







 本文详细介绍了在Python中使用Selenium库的webdriver.Chrome对象进行网页加载的两种常见方法:get()和execute_script。get()用于加载单个页面,而execute_script则用于打开多个标签页并执行JavaScript。同时,文章还说明了如何通过page_source()方法获取渲染后的网页代码。
本文详细介绍了在Python中使用Selenium库的webdriver.Chrome对象进行网页加载的两种常见方法:get()和execute_script。get()用于加载单个页面,而execute_script则用于打开多个标签页并执行JavaScript。同时,文章还说明了如何通过page_source()方法获取渲染后的网页代码。
目录
使用类webdriver.Chrome创建的驱动浏览器对象中包含大量操作浏览器的方法,类webdriver.Chrome继承于基础类WebDriver,该类位于selenium库的webdriver\remote\webdriver.py文件中.
两种常用的加载网页的方法
-
1、get()方法
用于打开指定的网页。
使用形式:get(url)
功能:在当前浏览器会话中加载url指定的网页
示例代码:(加载人民邮电出版社的图书页)
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options=Options()
chrome_options.binary_location=r"C:\Users\72550\AppData\Roaming\360se6\Application\360se.exe"#浏览器所在地址
driver=webdriver.Chrome(options=chrome_options)
driver.get('https://www.ptpress.com.cn/shopping/index')#人民邮电出版社图书页的url执行结果:
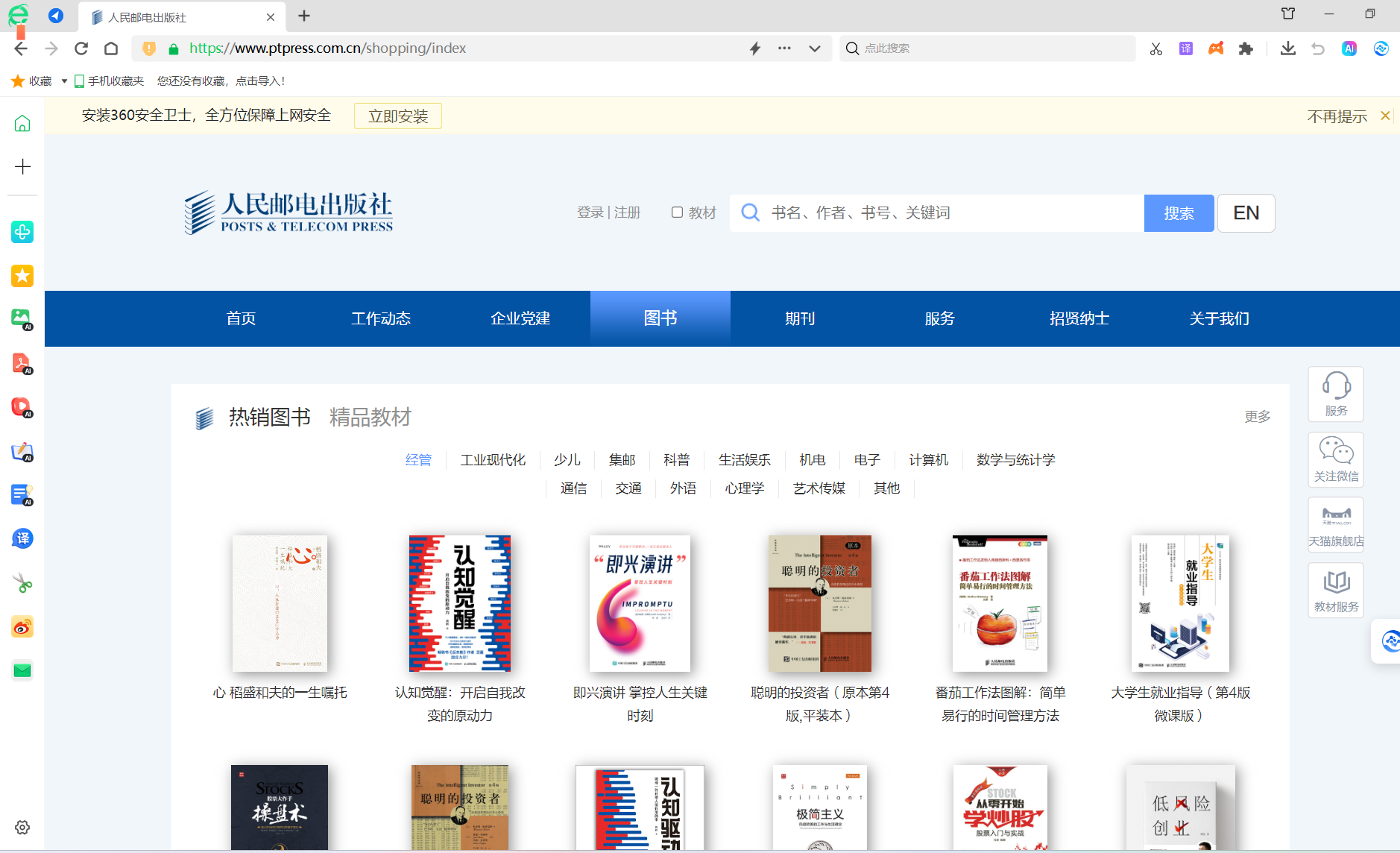
-
2、execute_script方法
用于打开多个标签页,即在同一个浏览器中打开多个网页。
使用形式:execute_script(script,*argv)
功能:打开标签页,同步执行当前页面中的JavaScript脚本。
参数script:表示将要执行的脚本内容。数据类型为字符串类型,使用JavaScript语言实现打开一个新标签页的使用形式为:“window.open('网站url','_blank');"
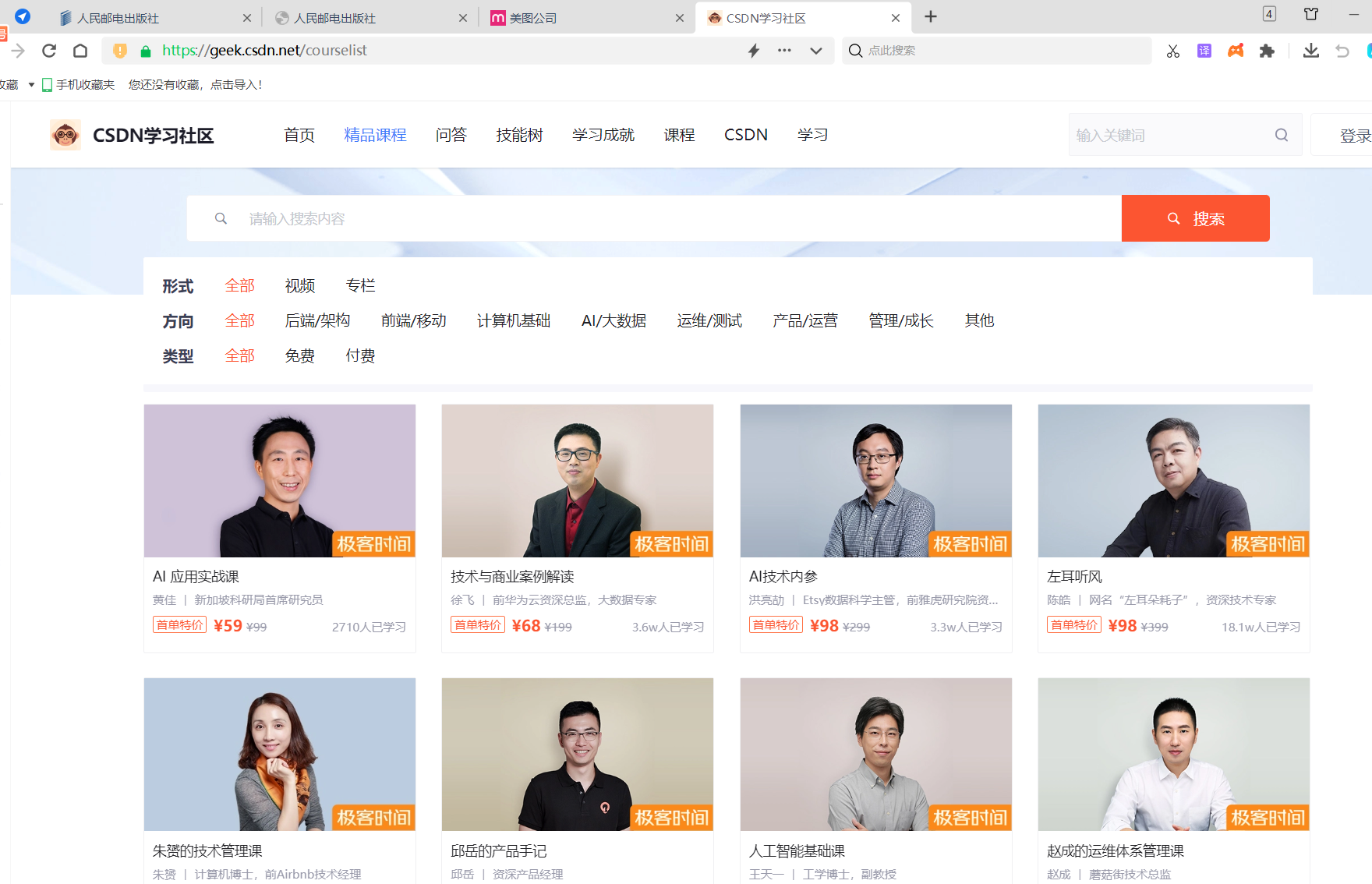
示例代码:(打开多个标签页)
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options=Options()
chrome_options.binary_location=r"C:\Users\72550\AppData\Roaming\360se6\Application\360se.exe"#浏览器所在地址
driver=webdriver.Chrome(options=chrome_options)
driver.get('https://www.ptpress.com.cn/')#人民邮电出版社官网的url
driver.execute_script("window.open('https://www.ptpress.com.cn/login','_blank');")#人民邮电出版社的登录界面
driver.execute_script("window.open('https://www.meitu.com/zh/','_blank');")#美图的首页
