






来源于哔站跟着李沐学AI,整理学习笔记,方便以后查看。
摘要:使用残差学习框架来训练较难训练的深度神经网络
深度对于计算机视觉学习来说非常的重要
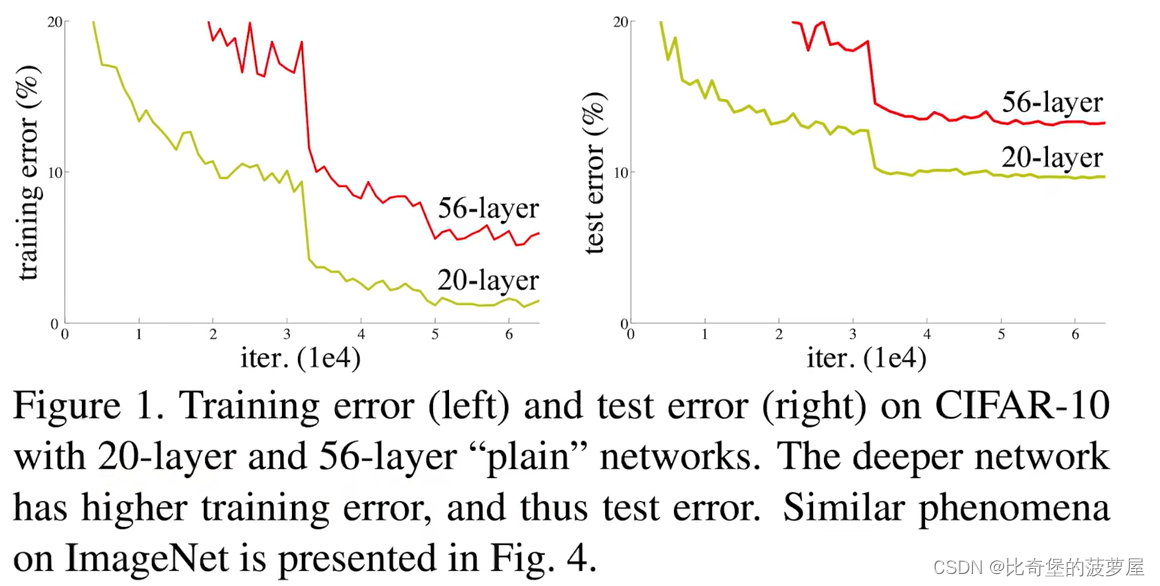 图片想告诉我们训练一个很深层的神经网络是比较困难的,误差会更高。然后论文来解决这个问题。下图就是加入了resnet后的对比图。
图片想告诉我们训练一个很深层的神经网络是比较困难的,误差会更高。然后论文来解决这个问题。下图就是加入了resnet后的对比图。
 1.总体介绍
1.总体介绍
层数变多会导致精度变差(训练和预测都很差),它不是由于层数变多而导致的过拟合(overfitting),而是训练误差和测试误差都变的高了。
而对于overfitting来说,结果不准确是因为训练误差很低但是测试误差很高。
针对于这种加了深度的模型来说,虽然最后可以收敛,但是精度是不太好的。
假设有一个比较浅的模型效果很好,按道理说给他加几层进去效果也应该差不多。因为如果深层次模型变成浅模型+identity mapping,而identity mapping只是每一层权重都设为1/n,那么identity mapping的输入和输出应该是不变的,应该等于浅模型的输出,所以理论推理可以得到一个较优的解。
