







一、背景
- AWQ(Activation-aware Weight Quantization)是一种用于大型语言模型(LLM)的权重量化技术,旨在减少模型大小和加速推理过程,同时保持模型性能。AWQ的核心思想是权重对模型性能的重要性并不相同,因此通过保护更重要的权重(通常是较小的一部分,如0.1%-1%),可以显著减少量化误差。AWQ不依赖于反向传播或重构,有助于保持模型在不同领域和模态上的泛化能力。此外,AWQ还实现了一个高效的推理框架,显著提高了在桌面和移动GPU上的运行速度。
二、引言
- 现状问题
- QAT(量化感知训练)需要高训练成本。
- PTQ low-bit 状态下,精度损失比较大,GPTQ使用二阶信息能一定程度缓解问题,但是容易过拟合,具体表现为重建模型的时候会扭曲分布外域上的学习特征。
- 本文基于权重对LLM效果不是同样的重要的假设,提出AWQ:
- 参考激活值,而不是权重值的方法来进行针对性量化,量化对象还是模型权重。
- 所以,针对不同的权重,缩放范围也不一样,来达到最优量化的效果。
- 本文还实现了一个高效的框架,用于推理,对比HF,实现3倍以上加速,AWQ已经可以用于vLLM、HuggingFace、LMDeploy等推理框架上。
三、实现原理
3.1 初步方案、推论和实验
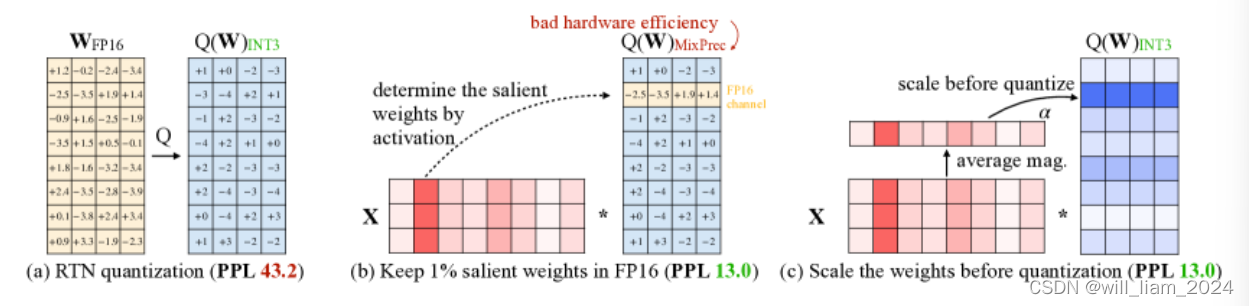
- 图a:RTN(round-to-nearest quantization),直接四舍五入量化,可以看到效果一般,PPL 43.2。
- 图b:x是激活值,通过发现重要激活值,来找到右边蓝色的salient weights(指在模型中对最终输出或决策具有重要影响的权重)。保留着salient weights的FP16 channel,其他参数都进行了RTN量化,模型效果达到PPL 13.0。但是这种方案对硬件不友好,因为参数是混合精度存储的。
- 图c:方案三,还是对W进行量化,只不过是针对x激活值来进行个性化的量化,所以可以看到右边Q(W)的矩阵,每一行不同颜色,代表每个通道缩放的范围都不一样。下面来看看具体的原理。
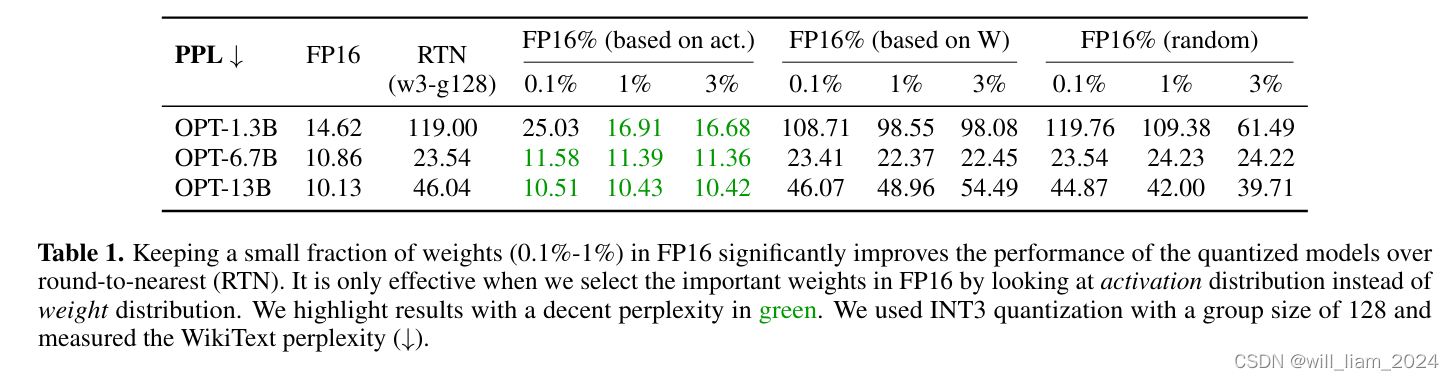
- Table1 是通过实验来证明一个结论,基于activation(激活值的大小)来进行进行权重量化,比基于权重W,和random,更接近全是FP16的效果。并且保留0.1%-1%的channel,其他进行量化,模型效果已经十分接近FP16精度的效果。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1837
1837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









