







本次项目是使用AlexNet实现5种花类的识别。
训练集搭建与LeNet大致代码差不多,但是也有许多新的内容和知识点。
1.导包,不必多说。
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt # 从 matplotlib.pyplot 导入 imshow 函数
import numpy as np
import torch.optim as optim
from model import AlexNet
import os
import json
import time2.指定设备
device函数用来指定在训练过程中所使用的设备:如果有可用的GPU,那么使用第一块GPU,如果没有就默认使用cpu。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)3.数据预处理函数
单独定义出来,当key为“train”或为“val”时,返回数据集要使用的一系列预处理方法。
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224), # 把图片重新裁剪为224*224
transforms.RandomHorizontalFlip(), # 水平方向随机翻转
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
4.获取数据集的路径
os.getcwd()方法获取当前文件所在的目录
os.path.join()方法将当前路径与上两级路径链接起来
image_path:获取到flower_data所在路径
data_root = os.path.abspath(os.path.join(os.getcwd(), "../.."))
image_path = data_root + "/data_set/flower_data"
# train set
train_dataset = datasets.ImageFolder(root=image_path + "/train", # 获取训练集的路径
transform=data_transform["train"]) # 训练预处理
train_num = len(train_dataset) # 打印训练集有多少张照片5.加载数据集分类文件
{'daisy': 0, 'dandelion': 1, 'roses': 2, 'sunflower': 3, 'tulips': 4} :数据集共分为五类
flower_list = train_dataset.class_to_idx 获取分类的名称所对应的索引值
cla_dict = dict((val, key) for key, val in flower_list.items()) 将字典中键与值的位置对换
?为什么要换位置
=>这样在预测后可以直接通过值给到我们最后的测试类别
json_str = json.dumps(cla_dict, indent=4) :将字典编码成json格式
with open('class_indices,json', 'w') as json_file:
json_file.write(json_str) :将键值对保存到json文件中,方便后续在预测时读取信息
下面是生成的json文件
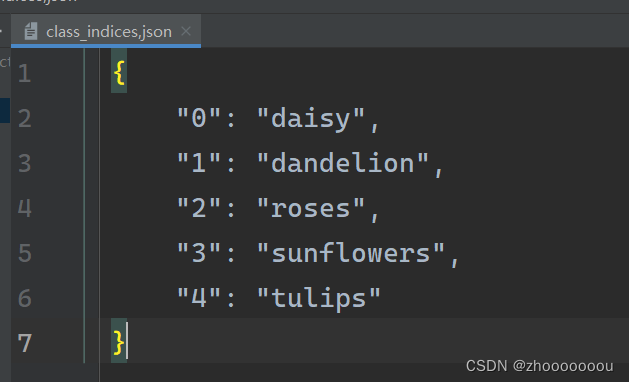
# {'daisy': 0, 'dandelion': 1, 'roses': 2, 'sunflower': 3, 'tulips': 4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# 把文件写入json文件
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices,json', 'w') as json_file:
json_file.write(json_str)6.载入测试集
代码大致与LeNet网络差不多,载入测试集的图片路径需要自己定义并进行预处理。
在使用matplotlib查看图片时,注意修改为batch_size=4,shuffle=True参数。
batch_size = 32
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=0)
#
validate_dataset = datasets.ImageFolder(root=image_path + "/val",
transform=data_transform["val"])
val_num = len(validate_dataset)
validata_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=batch_size,
shuffle=False, num_workers=0)6.5 查看测试数据
在原来的基础上做了修改,原来使用test_data_iter.next() 调用方式,但是test_data_iter.next() 调用方式已经过时。在 Python 中,迭代器的 next() 方法应该直接调用,而不是使用 iter.next() 的形式。所以应该使用 next(test_data_iter) 代替 test_data_iter.next()。
!! 再使用 imshow () 函数时调用 mayplotlib.pyplot 库!
test_data_iter = iter(validate_loader)
test_image, test_label = next(test_data_iter)
# 查看图片
def imshow(img):
img = img / 2 + 0.5
nping = img.numpy()
plt.imshow(np.transpose(nping, (1, 2, 0)))
plt.show()
# print labels
print(' '.join('%5s' % str(cla_dict[test_label[j].item()]) for j in range(4)))
# show images
imshow(utils.make_grid(test_image))
查看数据的结果
预测结果分别是 蒲公英、向日葵、 郁金香、郁金香
这个图片像素不高,不是很清楚,我专门去测试集的数据中找到了原图片,都预测对了。

