






多模态——多功能的“小脑”
人类具有眼耳鼻舌身意,说明对于物理世界的充分感知和理解,是意识和智慧的来源。而传统AI更多的是被动观测,主要是“看”(计算机视觉)和“读”(文本NLP),这就使得智能体Agent缺乏对外部环境的通用感知能力。
多模态大模型,可以积累和分析2D/3D视觉、LiDAR激光、Voice声音等多维信息,基于真实交互,为具身大模型积累高质量数据,深度理解并转化为机器指令,来控制机器人的行为。有了感知能力更丰富的“小脑”,具身智能自然也就能更好地理解物理世界。
具身智能——精准决策和执行的“躯干”
传统的机器人训练往往采取离线模式,一旦遇到训练环境中没有出现过的问题,就可能掉链子,需要收集数据再重新迭代优化,这个过程的效率很低,也减慢了具身智能在现实中落地的速度。
大模型时代,具身智能模型的训练与测试,与云服务相结合,可以在云上虚拟仿真场景下进行端到端的实时训练与测试,快速完成端侧迭代与开发,这就大大加速了具身智能体的进化速度。
具身智能体在模拟出来的场景中无数次地尝试、学习、反馈、迭代,积累对物理世界的深度理解,产生大量交互数据,再通过与真实环境的不断交互积累经验,全面提升在复杂世界的自动移动、复杂任务的泛化能力,展现在具身载体上,就是机器人可以更好地适应环境,更灵活地运用机械“躯干”来进行人机交互。
技术实现路线
目前,对具身智能的技术实践,主要以两种路线为主:
1. 以谷歌、伯克利等为代表的“未来派”,期望“一步到位”。
他们从具身智能的终极目标出发,希望从当下到终点,寻找一个端到端的技术路径,即给出一个大模型就能让机器人完成识别环境、分解任务、执行操作等所有工作,非常难,也非常有未来感。
