = data_x.iloc[train_index,:] train_pf['label'] = data_y.iloc[train_index] val_pf = data_x.iloc[val_index,:] val_pf['label'] = data_y.iloc[val_index] disaster_tweets= get_train_val_test(train_pf,val_pf) disaster_tweets_encoded = disaster_tweets.map(tokenize, batched=True, batch_size=None)
搭建网络模型
搭建网络层
class multilabel_dropout(nn.Module): # Multisample Dropout 论文: https://arxiv.org/abs/1905.09788 def __init__(self, hidden_size, num_labels=2): super(multilabel_dropout, self).__init__() self.classifier = torch.nn.Linear(hidden_size, num_labels) def forward(self, out): return torch.mean(torch.stack([ self.classifier( torch.nn.Dropout(p)(out)) for p in np.linspace(0.1,0.5, 5)], dim=0) , dim=0) class MeanPooling(nn.Module): def __init__(self): super(MeanPooling, self).__init__() def forward(self, last_hidden_state, attention_mask): input_mask_expanded = attention_mask.unsqueeze(-1).expand(last_hidden_state.size()).float() sum_embeddings = torch.sum(last_hidden_state * input_mask_expanded, 1) sum_mask = input_mask_expanded.sum(1) sum_mask = torch.clamp(sum_mask, min=1e-9) mean_embeddings = sum_embeddings / sum_mask return mean_embeddings
搭建自定义的模型
from transformers import AutoModelForSequenceClassification,BertForSequenceClassification,AutoModel,AutoConfig from transformers.modeling_outputs import TokenClassifierOutput num_labels = len(class_names) class MyModel(nn.Module): def __init__(self, model_name,num_labels): super(MyModel, self).__init__() self.num_labels=num_labels self.model = AutoModel.from_pretrained(model_name) self.config = AutoConfig.from_pretrained(model_name) self.drop = nn.Dropout(p=0.2) self.pooler = MeanPooling() self.fc = nn.Linear(self.config.hidden_size,num_labels) self.multi_drop=multilabel_dropout(self.config.hidden_size,self.num_labels) def forward(self, input_ids, attention_mask=None, token_type_ids=None, position_ids=None, head_mask=None, labels=None): outputs = self.model(input_ids=input_ids, attention_mask=attention_mask,output_hidden_states=False) out = self.pooler(outputs.last_hidden_state, attention_mask) #outputs.last_hidden_state[:,0,:] # # out = self.drop(out) # logits = self.fc(out) logits= self.multi_drop(out) loss = None if labels is not None: loss_fct = nn.CrossEntropyLoss() loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1)) return TokenClassifierOutput(loss=loss, logits=logits, hidden_states=outputs.hidden_states,attentions=outputs.attentions) model = MyModel(model_name=model_ckpt,num_labels=num_labels).to(device)
搭建huggingface上通用模型
from transformers import AutoModelForSequenceClassification,BertForSequenceClassification,AutoModel,AutoConfig from transformers.modeling_outputs import TokenClassifierOutput num_labels = len(class_names) model = AutoModelForSequenceClassification\ .from_pretrained(model_ckpt, num_labels=num_labels)\ .to(device) model = BertForSequenceClassification.from_pretrained(model_ckpt, num_labels=2) model= model.to(device)
上传模型到仓库