但是实践上使用SGD时是找不出来的。
所以本文提出了要显示的构造出一个identity mapping来深度网络结果不会差于浅一点的网络。即:
deep residual learning framework
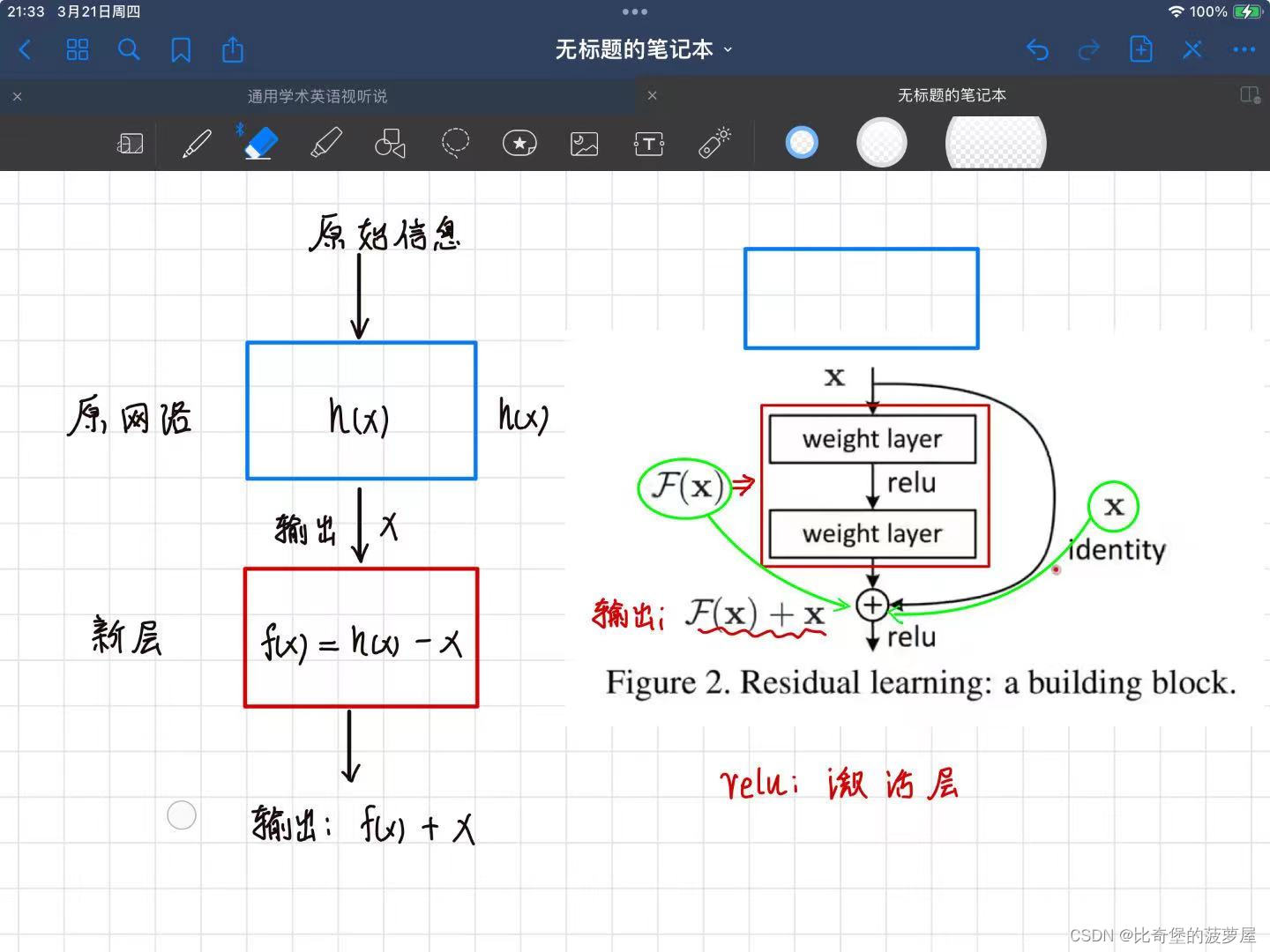
与传统的学习方式相比,新层不再学习原始层的H(x),而是学习自己的F(x),并且F(x)是由H(x)-x构成的。新层最后的输出结果是F(x)+x。
上右图旁边多出来的x identity就是与之前网络的区别,在这里他的名字叫residual。通过增加多出来的x,不会增加原有模型的复杂度,不会让计算变高。而且越深,此架构的精度越高。
到此为止介绍了ResNet的总体思路和框架,具体实现的结构没有继续阅读,属于深度学习领域,暂时跳过,如果以后想学再来补充。over~~~
















 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