7. 模型实例化
net = AlexNet(num_classes=5, init_weights=True)
net.to(device) # 将网络指定到运行设备上
loss_function = nn.CrossEntropyLoss() # 定义损失函数,针对多类别的损失交叉函数
optimizer = optim.Adam(net.parameters(), lr=0.0002) # 设置优化器
8.开始训练模型
通过一整个for循环来实现模型训练,基本过程与LeNet网络实现差不多 (ps:PyTorch搭建LeNet训练集详细实现-CSDN博客)第五部分),新出现的代码做了注释解释。
save_path = './AlexNet.pth'
best_acc = 0.0
for epoch in range(10):
net.train() # 管理dropout方法
running_loss = 0.0
t1 = time.perf_counter() # 调time包获取训练过程中的测试时间
for step, data in enumerate(train_loader, start=0):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
rate = (step+1) / len(train_loader) # 训练进度
a = "*" * int(rate*50)
b = "." *int((1-rate)*50)
print("\rtrain loss: (:3.0f)%[()->:.3f)".format(int(rate * 100), a, b, loss), end="")
print()
print(time.perf_counter()-t1)
# 进行验证测试集
net.eval()
acc = 0.0
with torch.no_grad(): # 禁止对pytorch对参数的追踪
for data_test in validate_loader:
test_images, test_labels = data_test
outputs = net(test_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += (predict_y == test_labels.to(device)).sum().item()
accurate_test = acc / val_num # 计算准确率
if accurate_test > best_acc:
best_acc = accurate_test # 如果新的准确率大于最好的那个,将新的赋值给best_acc
torch.save(net.state_dict(), save_path) # 保存路径
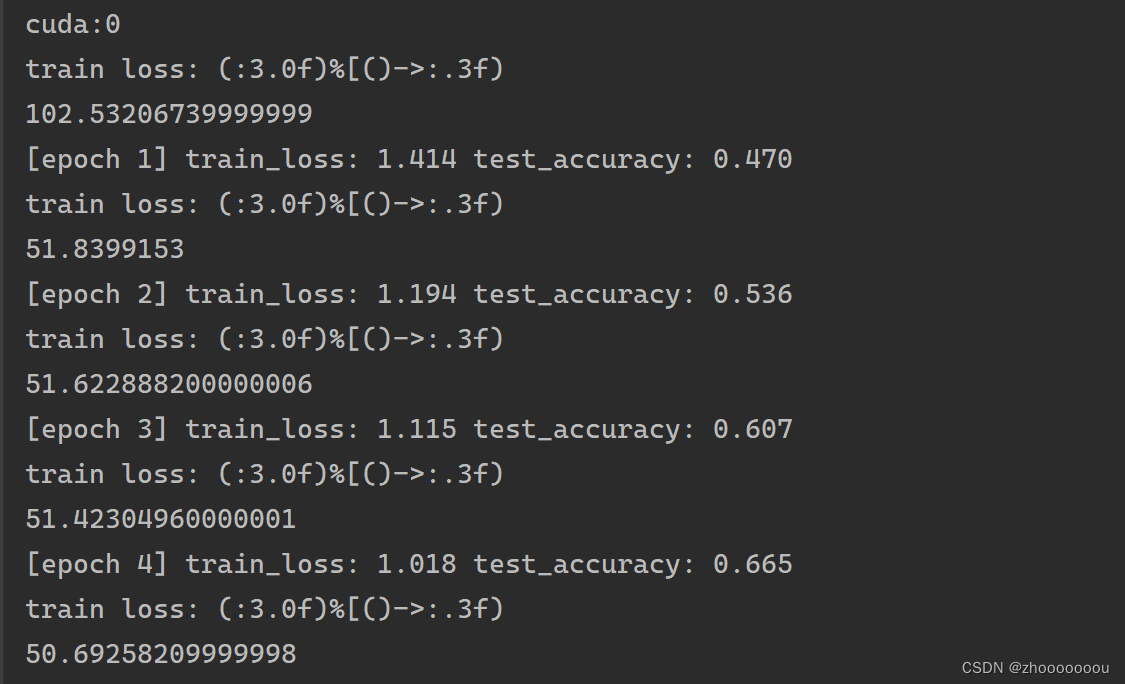
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, running_loss / step, acc / val_num))
print("Finished Training")9.运行代码,查看结果
后面的准确率达到了60%多,还可以,我感觉我用GPU跑的还挺慢的,五十多秒,但是比用cpu跑的快。

全部代码
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib as plt
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from model import AlexNet
import os
import json
import time
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../.."))
image_path = data_root + "/data_set/flower_data"
# train set
train_dataset = datasets.ImageFolder(root=image_path + "/train",
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy': 0, 'dandelion': 1, 'roses': 2, 'sunflower': 3, 'tulips': 4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# 把文件写入接送文件
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices,json', 'w') as json_file:
json_file.write(json_str)
batch_size = 32
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=0)
#
validate_dataset = datasets.ImageFolder(root=image_path + "/val",
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=4,
shuffle=True, num_workers=0)
# test_data_iter = iter(validate_loader)
# test_image, test_label = next(test_data_iter)
#
# # 查看图片
# def imshow(img):
# img = img / 2 + 0.5
# nping = img.numpy()
# plt.imshow(np.transpose(nping, (1, 2, 0)))
# plt.show()
# # print labels
# print(' '.join('%5s' % str(cla_dict[test_label[j].item()]) for j in range(4)))
# # show images
# imshow(utils.make_grid(test_image))
net = AlexNet(num_classes=5, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0002)
save_path = './AlexNet.pth'
best_acc = 0.0
for epoch in range(10):
net.train()
running_loss = 0.0
t1 = time.perf_counter()
for step, data in enumerate(train_loader, start=0):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
rate = (step+1) / len(train_loader)
a = "*" * int(rate*50)
b = "." *int((1-rate)*50)
print("\rtrain loss: (:3.0f)%[()->:.3f)".format(int(rate * 100), a, b, loss), end="")
print()
print(time.perf_counter()-t1)
net.eval()
acc = 0.0
with torch.no_grad():
for data_test in validate_loader:
test_images, test_labels = data_test
outputs = net(test_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += (predict_y == test_labels.to(device)).sum().item()
accurate_test = acc / val_num
if accurate_test > best_acc:
best_acc = accurate_test
torch.save(net.state_dict(), save_path)
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, running_loss / step, acc / val_num))
print("Finished Training")
学习碎碎念:
学习的道路上总会是遇到困难和麻烦的,不要心急,不要烦躁,一步一步的解决问题,慢慢来总会好的!















 2864
2864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