## 下载模型权重 !sudo apt-get install git-lfs !git lfs install !git clone https://huggingface.co/THUDM/chatglm2-6b.git !GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm2-6b # 下载非lfs文件 !ls {save_path} #使用python变量; save_path='demo.txt' ## 从国内下载模型 huggingface镜像 !pip install -U huggingface_hub !git clone https://github.com/LetheSec/HuggingFace-Download-Accelerator.git %cd HuggingFace-Download-Accelerator !python hf_download.py --model mistralai/Mixtral-8x7B-Instruct-v0.1 --save_dir ../hf_hub from huggingface_hub import snapshot_download snapshot_download(repo_id="baichuan-inc/Baichuan2-13B-Chat-4bits", local_dir="baichuan-inc/Baichuan2-13B-Chat-4bits") """ ## 上传大模型到huggingface中 1. git clone https://huggingface.co/username/model_name 2. git lfs install 3. 将待上传的文件移动到该目录下 4. huggingface-cli lfs-enable-largefiles ./ ## 超过5GB文件 5. git add . 6. git commit -m "commit from $USER" 7. git push """ ## 利用python代码上传大模型到huggingface中 save_path = "your_finetune_model_weight" from huggingface_hub import login login() #需要注册一个huggingface账户,在个人页面setting那里创建一个有write权限的access token from huggingface_hub import HfApi api = HfApi() #创建huggingface 模型库 repo_id = "shujunge/chatglm2_6b_helloword" api.create_repo(repo_id=repo_id) #上传模型可能需要等待10分钟左右~ api.upload_folder( folder_path=save_path, repo_id=repo_id, repo_type="model", #space, model, datasets ) #上传成功后可以删除本地模型 !rm -rf {save_path}
模型训练和配置
设置优化器
from transformers import BertForMaskedLM, BertTokenizer, BertForSequenceClassification, BertConfig, AdamW # 设置不同的学习率 def build_optimizer(self): no_decay = ['bias', 'LayerNorm.weight'] optimizer_grouped_parameters = [ {'params': [p for n, p in self.model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': self.args.weight_decay}, {'params': [p for n, p in self.model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0} ] # optimizer = AdamW(model.parameters(), lr=learning_rate) optimizer = AdamW(optimizer_grouped_parameters, lr=self.args.learning_rate) return optimizer ## 设置不同的学习器 from transformers.optimization import Adafactor, AdafactorSchedule optimizer = Adafactor(model.parameters(), scale_parameter=True, relative_step=True, warmup_init=True, lr=None) lr_scheduler = AdafactorSchedule(optimizer) trainer = Trainer(..., optimizers=(optimizer, lr_scheduler))
定义指标函数
import evaluate predictions = trainer.predict(tokenized_datasets["validation"]) print(predictions.predictions.shape, predictions.label_ids.shape) (408, 2) (408,) preds = np.argmax(predictions.predictions, axis=-1) metric = evaluate.load("glue", "mrpc") metric.compute(predictions=preds, references=predictions.label_ids) # {'accuracy': 0.8578431372549019, 'f1': 0.8996539792387542}
使用sklearn库搭建验证指标函数
from sklearn.metrics import accuracy_score, f1_score def compute_metrics(pred) -> dict: labels = pred.label_ids preds = pred.predictions.argmax(-1) f1 = f1_score(labels, preds, average='weighted') acc = accuracy_score(labels, preds) return {'accuracy': acc, 'f1': f1} def compute_metrics(eval_preds): metric = evaluate.load("glue", "mrpc") logits, labels = eval_preds predictions = np.argmax(logits, axis=-1) return metric.compute(predictions=predictions, references=labels) from datasets import load_metric def compute_metrics(eval_pred): metrics = ["accuracy", "recall", "precision", "f1"] #List of metrics to return metric={} for met in metrics: metric[met] = load_metric(met) logits, labels = eval_pred predictions = np.argmax(logits, axis=-1) metric_res={} for met in metrics: metric_res[met]=metric[met].compute(predictions=predictions, references=labels)[met] return metric_res
使用evaluate库搭建验证指标函数