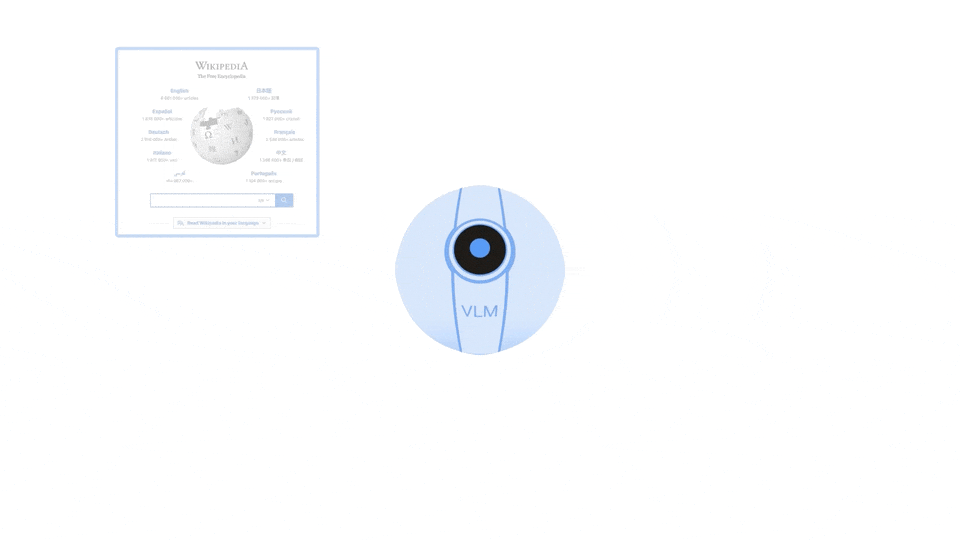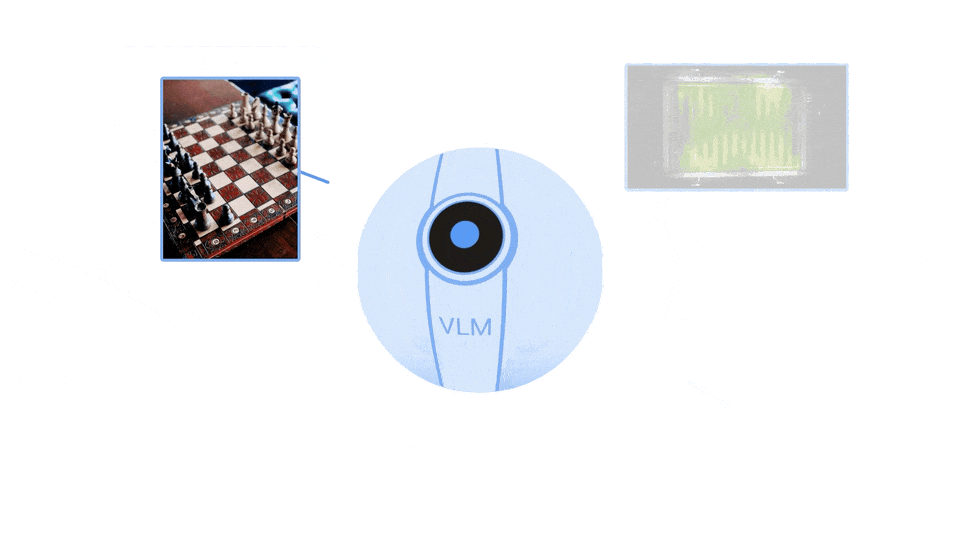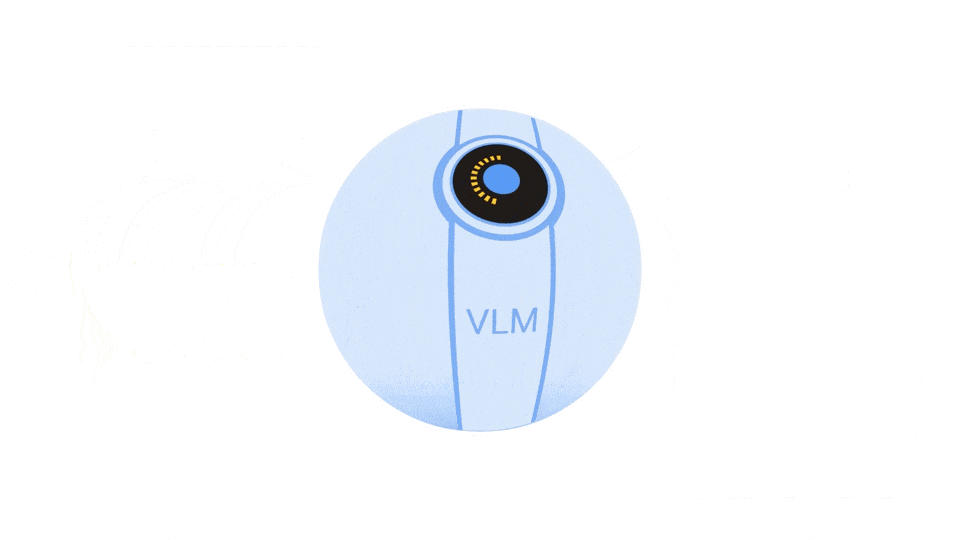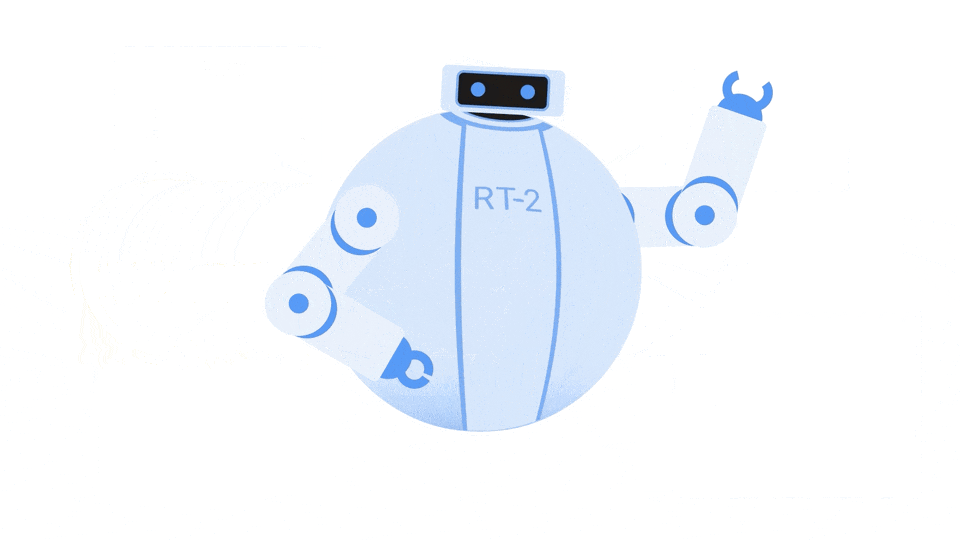
谷歌DeepMind提出的机器人模型Robotics Transformer 2(RT-2)就是一个全新的视觉-语言-动作(VLA)模型,它从网络和机器人数据中学习,并将这些知识转化为机器人控制的通用指令,同时保留了web-scale能力。即一个在web-scale数据上进行预训练的视觉-语言模型(VLM)正在从RT-1的机器人数据中学习,以成为可以控制机器人的视觉-语言-动作(VLA)模型,RT-2。
加州大学伯克利分校的LM Nav,则通过视觉模型、语言模型、视觉语言模型 CLIP等三个大模型,让机器人在不看地图的情况下按照语言指令到达目的地。Koushil Sreenath教授的工作,就是推动硬件本体、运动小脑、决策大脑三部分逐渐融合,让各种四足、双足,以及人形机器人在真实世界中灵活地运动。
2. 以英伟达及大量工业机器人厂商为代表的“务实派”,期望“马上见效”。
简单来说,就是不同任务通过不同模型来实现,分别让机器人学习概念并指挥行动,把所有的指令分解执行,通过大模型来完成自动化调度和协作,比如语言大模型来学习对话、视觉大模型来识别地图、多模态大模型来完成肢体驱动。
这种方式虽然底层逻辑上看还是比较机械,不像人一样有综合智能,但成本和可行性上,能让具身智能更快落地。
















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











