









-
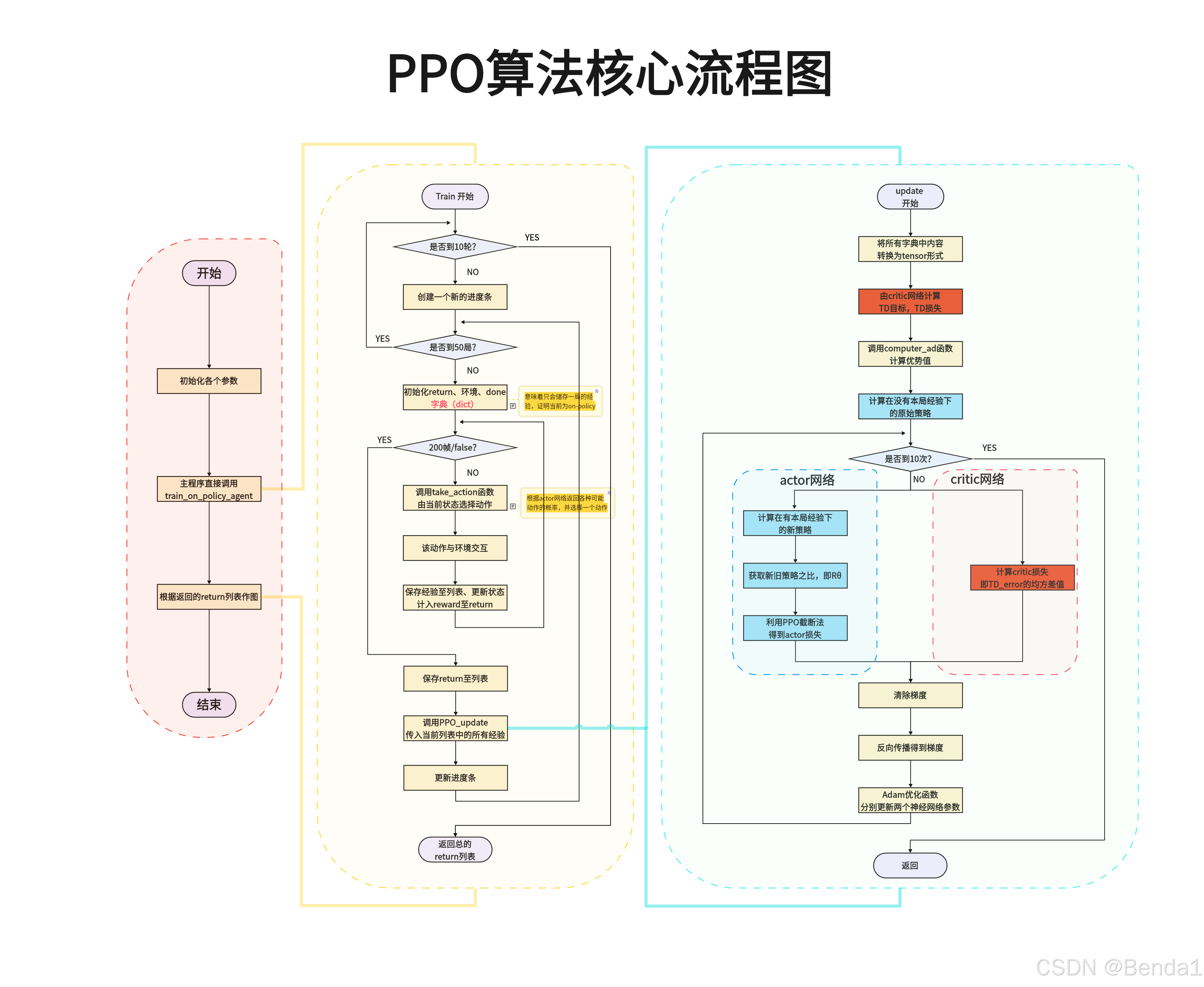
初始化:首先,算法初始化一个智能体,并准备相关的参数和环境。
-
训练阶段:
- 检查是否达到训练迭代次数上限。如果达到,则结束训练。
- 否则,进行环境的交互,收集状态、动作及奖励信息。
-
数据收集:
- 通过与环境的交互,收集状态(state)、动作(action)、奖励(reward)和终止信号(done)等数据,保存为一个经验回放。
-
更新机制:
- 检查是否满足更新条件(如达到固定的步数)。
- 根据收集到的数据计算回报(Return)并进行策略更新。
-
优化步骤:
- 分别利用actor和critic网络。Actor网络用于生成动作策略,而Critic网络用来评估这些动作的价值。
- 在计算损失时,PPO会限制策略更新的范围,以避免过大的政策变化,确保学习过程的稳定性。
-
策略评估和更新:
- 采用PPO算法进行策略更新,计算损失后进行反向传播训练网络。
-
循环迭代:重复进行上述步骤,直到满足终止条件,最后输出学习得到的策略。

















 1395
1395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