import numpy as np import evaluate metric = evaluate.load("seqeval") def compute_metrics(eval_preds): logits, labels = eval_preds predictions = np.argmax(logits, axis=-1) # Remove ignored index (special tokens) and convert to labels true_labels = [[label_names[l] for l in label if l != -100] for label in labels] true_predictions = [ [label_names[p] for (p, l) in zip(prediction, label) if l != -100] for prediction, label in zip(predictions, labels) ] all_metrics = metric.compute(predictions=true_predictions, references=true_labels) return { "precision": all_metrics["overall_precision"], "recall": all_metrics["overall_recall"], "f1": all_metrics["overall_f1"], "accuracy": all_metrics["overall_accuracy"], }
自定义损失函数
class RegressionTrainer(Trainer): def compute_loss(self, model, inputs, return_outputs=False): labels = inputs.get("labels") outputs = model(**inputs) logits = outputs.get('logits') loss = torch.mean(torch.square(logits.squeeze() - labels.squeeze())) return (loss, outputs) if return_outputs else loss class CustomTrainer(Trainer): def compute_loss(self, model, inputs, return_outputs=False): labels = inputs.get("labels") outputs = model(**inputs) # forward pass logits = outputs.get('logits') # compute custom loss # Class weighting loss_fct = nn.CrossEntropyLoss() loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1)) return (loss, outputs) if return_outputs else loss def training_step(self, model: nn.Module, inputs: Dict[str, Union[torch.Tensor, Any]]) -> torch.Tensor: model.train() inputs = self._prepare_inputs(inputs) fgm = FGM(model,epsilon=1,emb_name='word_embeddings.') with self.autocast_smart_context_manager(): loss = self.compute_loss(model, inputs) loss = loss / self.args.gradient_accumulation_steps loss=self.scaler.scale(loss) ##半精度用torch自带的就行了 loss.backward() fgm.attack() # 在embedding上添加对抗扰动 loss_adv = self.compute_loss(model, inputs) loss_adv.backward() fgm.restore() return loss_adv.detach()
继承Trainer类显示学习率
class MyTrainer(Trainer): def log(self, logs): logs["learning_rate"] = self._get_learning_rate() super().log(logs)
配置Trainer类相关训练模型超参数
## 配置训练参数 logging_steps = len(disaster_tweets_encoded['train']) // batch_size model_name = f"{model_ckpt}-finetuned-disaster" training_args = TrainingArguments( seed=seed_val, report_to='none', output_dir=model_name, learning_rate=3e-5, per_device_train_batch_size=batch_size, per_device_eval_batch_size=batch_size, weight_decay=.01, disable_tqdm=False, logging_steps=logging_steps, log_level='error', load_best_model_at_end=True, save_total_limit = 1, fp16=True, # 按照epoch设置 num_train_epochs= 2, save_strategy="epoch", ## 与evaluation_strategy保存一致 evaluation_strategy='epoch', # 按照step设置训练参数 evaluation_strategy='steps', save_strategy= 'steps', save_steps=logging_steps, eval_steps=logging_steps, max_steps=logging_steps*n_epochs, # metric_for_best_model='f1', ##设置监控指标 如果这个设置了值,对于的greater_is_better则为True # greater_is_better=True, ## 保存最大或者最小 ##默认为False(值越小越好) push_to_hub=False, )
模型训练
trainer = MyTrainer( model=model, args=training_args, compute_metrics=compute_metrics, train_dataset=disaster_tweets_encoded['train'], eval_dataset=disaster_tweets_encoded['validation'], tokenizer=tokenizer, callbacks=[early_stop, mlc], ) trainer.train() #模型训练 trainer.evaluate() #模型验证 #模型预测 # trainer.save_model(f"{n}_fold_weights") proba_prediction_test = trainer.predict(disaster_tweets_test_encoded['test'])
模型的权重保存
self.model = BertForMaskedLM.from_pretrained(args.model_path) torch.save(self.model.state_dict(), "bert_prompt.pt") trainer = Trainer(args) model = BertForMaskedLM.from_pretrained(args.model_path) model.load_state_dict(torch.load(ckpt_path)) model.to(args.device) trainer.save_model("my_weight") tokenizer.save_pretrained('my_weight') trainer.push_to_hub(commit_message="Training complete", tags="summarization") ## 推送远程仓库
