







最近已有不少大厂都在秋招宣讲了,也有一些在 Offer 发放阶段。
节前,我们邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对新手如何入门算法岗、该如何准备面试攻略、面试常考点、大模型技术趋势、算法项目落地经验分享等热门话题进行了深入的讨论。
总结链接如下:
喜欢本文记得收藏、关注、点赞。更多实战和面试交流,文末加入我们星球
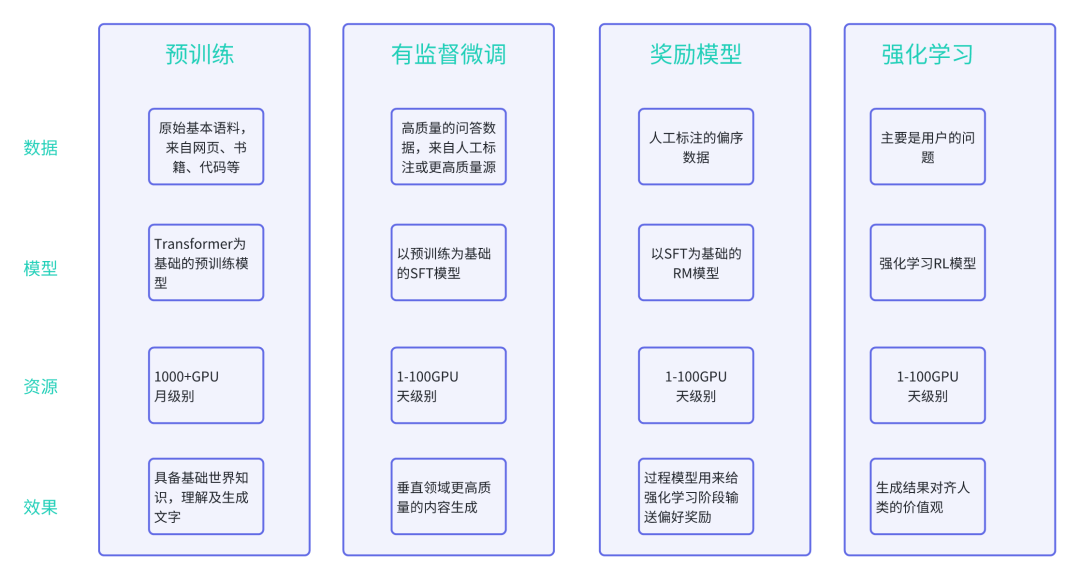
大语言模型的构建过程一般分为两个阶段,即:预训练、人类对齐(对齐再细分为指令微调+基于人类反馈强化学习)
预训练-数据准备流程

-
原始语料库:为了构建功能强大的语言模型,需要从多元化的数据源中收集海量数据来进行训练。网页、书籍、代码、对话语料是主要的预训练数据。根据来源不同,可以分为通用文本数据和专用文本数据。
-
数据预处理:质量过滤、敏感内容过滤、数据去重。这一环节主要通过数据的规则特征、垂直定向小模型训练识别并去除质量差、有毒性、隐私的数据。
-
词元化:将文本内容处理为最小基本单元,用于后续的训练准备。
预训练-Transformer模型架构
Transformer是由多层的多头注意力(Multi-head Self-attention)模块堆叠而成的神经网络模型。原始Transformer模型由编码器和解码器两个部分构成,而这两个部分实际上可以独立使用,例如基于编码器架构的BERT模型和解码器架构的GPT模型(后续文章再对Transformer进行详尽解析)

指令微调
指令微调(Instruction Tuning)是指使用自然语言形式的数据对预训练后的大语言模型进行参数微调,也称为有监督微调或多任务提示训练。
指令微调的数据集构建
-
基于现有的NLP任务数据集构建:学术界围绕传统NLP任务(如机器翻译、文本摘要和文本分类等)发布了大量的开源数据集合,这些数据是非常重要的监督学习数据资源,可以用于指令数据集构造。
-
基于日常对话数据构建:用户在日常对话中的实际需求作为任务描述,与人类真实诉求较为匹配,增加数据的多样性。
-
基于合成数据构建:借助已有高质量指令数据作为上下文学习示例,输入给大语言模型,进而生成大量多样化的任务描述和输入-输出数据。
指令微调的训练策略
-
优化设置:指令微调中的优化器设置(AdamW或Adafactor)、稳定训练技巧(权重衰减和梯度剪裁)和训练技术(3D并行、ZeRO和混合精度训练)都与预训练保持阶段一致,可以完全沿用。下面列出指令微调与预训练的不同之处。
-
数据组织:平衡数据分布
-
参数高效微调:如 低秩适配微调方法、适配器微调、前缀微调(这里我们也留到后文进行详细介绍,本文优先关注整体流程)
人类对齐RM/RL(强化学习阶段)
人类对齐是一个较为抽象的概念,难以直接进行形式化建模,代表性的是有用性(Helpfulness)、诚实性(Honesty)和无害性(Harmlessness),主要由以下两个阶段
奖励模型训练 | 这一步是使用人类反馈数据训练奖励模型 首先,使用语言模型针对任务指令生成一定数量的候选输出 然后,邀请标注员对于输出文本进行偏好标注(形式多种) 最后,使用偏好数据进行奖励模型的训练,使其建模人类偏好。 |
强化学习训练 | 这一步,语言模型对齐被转化为一个强化学习问题。具体来说: 待对齐语言模型担任策略实施者角色(称为策略模型),它接收提示作为输入并返回输出文本,其动作空间是词汇表中所有词元,状态指的是当前已生成的词元序列。 奖励模型则根据当前语言模型的状态提供相应的奖励分数,用于指导策略模型的优化。 为了避免当前训练轮次的语言模型明显偏离初始(强化学习训练之前)的语言模型,通常会在原始优化目标中加入一个惩罚项(如KL离散度) 例如:Instruct GPT使用PPO算法来优化待对齐语言模型,以最大化奖励模型的奖励。对于每个输入提示,InstructGPT计算当前语言模型与初始语言模型生成结果之间的KL离散度作为惩罚项。KL散度越大,意味着当前语言模型越偏离初始语言模型。 |

















 5200
5200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