driver.execute_script("window.open('https://geek.csdn.net/courselist','_blank');")#CSDN精品课程的界面执行结果:(打开了三个标签页)
获取渲染后的网页代码
通过get()方法获取浏览器的网页资源后,浏览器将自动渲染网页源代码内容,并生成渲染后的内容。这时使用page_source()方法即可获取渲染后的网页代码。
示例代码:(获取人民邮电出版社官网url渲染后的网页代码)
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options=Options()
chrome_options.binary_location=r"C:\Users\72550\AppData\Roaming\360se6\Application\360se.exe"#浏览器所在地址
driver=webdriver.Chrome(options=chrome_options)
driver.get('https://www.ptpress.com.cn/')#人民邮电出版社官网的url
print(driver.page_source)#获取被get()方法获取到的渲染后的网页源代码执行结果:(浏览器自动跳转到人民邮电出版社的官网地址,并且在pycharm运行界面中返回渲染后的网页源代码)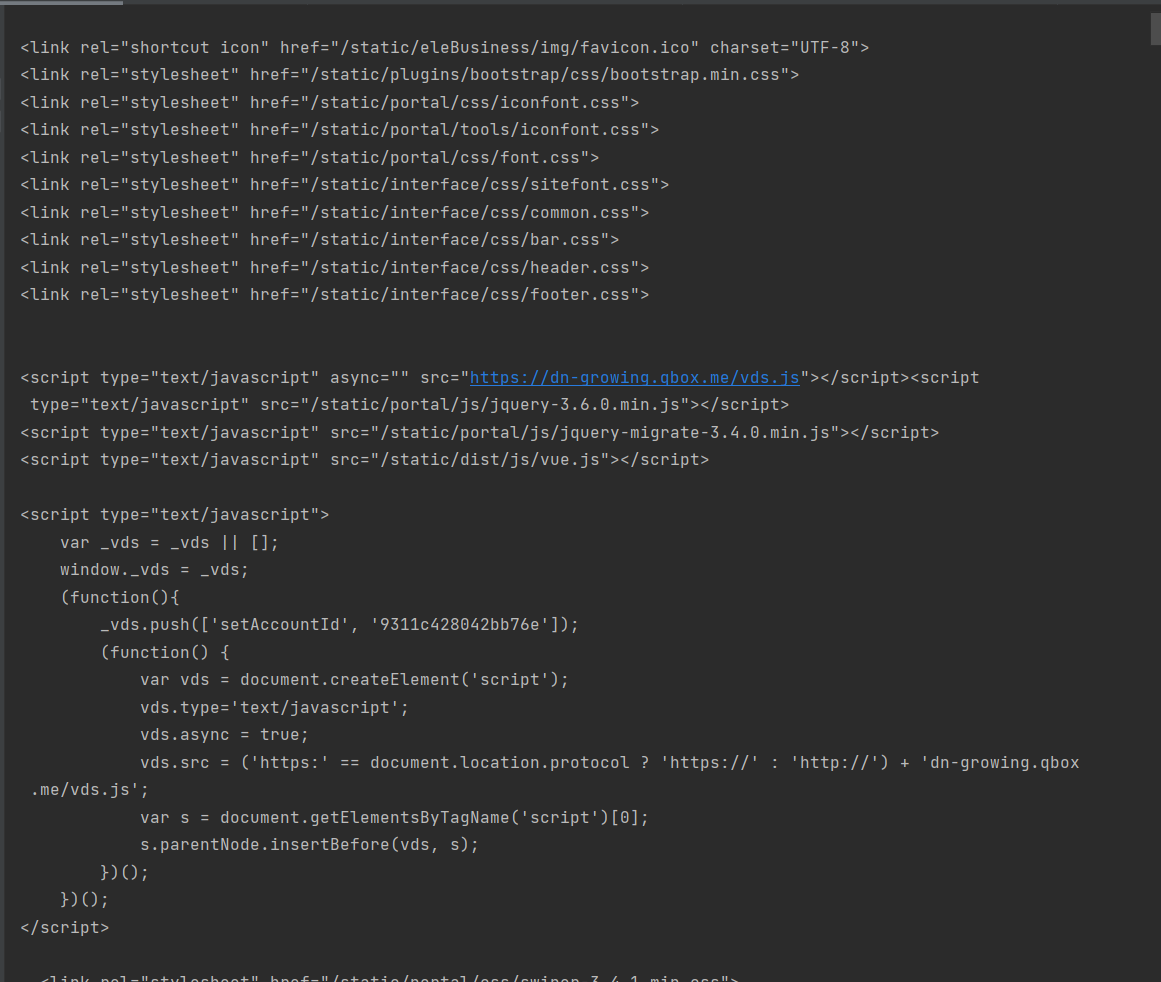

......介绍完毕!
xue

















 312
312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