模型验证和指标计算
from sklearn.metrics import classification_report results = trainer.predict(disaster_tweets_test_encoded['test'])['predictions'] report=classification_report(test['labels'], np.argmax(results, axis=-1).tolist(), target_names=class_names)
添加记录训练曲线函数
from transformers import TrainerCallback class CustomCallback(TrainerCallback): def __init__(self, trainer) -> None: super().__init__() self._trainer = trainer def on_epoch_end(self, args, state, control, **kwargs): if control.should_evaluate: control_copy = deepcopy(control) self._trainer.evaluate(eval_dataset=self._trainer.train_dataset, metric_key_prefix="train") return control_copy trainer = Trainer( model=model, # the instantiated Transformers model to be trained args=training_args, # training arguments, defined above train_dataset=train_dataset, # training dataset eval_dataset=valid_dataset, # evaluation dataset compute_metrics=compute_metrics, # the callback that computes metrics of interest tokenizer=tokenizer ) trainer.add_callback(CustomCallback(trainer)) train = trainer.train() {‘train_loss’: 0.7159061431884766, ‘train_accuracy’: 0.4, ‘train_f1’: 0.5714285714285715, ‘train_runtime’: 6.2973, ‘train_samples_per_second’: 2.382, ‘train_steps_per_second’: 0.159, ‘epoch’: 1.0} {‘eval_loss’: 0.8529007434844971, ‘eval_accuracy’: 0.0, ‘eval_f1’: 0.0, ‘eval_runtime’: 2.0739, ‘eval_samples_per_second’: 0.964, ‘eval_steps_per_second’: 0.482, ‘epoch’: 1.0}
在线部署大模型进行部署推理
部署chatglm3_6b模型进行16位推理预测
环境配置
from IPython.display import clear_output !pip install transformers>=4.37.0 !pip install -q peft !pip install -q accelerate !pip install -q bitsandbytes import torch import transformers import peft import accelerate print("torch:",torch.__version__) #torch: 2.1.2 print("transformers:",transformers.__version__) #transformers: 4.37.0 print("peft:",peft.__version__) #peft: 0.8.2 print("accelerate:",accelerate.__version__) #accelerate: 0.26.1 !pip show bitsandbytes #Version: 0.42.0 # 验证是否支持nf4 from bitsandbytes.cuda_setup.main import CUDASetup setup = CUDASetup.get_instance() if setup.initialized != True: setup.run_cuda_setup() lib = setup.lib lib.cquantize_blockwise_fp16_nf4
在线编写代码部署chatglm3_6B实时推理
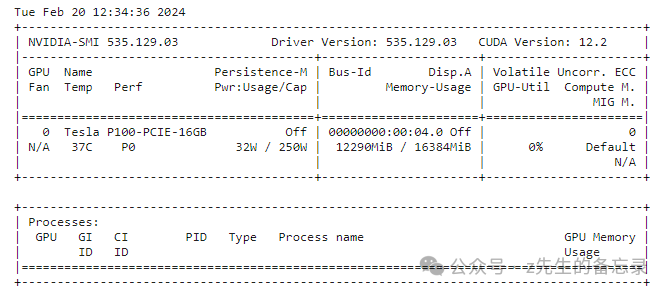
下面我将给大家利用transformers框架进行实操部署chatglm3以半精度(float16)进行在线推理。显卡采用kaggle:P100,16G;
#下载chatglm3-6b权重 from huggingface_hub import snapshot_download snapshot_download(repo_id="THUDM/chatglm3-6b", local_dir='THUDM/chatglm3-6b') import gc import ctypes import torch import random from transformers import AutoTokenizer,AutoConfig, AutoModel, BitsAndBytesConfig import torch # 释放不必要的显存和内存 def clean_memory(): gc.collect() ctypes.CDLL("libc.so.6").malloc_trim(0) torch.cuda.empty_cache() from transformers import AutoModelForCausalLM, AutoTokenizer model_name_or_path = '/kaggle/working/THUDM/chatglm3-6b' tokenizer = AutoTokenizer.from_pretrained( model_name_or_path, torch_dtype= torch.float16, trust_remote_code=True) model = AutoModel.from_pretrained(model_name_or_path,trust_remote_code=True).half().cuda() !nvidia-smi
```python %%time response,history= model.chat(tokenizer,query= '你好。你是谁,你能干什么',history=[]) print(response)
输出结果:
你好,我是 ChatGLM3-6B,是清华大学 KEG 实验室和智谱 AI 公司于 2023 年共同训练的语言模型。我的任务是针对用户的问题和要求提供适当的答复和支持。我能够回答各种问题,包括但不限于科学、技术、历史、文化、娱乐等方面。同时,我也能够提供一些基本的服务,如智能推荐、语言翻译、代码调试等。 CPU times: user 4.05 s, sys: 0 ns, total: 4.05 s Wall time: 4.05 s
对qwen1.5_7B模型进行4位推理预测
下面是编写python代码进行加载qwen1.5_7B大模型的按照4位精度加载推理案例。
from IPython.display import clear_output # 切记版本要升级在4.37.0以上 !pip install transformers>=4.37.0 !pip install -q peft !pip install -q accelerate !pip install -q bitsandbytes import torch import transformers import peft import accelerate print("torch:",torch.__version__) #torch: 2.1.2 print("transformers:",transformers.__version__) #transformers: 4.37.0 print("peft:",peft.__version__) #peft: 0.8.2 print("accelerate:",accelerate.__version__) #accelerate: 0.26.1 !pip show bitsandbytes #Version: 0.42.0 # 搭建模型 from transformers import AutoModelForCausalLM, AutoTokenizer,BitsAndBytesConfig import torch device = "cuda" # the device to load the model onto bnb_config=BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16, bnb_4bit_use_double_quant=True, #QLoRA 设计的 Double Quantization bnb_4bit_quant_type="nf4", #QLoRA 设计的 Normal Float 4 量化数据类型 llm_int8_threshold=6.0, llm_int8_has_fp16_weight=False, ) """ 注意:Qwen1.5 最大的不同之处,在于 Qwen1.5 与 HuggingFace transformers 代码库的集成。从 4.37.0 版本开始,您可以直接使用 transformers 库原生代码,而不加载任何自定义代码(即指定trust_remote_code=True)来使用 Qwen1.5 """ model = AutoModelForCausalLM.from_pretrained( "Qwen/Qwen1.5-7B-Chat", load_in_4bit=True, torch_dtype= torch.float16, quantization_config=bnb_config, ) tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-7B-Chat") model
%%time prompt = "什么是大模型?" messages = [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": prompt} ] text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) model_inputs = tokenizer([text], return_tensors="pt").to(device) gen_kwargs = { "max_new_tokens": 1024, "num_beams": 1, "do_sample": True, "top_p": 0.8, "temperature": 0.01, "top_k": 50, 'repetition_penalty':1 } generated_ids = model.generate( model_inputs.input_ids, **gen_kwargs ) generated_ids = [ output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids) ] response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] print(response)
大模型通常指的是在人工智能领域中训练规模较大、参数较多的模型,这些模型通常具有更高的计算资源需求和训练时间,但也可以学习到更复杂的模式和知识,从而在各种任务上表现出更强的性能。 大模型可以指的是一系列模型,例如在自然语言处理领域,BERT、GPT-2、GPT-3等都是大型预训练模型,它们的参数量通常在数十亿到万亿级别。这些模型在训练时使用大量的未标注数据,然后通过微调(fine-tuning)的方式在特定任务上进行优化,以达到更好的效果。 大模型的优点是可以处理更复杂的任务和大规模的数据,但同时也带来了挑战,如需要大量的计算资源、训练时间长、过拟合等问题,以及可能的隐私和伦理问题。 CPU times: user 12.7 s, sys: 0 ns, total: 12.7 s Wall time: 12.7 s
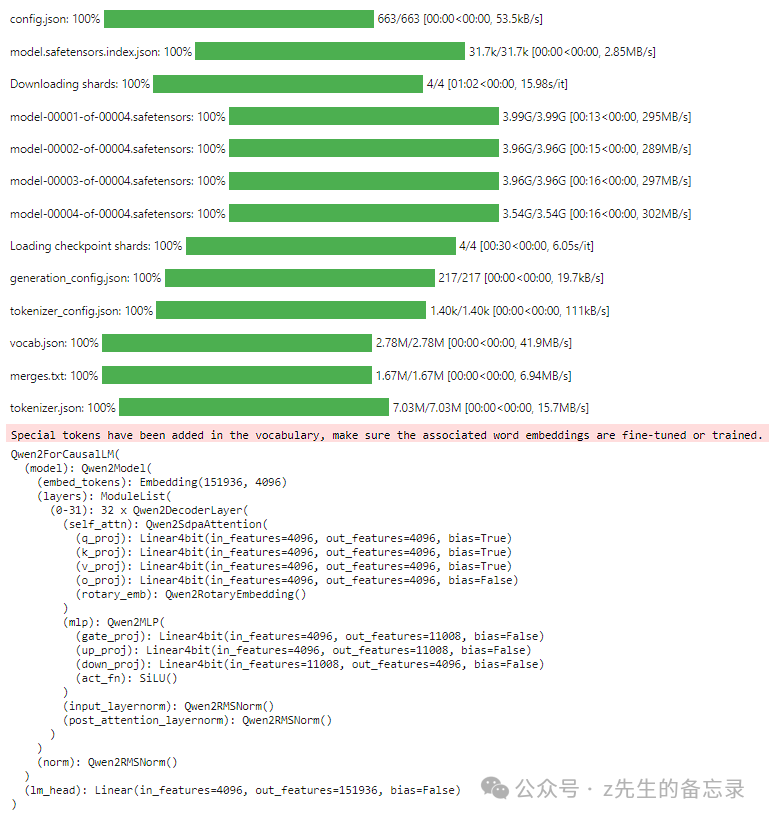
qwen1.5_7B 4位精度显存占用情况
这是qwen1.5_7B模型在4位精度下显存占用情况。
!nvidia-smi
+---------------------------------------------------------------------------------------+ | NVIDIA-SMI 535.129.03 Driver Version: 535.129.03 CUDA Version: 12.2 | |-----------------------------------------+----------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+======================+======================| | 0 Tesla P100-PCIE-16GB Off | 00000000:00:04.0 Off | 0 | | N/A 40C P0 37W / 250W | 6892MiB / 16384MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=======================================================================================| +---------------------------------------------------------------------------------------+
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
-END-
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









